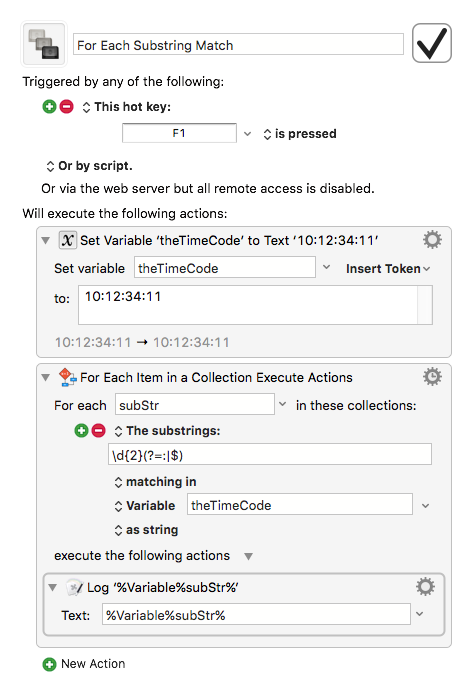
I continue to struggle with translating a RegEx pattern that works in the Online RegEx tool to one that works in the KM action for Search Using Regular Expression. BTW, I know this is easily done in JavaScript, but I need it to work in just KM.
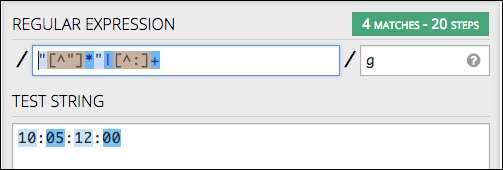
###How to I make this pattern work in KM: /"[^"]*"|[^:]+/g
For the string "10:05:12:00" it should return 4 match groups, but it shows only one.
ICU's split() function is similar in concept to Perl's – it will split a string into fields, with a regular expression match defining the field delimiters and the text between the delimiters being the field content itself.
Suppose you have a string of words separated by spaces
`UnicodeString s = “dog cat giraffe”;`
This code will extract the individual words from the string.
UErrorCode status = U_ZERO_ERROR;
RegexMatcher m(“\\s+”, 0, status);
const int maxWords = 10;
UnicodeString words[maxWords];
int numWords = m.split(s, words, maxWords, status);
After the split(),
> Variable value
> numWords 3
> words[0] “dog”
> words[1] “cat”
> words[2] “giraffe”
> words[3 to 9] “”
Thanks, Rob.
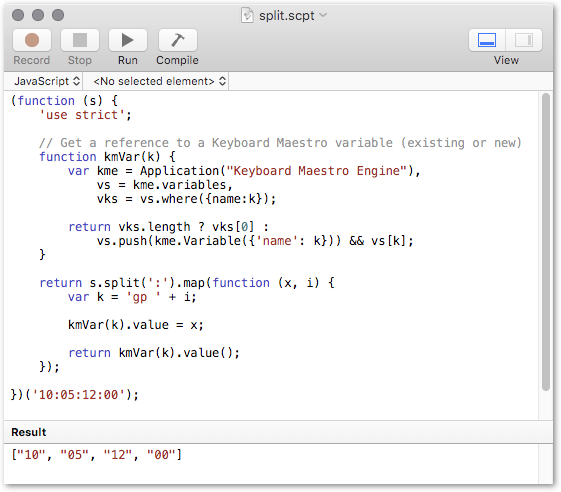
But as you've seen, many people are uncomfortable with scripts, especially changing them. So, I'm trying to come up with a KM only solution, where the KM user need only change a few settings/variable in KM to use.
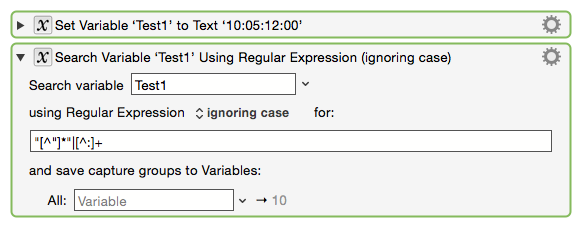
As others have noted, there are no groups in the pattern. You have added the "g" modifier to the end of the online version, and that means "global", which means repeat the search multiple times and return each match. That is, it returns a list of matches.
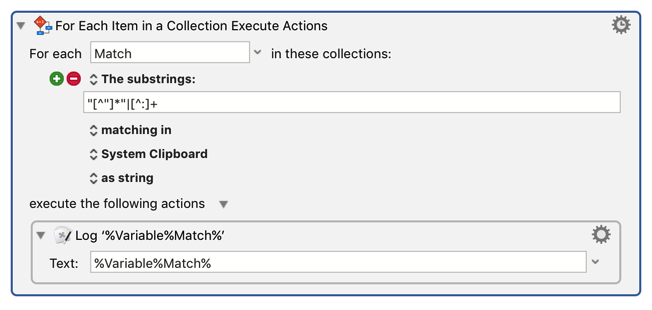
Keyboard Maestro users, being used to Keyboard Maestro's nice and orthogonal behaviour, should then immediately think of the For Each action, which is the action you use when you want to deal with a list of things.
In this case, the "Substrings In" collection, and the matching option will return each match.
Perhaps we should, but I, for one, do not immediately think of the KM For Each action.
Sorry Peter, but it is just not intuitive to me. Perhaps it is to others.
But let's use this as a teaching opportunity.
I still don't get how to use the For Each action, to extract each of the words into a different KM variable. It would be nice to have KM arrays, but it seems that to use them will always convert the array elements into numbers.
So if you will lay out how to do this, I'll update the KM wiki on RegEx to provide this as a great example. I would like to use the ":" as the word delimiter, and return all characters between them as a "word".
But I will say when using Keyboard Maestro, whenever you hit a problem that deals with a list of things, the For Each action is the pace to look. Keyboard Maestro has no other places where it iterates over a collection of items.
As I say, it is not intuitive - what solution to this sort of problem would be intuitive? I can't think of any.
Instead, once learnt, it is knowledge that applies across a range of problems within Keyboard Maestro - this is the best I know how to do…
Perhaps, if users are getting to it via a notion of splitting, it might be useful to make for each > substrings appear as a hit for searches on split by inserting the word split in a relevant wiki paragraph somewhere ?
OK, let's figure out how to add this to the wiki so that users who don't know KM or programming will know how to proceed. After all, the wiki is for those who don't know KM fully, right?
I guess what I'm saying is that, in the wiki, we need to connect RegEx with For Each, and provide some examples.
####Also, I want to make it easy for KM users to go from creating/testing a RegEx expression in a tool like RegEx101.com to KM.
So I just got this suggestion for creating multiple groups:
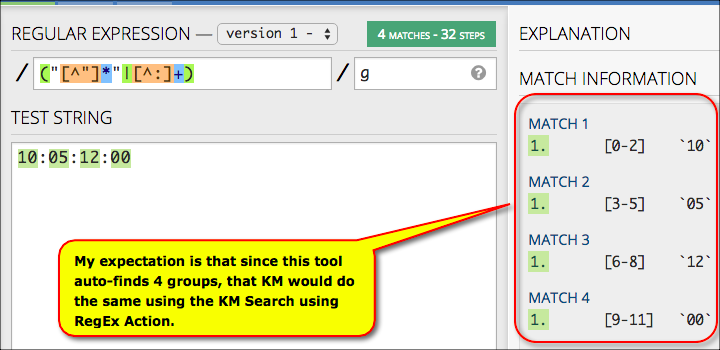
/("[^"]*"|[^:]+)/g
How to we instruct the KM user to implement this in KM?
Is the answer anytime a RegEx tool uses the global flag /g that the KM user needs to use the For Each Action?
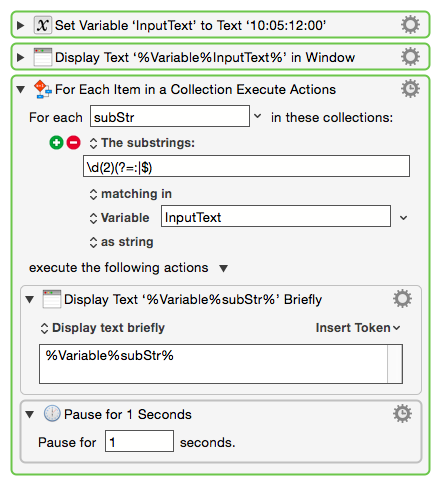
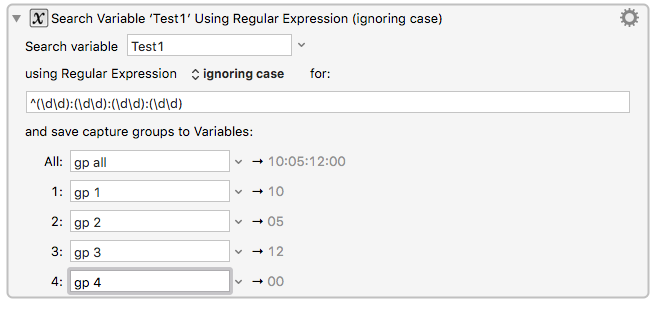
by \d(2) I would guess that you meant \d{2} or \d\d
( \d(2) looks for a digit followed by the number two, which it places in a distinct capture group.
The latter two look for two digits. \d\d may be quicker to parse and execute,
as well as quicker to write, and perhaps a bit less error-prone.)
As you found, quite easy for confusion about the difference between regex groups and regex matches to arise. If you do want to write learning materials, it would probably be good to make a quick edit to ensure that you are not using the terms interchangeably. (See yellow bubble above - the tool doesn't auto-find 4 groups, it finds four matches).
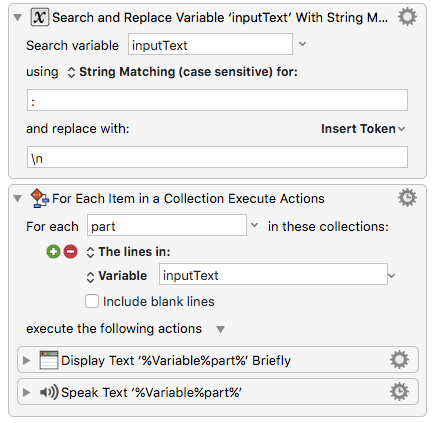
If simplicity is the goal, and splitting is the first metaphor that comes to mind, perhaps you can try a search and replace with : --> \n, and then loop through the resulting lines
 OR end-of-line as the substring-separator.
OR end-of-line as the substring-separator.