humph,... I've been circling all around it, but can't get it.
How can I parse the following into 3 matches using regex to capture between the pipes. I can make it not have a beginning and/or ending pipe if that makes it easier.
The following works testing it on regex101.com but doesn't work in the search with regex action in KM.
\s*[^|]+|([^|]+)|([^|]+)
thank you
The pipe character has its own meaning in regex, to match what is on either side of the pipe. The reason it appears to work on regex101 but not in KM is only because regex101 shows you all possible matches at once, whereas KM's Search With Regex action only returns the first of these "either" matches. If you want to the regex to parse the pipe as a standard character, each pipe needs to be escaped with a backslash so that it no longer has its own regex-specific meaning:
Nice, so that works with a predefined number of | characters, so I need to know in advance how many are in the string. that works for now, thanx.
Looking ahead, is there a way the regex could be dynamic so that if there were only 2 pipes it would get matches, or if there were 8 pipes it would match?
For a situation like that, I think you're better off with our old friend For Each and the substring collection that uses a single "match everything that's not a pipe" regex:
That clarified a lot for me. I appreciate the way you express things so systematically and clearly: a lot of you here do. I spent hours on this, since that 'pipe' character is in one of the initial examples Jeffrey Friel uses in his Regex book. I suspected it was different in Keyboard Maestro but at the same time, as a newbie, I make every other mistake one can make so I couldn't be sure. Is there a systematic list of where Keyboard Maestro differs from other systems or does one just have to find it out by trial and error?
That's kind of you to say, thank you. I'm afraid I'm not quite sure what to make of your question about KM differing from other systems, though. If you just mean whether KM's regex implementation differs from others, I believe it uses the same perl-compatible regular expression (PCRE) engine that many if not most other apps do, and so there shouldn't be many material differences. For the most part, any regex you write at regex101.com or in BBEdit should also work in KM. There's no list of ways that it differs, but you can always refer to the regex guides and reference linked to in the editor's Help menu to double check what KM supports.
Again, thanks for this clear reply @gglick . Yes that is exactly what I wanted to know. I had understood that to be the case but was wondering whether I had got it right.
If I'm not mistaken, KM uses the regular expression capabilities built-in to the Foundation framework via NSString and/or NSRegularExpression, which means it's not the PCRE but rather the ICU engine running things behind the scenes. They're pretty similar, but there are some differences. FWIW, though, I don't think I've ever run up against them in the patterns I've written so I they're pretty much effectively the same for most use cases.
ICU's Regular Expressions package provides applications with the ability to apply regular expression matching to Unicode string data. The regular expression patterns and behavior are based on Perl's regular expressions.
Thanks all of you; The upshot as I understood it from @gglick is that they should all pretty much work in the same way? Bear in mind that my own use is likely to remain quite simple so I don't like to impose on your time too much and that reply is sufficient and adequate for any practical purpose of mine. BUT
@JMichaelTX since we are on the topic; is $1 (a variable of some kind I guess?) part of regex or of the 'shell' or something else. That would clarify further for me. I looked all this up but I either have forgotten details of what I saw or didn't quite catch it properly.
I appreciate I am deeper in the weeds here than I need to be. It just interests me now. I am in fact going to have to avoid spending too much time on this as it is taking away from things I am supposed to be doing!
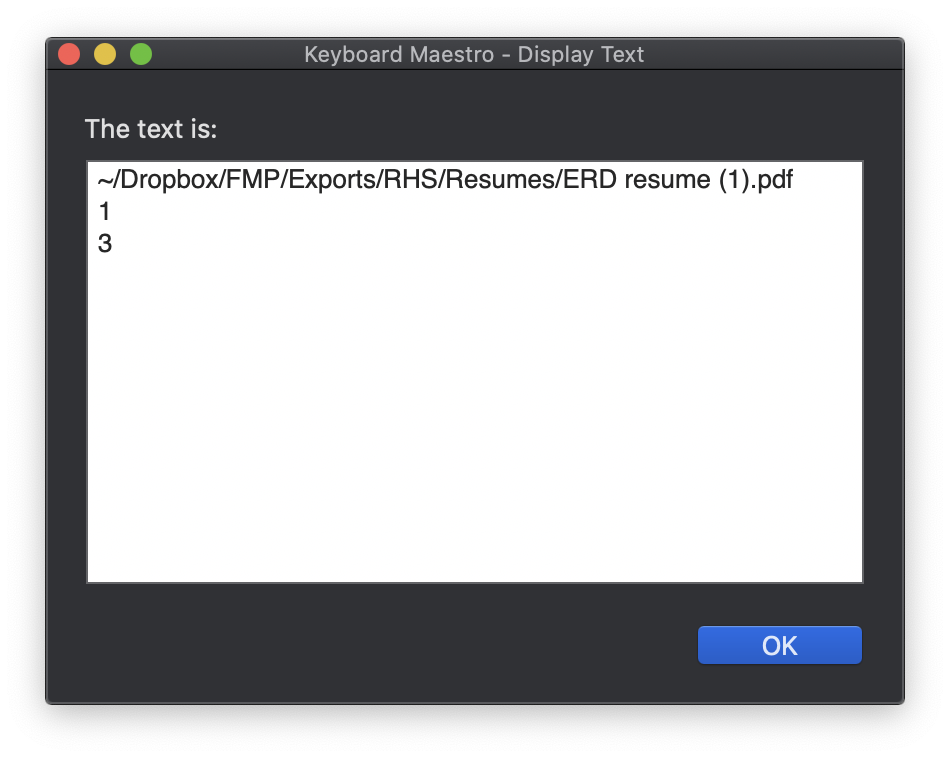
Anyway to amplify I got a result I didn't expect. I am just wondering how it 'worked' if you like, it is kind of idle speculation and I don't want to absorb people's time. It was this.
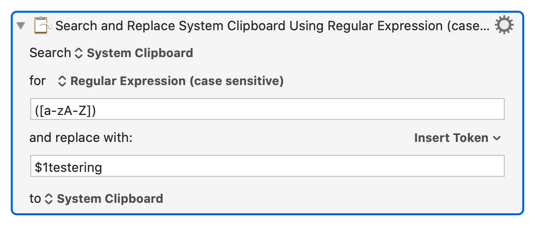
Now you guys will know what happened when I copied 'nationals' into it It was useful to know, but I don't know WHY it happened if you know what I mean. It is in fact potentially useful to me though totally accidental.
I don't need an anwer as to how to modify this to get the result I really wanted I can do that, but I want to know how that worked roughly and what happened. I can see of course that $1 somehow took as a value, each letter of the word the regex was applied to and then the text in the replacement box was appended over and over until the letters were exhausted. Is that the way to conceptualize this?
Thanks as always @JMichaelTX That clarified. That is enough of your time for today and thanks for the quick response while I am still here. Actually having the terminology helped a lot. I have tried that tutorial and now I see it more clearly, I kept missing that stuff, which was what I was looking for. Great!

 It was useful to know, but I don't know WHY it happened if you know what I mean. It is in fact potentially useful to me though totally accidental.
It was useful to know, but I don't know WHY it happened if you know what I mean. It is in fact potentially useful to me though totally accidental.