On the clipboard I have this: _Subject_ Study Notes _Date_
The placeholder names are delimited by underscores.
So, first I need to extract a list of placeholder names.
Then present to the user the name so the user can provide the value.
Then, replace the placeholder name, including delimiters, with the values.
I would like to have a pattern/solution that works with any number of placeholders.
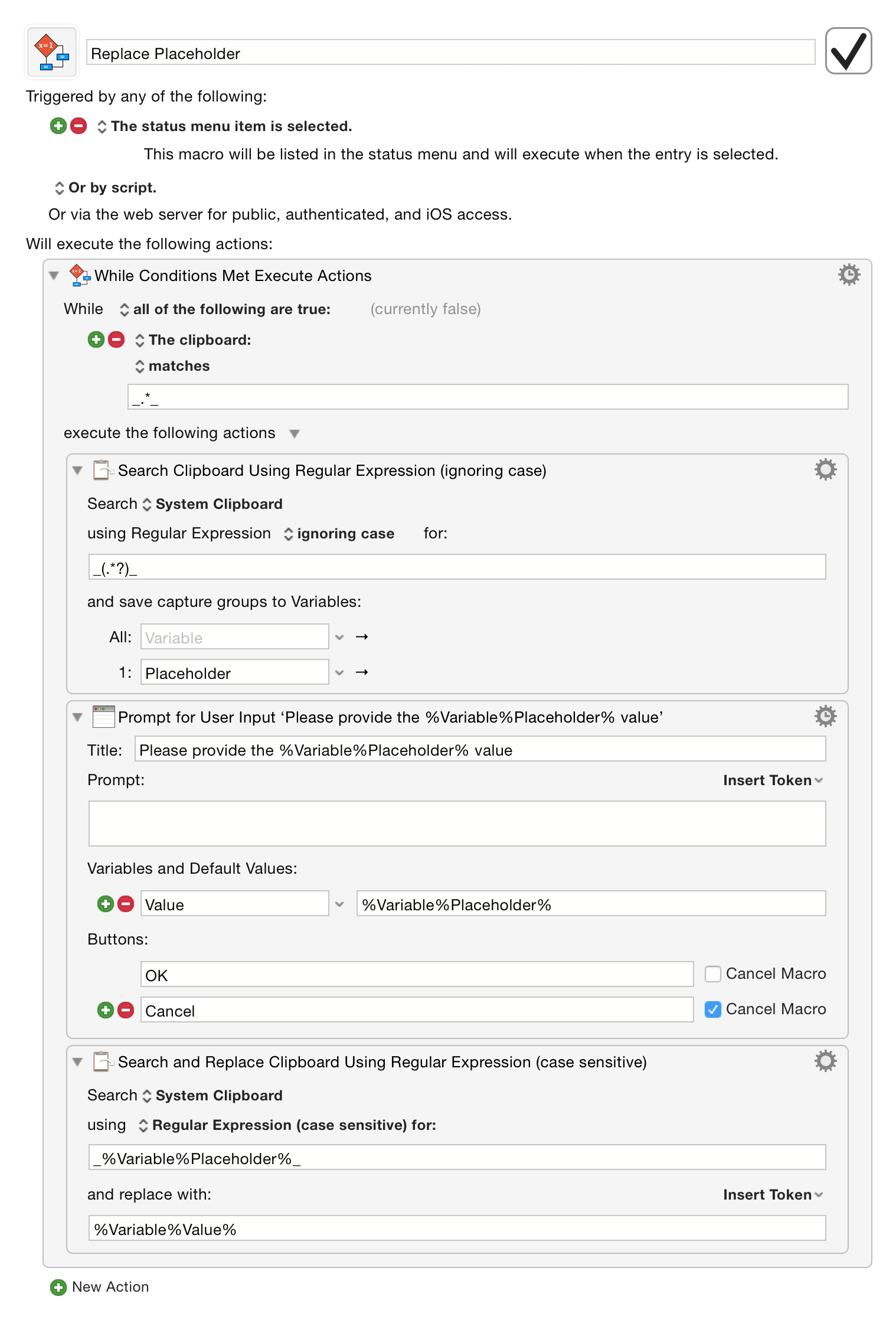
I have this RegEx pattern, but in KM it only returns the first placeholder: _(.*?)_
Anyone have any suggestions, guidance?
Also, if the clipboard is rich text and I replace the placeholders, do they retain the rich text formatting when I paste?
Assuming you are happy to ask for each placeholder value in turn, then this is relatively straight forward. And yes, it will retain the rich text formatting because Search & Replace Clipboard retains the rich text of the clipboard.
If you want to ask for all placeholders at once, then you will have to construct a UI, either by using scripting to generate the XML for a Prompt For User Input action for Keyboard Maestro to execute, by using the Custom HTML Prompt action, or by using some other UI facility. Alternatively, you could perhaps provide for 2, 3 or 4 (or whatever) placeholders and use one of a set of Prompt For User Input actions to get close without resorting to a full blown UI generation.
You have been using Keyboard Maestro enough to know the answer to this.
Where do you go if you want to deal with a set of things? A set of files in a folder, a set of files in the Finder's selection, a set of lines in a file, etc?
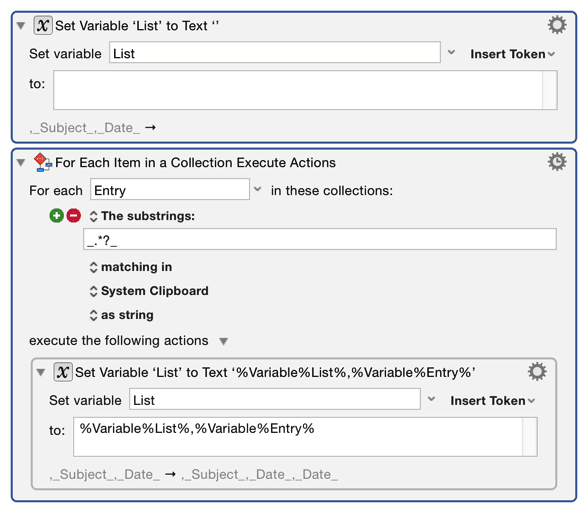
For Each Substrings in Clipboard
Removing the leading comma and the _ characters is left as an exercise.
Thanks, Peter.
"Should know" and "do know" are two different things.
Meanwhile, I figured out a JavaScript to gen the list:
var strSource = '_Subject_ Study Notes _Date_' // will be from clipboard
var lstPH = []
// console.log(strSource)
lstPH = getPlaceholders(strSource)
console.log (lstPH)
function getPlaceholders(str)
{
var regex = /_(.*?)_/g;
var result = [];
while (match = regex.exec(str))
{
result.push(match[1]);
}
return result;
// returns: Subject,Date
}
This is just a test. I need to add the KM variable for the clipboard, or just read it in JS.
and if, as an experimental variant, you wanted to try mapping a function over an array (as an alternative to a loop), you could try String.match(regex) which (with a //g regex) returns an array of the string matches (rather than match objects).
The string matches would include the leading and trailing underscores, which would need to be trimmed:
function placeHolders(str) {
return str.match(/_(.*?)_/g).map(
function (x) {
return x.slice(1, -1);
}
)
}
var strSource = '_Subject_ Study Notes _Date_',
lstPH = placeHolders(strSource);
console.log(lstPH)
Thanks for the alternative approach, Rob. It's always good to see other ways of doing things.
Since you brought this method to our attention, would you mind sharing your thoughts on why one would select one approach over the other?
I don't see an obvious benefit to your approach, but that's probably just because I'm a JavaScript newbie. Additional work will be required since AFAIK JavaScript doesn't have a trim function. Not hard, but not trivial.
As always, I love to see your examples. I've learned a lot from them.
Preferring to use function mapping (map, [reduce] (https://developer.mozilla.org/en-US/docs/Web/JavaScript/Reference/Global_Objects/Array/Reduce) and forEach) rather than loops, and making a habit of minimising variable mutation makes little difference with brief scripts (this particular rewrite happens to be c. 30% faster, and perhaps just marginally shorter and easier to maintain, but that’s hardly relevant or of much value at this level of scale ).
When you’re putting together slightly more complex assemblies, however, functional expressions turn out to ‘compose’ more manageably than procedures, and avoiding variable mutations can yield a simpler and more manageable mental model, with lower bug counts.
(It’s surprising how many useful processes boil down to the pattern which JavaScript calls reduce and some other languages call fold, and it’s very helpful to have pre-existing functions which set the pattern up for you).
The "trim" function used in many languages removes one or more of the same character from the beginning and end of a string.
While your "slice()" does remove the underscores from the beginning/end, it does so by an entirely different approach of just removing the 1st and last character regardless of what the character is.
So to me, "slice" ≠ "trim" Slice is a way of extracting a substring from a string by position.
Peter, I'm sorry, but I still don't understand how "For Each" works.
I've read the KM docs/wiki, and tried to follow your example, but I just don't know how to translate a general RegEx expression tester to KM.
If you have detailed docs somewhere, please point me to them.
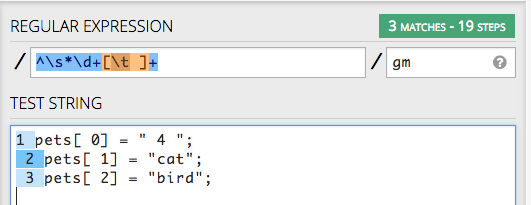
For example, I have this at Regex101.com, as you can see, it finds the characters I want removed.
My objective: Remove all forms of line number from each line.
This RegEx seems to work.
But I can't get it tdo work in KM.
Note the "/gm" at the end of the expression.
The "m" is critical here because it tells the RegEx engine to treat "^" as both start of string and start of line.
How to I use that in KM?
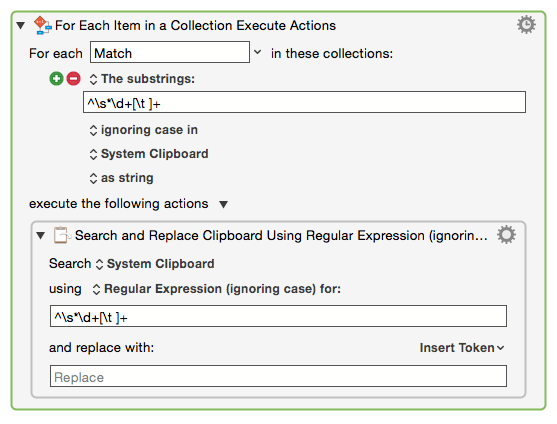
Here's the actions I have that don't work:
First, the clipboard BEFORE I run the macro:
Thanks for all of your gracious help. I really appreciate it.
For Each will let you find each match in the string. However you don't really want to do that, you seem like you want to do a (global) Search & Replace (Search & Replace is always global).
Multi-line can be turned on with (?m). So you want
Search and Replace with regular expression (?m)^\s*\d+\s+
I searched the wiki again for "regular expression" and found a number of hits.
But no page for it alone, and nothing on the (?m) modifier. Where can I find all of the switches/modifiers for KM RegEx?
I know you've told me that more times than you want to count.
Sorry.
I'm trying to learn so many things right now, that all work together, that some stuff gets shoved into the background, for a while.
KM7
JavaScript
JavaScript for Automation (JXA)
RegEx
. . .
With your approval, if you would like to setup a Regular Expressions page on the wiki, I'll start filling it out. Then at some point you and others can review and critique. Building this page will help me learn RegEx because I'm very careful to not post stuff I haven't tested/verified, and can cite sources if need be.
Thanks for being so helpful, and so patient with me.
 ).
).