Bring page to front, keystroke ⌘A, copy to clipboard, filter clipboard to remove styles to target source
Google Chrome.
Bring page to front, keystroke ⌘A, copy to clipboard, filter clipboard to remove styles to target source
Google Chrome.
Don't do that.
Run this in a Execute a JavaScript in Front Browser action:
document.body.textContent
Better yet – find the correct element(s) and get the correct text on the first try.
-ccs
Thank you! I'll test this when I'm back at work on Monday.
The info I extract is only on screen when I'm on an active call, and many times while I'm on the call I'm not able to do must testing so some of these things take a long time to test and implement.
Also as you're well aware I've been working on learning my AppleScript and RegEx lately so I haven't delved into JavaScript at all...yet!
EDIT: Your simple reply made me think of another use case where this could come in VERY handy...and back down the rabbit hole I go 
Just some thoughts:
It's also possible that the invisible characters are filtered by the browsers during your posting or my browser's loading.
You may put it in a text action in KM and upload that to the forum.
If the original data has different numbers of invisible signs, it might be easier to use regex to filter those signs first before getting the targeted data.
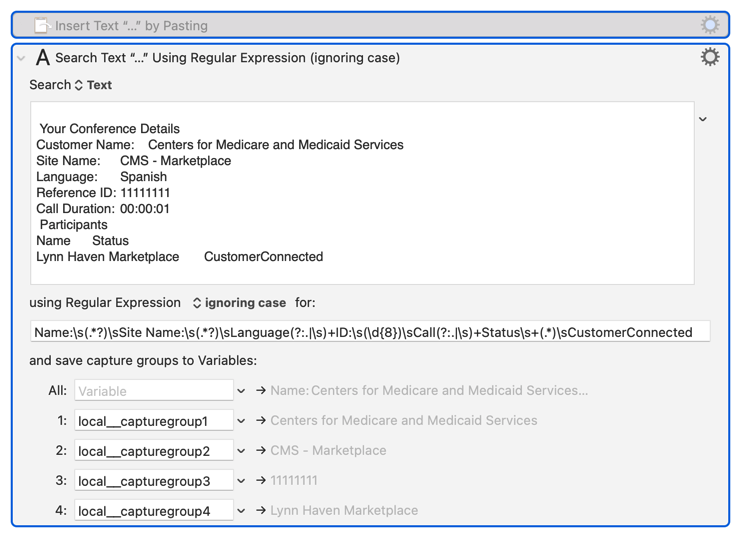
Use Google Chrome to save one or more examples in the following format for testing at your convenience:
![]()
-ccs
...and the rabbit hole gets deeper. Thank you, I'll make sure to do this Monday. As always, you're the man.
Here's the clipboard contents from my last call today, which I haven't touched except to remove anything before and after the relevant data.
It has only been filtered to remove styles, so all the white space should be intact.
VP contents filtered.kmmacros (1.3 KB)
I copied the text from your macro and I can still get what I wanted. Maybe my regex search string was filtered by the browser?
This is mine:
RegEx.kmmacros (2.4 KB)
Welp....I figured it out...and I don't know how it happened but somehow there was a line break at the end of the RegEx string that was making it fail. It works spectacularly now 
Thanks for your help and for troubleshooting it the last couple days too!
This is a very common occurrence, so I nearly always start out a data-extraction-sequence by trimming:
I've been writing regex filters for more than 25 years now, and I've seen more problems with irregular whitespace than you would believe.
RegEx Extract Client Data From Web Page v1.00.kmmacros (8.9 KB)
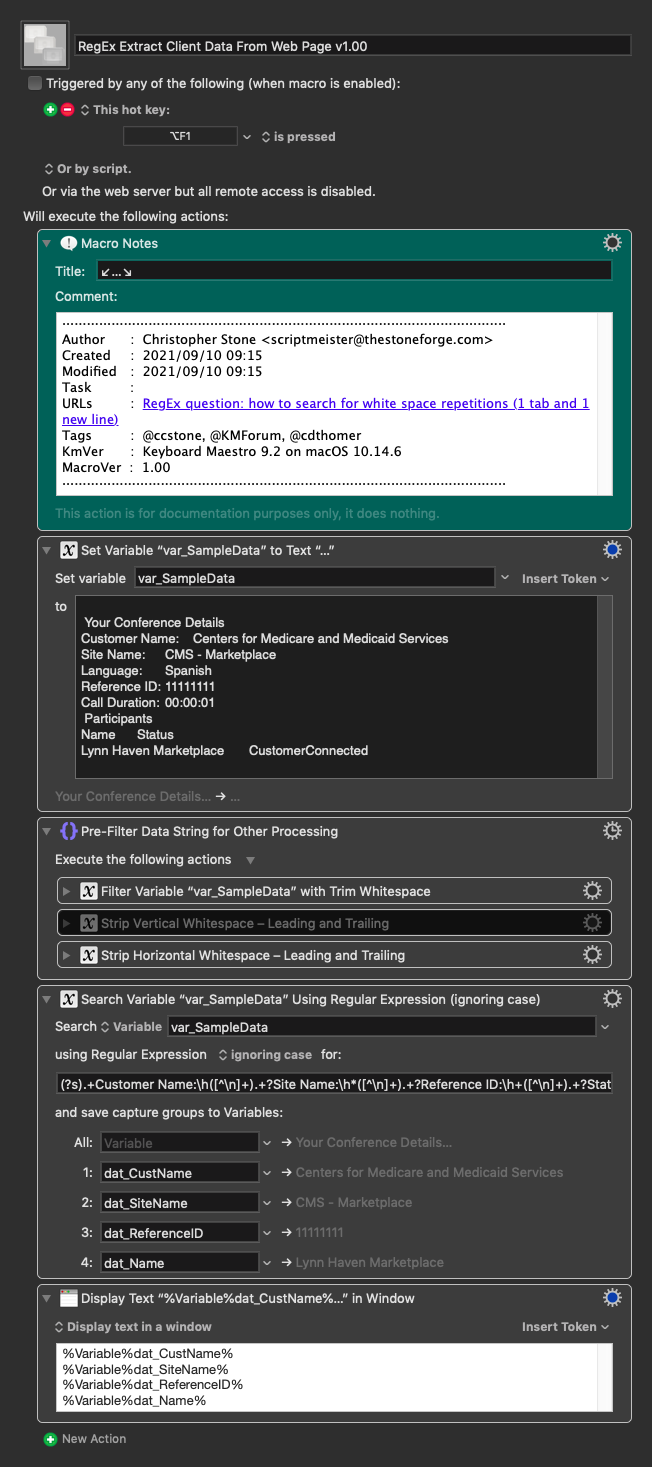
The disabled action in the pre-filter is a regex that does the same thing as the KM trim whitespace filter and was included as an example of same.
The regex was written haphazardly and could no doubt be made more efficient, but the purpose of the macro is more to demonstrate my general methodology for these kinds.
-Chris
P.S.
Kudos to @cdthomer – this is actually a case where using a lookbehind assertion isn't a bad idea – since the field names are fixed.
The trick here is to use the fixed field-name in the lookbehind, allow for foibles in the data with the forward-looking regex, and supply a proper capture-group for the actual data you want to extract.
Another useful technique for this kind of task is to remove the cruft you don't want, before trying to extract what you do want.
I'm also removing unwanted whitespace to make things more uniform.
A little sed and one line of awk to remove the trailing linefeed.
I really should have just used Perl for the whole thing, but I was in a Bash kind of mood this morning.
RegEx Extract Client Data From Web Page (Sed) v1.00.kmmacros (9.3 KB)
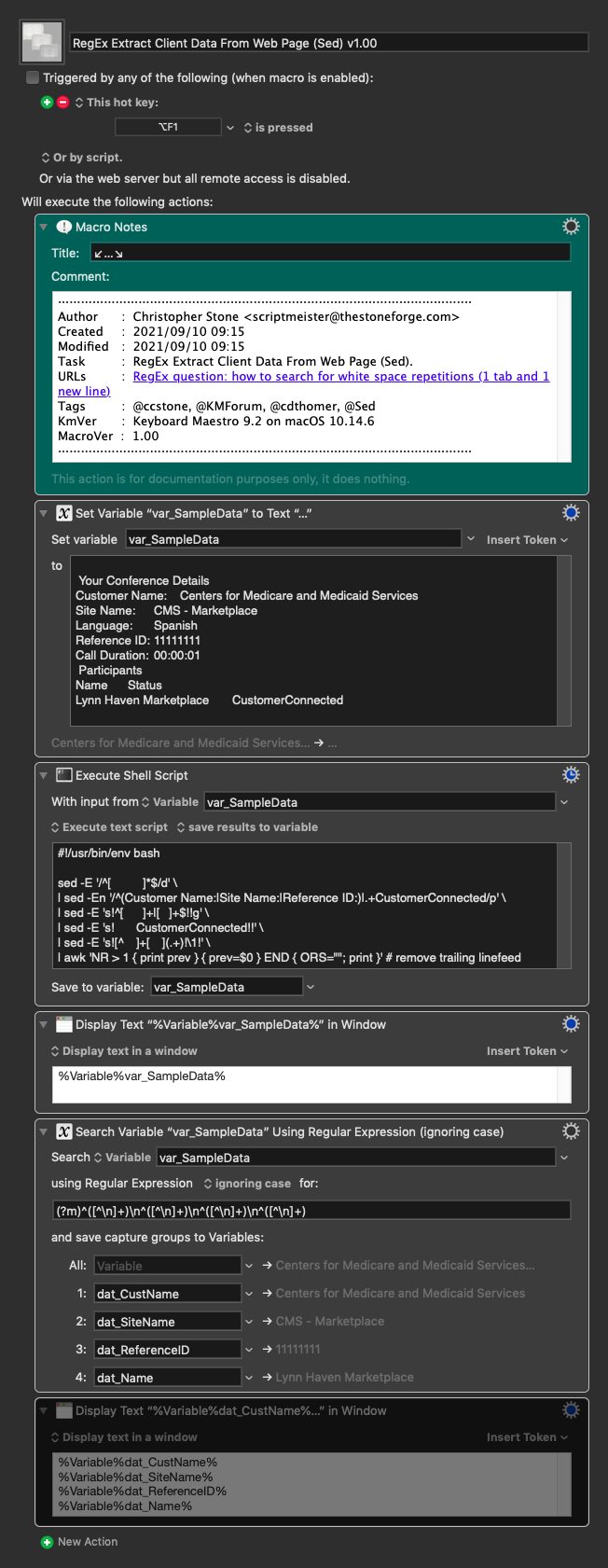
I used to do this kind of thing almost daily, until I learned a bit of JavaScript and how to extract data from web pages more efficiently.
-Chris
Thanks for sharing this. I'm gonna tuck this away for when I need to clean up the white space in future macros.
And I just discovered JMichaelTX's macro to get the value of a page's element using it's xPath and JavaScript...I was able to implement it successfully on one macro already and now it has me wanting to learn a little more about JavaScript to see how else I can use it.
Buutttt.......between AppleScript and RegEx I've already got my hands full so I might put JavaScript on the back burner for now
Don't go too far down that rabbit-hole.
Jim played with XPath for a while, until he discovered QuerySelector and never looked back.
QuerySelector has an easier to learn syntax than XPath.
-ccs
Make sure post #32 is visible in this thread, and run this JavaScript:
document.querySelector('#post_32').innerText
Probably true for simple cases, but the overlap is partial – querySelector can't handle the same range of contextual locations.
Very nice. It looks like I can get the selector path in the same way I get the XPath in the inspector tools, at least I was able to get the contents of other posts this way...
Am I correct?
Affirmative.
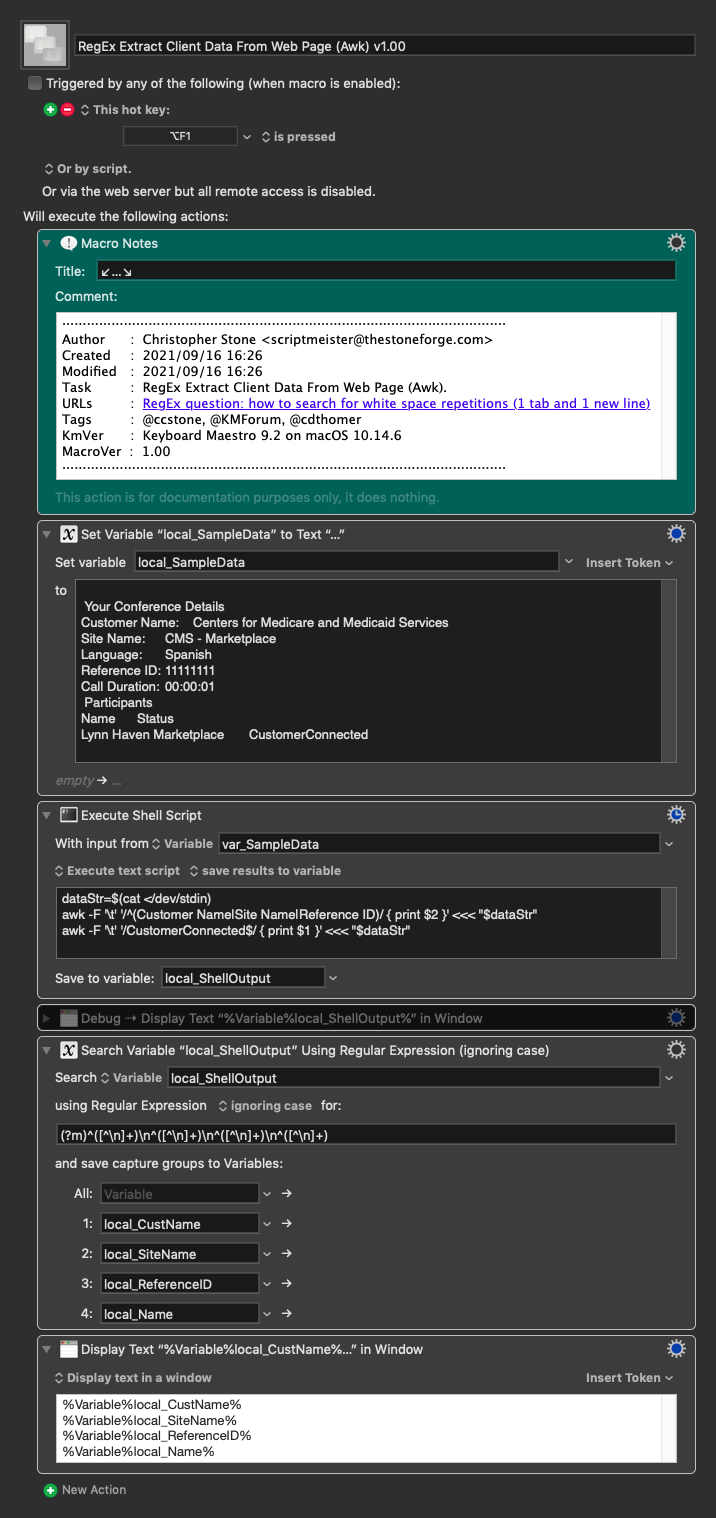
FWIW, if your data is always formatted with a leading label followed by a colon-tab as shown, you can skip RegEx and use awk to split the line at the colon.
The following action reads the data from KM variable "temp" and outputs to KM variable "txt1":
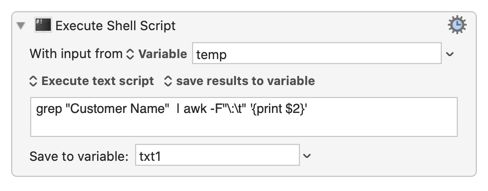
grep "Customer Name" | awk -F"\:\t" '{print $2}'
Annotation: grep filters the input data for a line containing "Customer Name" and pipes it to awk which uses a colon-tab combo as the field separator and prints field 2
Your other variables can be retrieved with these commands in separate shell script actions with the same input and different outputs:
grep "Site Name" | awk -F"\:\t" '{print $2}'
grep "Reference ID" | awk -F"\:\t" '{print $2}'
The last one requires a different separator since it is missing a colon and prints the first field:
grep "CustomerConnected" | awk -F"\t" '{print $1}'
This approach took 10 minutes to develop and should execute much faster than the RegEx version but it takes all the fun out of playing with regular expressions.
Very nice! While my current iteration of the RegEx works super fast, I'm always interested in learning alternative ways of doing things. I'll check this out when I get a few minutes in these coming days.
If you're going to use awk then there's no need to use grep, and since the data record is tab-delimited you can omit the colon separator.
RegEx Extract Client Data From Web Page (Awk) v1.00.kmmacros (9.3 KB)
You could of course use four Execute a Shell Script actions and omit the Search using Regular Expression action, and that would be more fault-tolerant.
-Chris