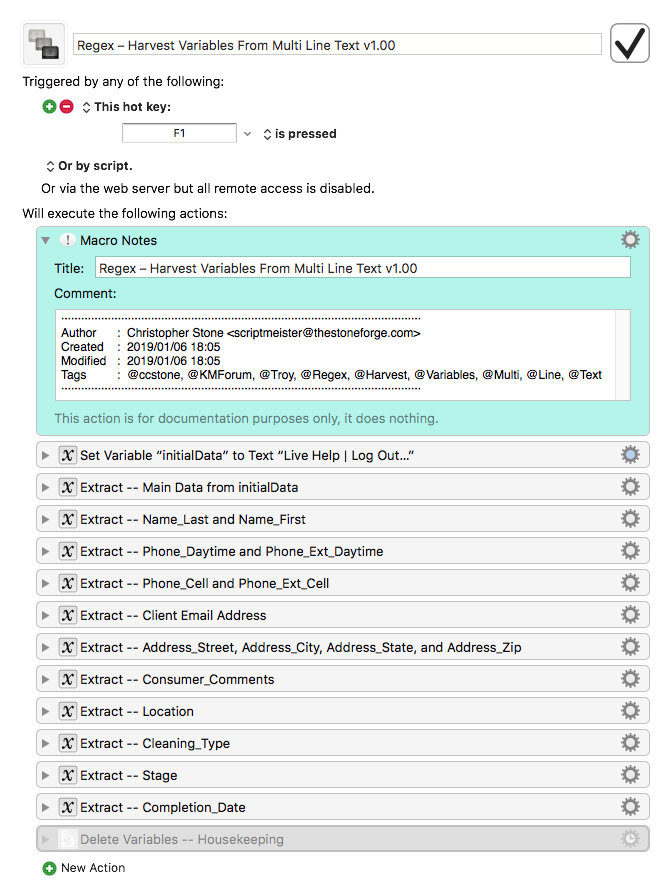
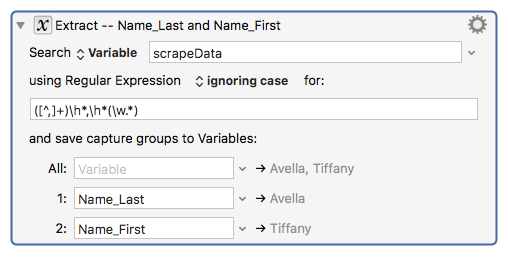
I realize more than a little help is needed to accomplish my goal.
Appreciate any input -
I'd like to 'pull' these variables from the text.
Name_First
Name_Last
Phone_Daytime
Phone_Cell
Phone_Ext_Daytime
Phone_Ext_Cell
Client_Email
Address_Street (the full line after the text 'Print this lead')
Address_City
Address_State
Address_Zip
Detail_Consumer_Comments
Detail_Location
Detail_Cleaning_Type
Detail_Stage
Detail_Completion_Date
The example text will always be in the middle of a long string of text but will always be preceded by:
Expand
Set Status
(I also have attached the complete block of 'master' text if that is of help)
TestDataFor KM.rtf.zip (2.3 KB)
Here is the example text:
Expand
Set Status
Avertta, Tammy
Daytime
(929) 295-4774 ext. 1047
Cell
(929) 295-4774 ext. 1048
Messages
Rate this lead
Print this lead
213 Maple Ave
New Hampton, NY 10958
Map
DetailsEmailNotes & RemindersHistory
Clean House Interior (Maid Service)
Job #: 131584913
Additional HomeAdvisor Pros Matched: 2
Service Description
Consumer Comments:
In need of kitchen, bathrooms, living room and dining rooms cleaned. Just the upstairs which include 3 bedrooms, 2 baths, living room, dining room, kitchen, steps and landing
What kind of location is this?:
Home/Residence
Cleaning Type Needed:
Recurring Service
Request Stage:
Planning & Budgeting
Desired Completion Date:
1 - 2 weeks