Howdy folks, I've been trying to improve on some of my RegEx and while I have been able to simplify a lot of them, I have come across one particular case that has me stumped. I tried searching for a RegEx forum but didn't come up with anything (perhaps somebody here knows of a RegEx specific forum they could direct me to as well).
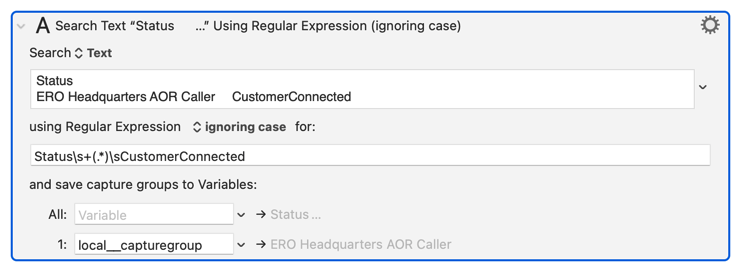
Below is a line from which I am trying to extract the words "ERO Headquarters AOR Caller" as well as the RegEx I use to get it. Obviously, this comes between the words "Status" and "CustomerConnected".
Status
ERO Headquarters AOR Caller CustomerConnected
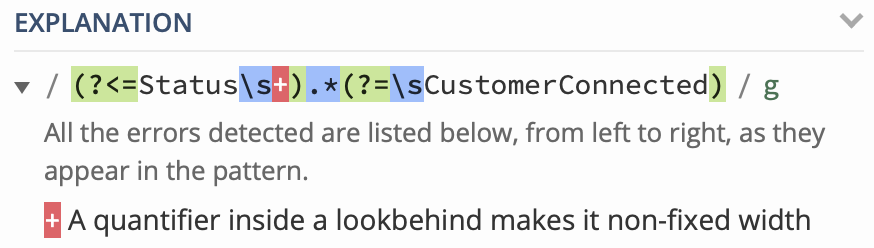
(?<=Status\s\s).*(?=\sCustomerConnected)
I had to put in \s twice because there is both a tab and new line after the word Status. I tried several combinations of \s* and the like to have it search for multiple cases of white space, but they never worked. What would be the proper way to write this so it looks for more than one instance of white space after the word "Status" so as to include both the tab and the new line?
EDIT: I should state that the RegEx I use works just fine...I just want to know how to simplify \s\s portion of it.
Those work...but I'm trying to avoid capturing the spaces preceding and following the string because then I would have to filter out those spaces in another action or else it would lead to extra lines in the end result. The way I was doing it before was by including the the words "Status" and "CustomerConnected" and then filtering them out in a subsequent action. I just want to simplify things and have one action to get the exact string I'm looking for.
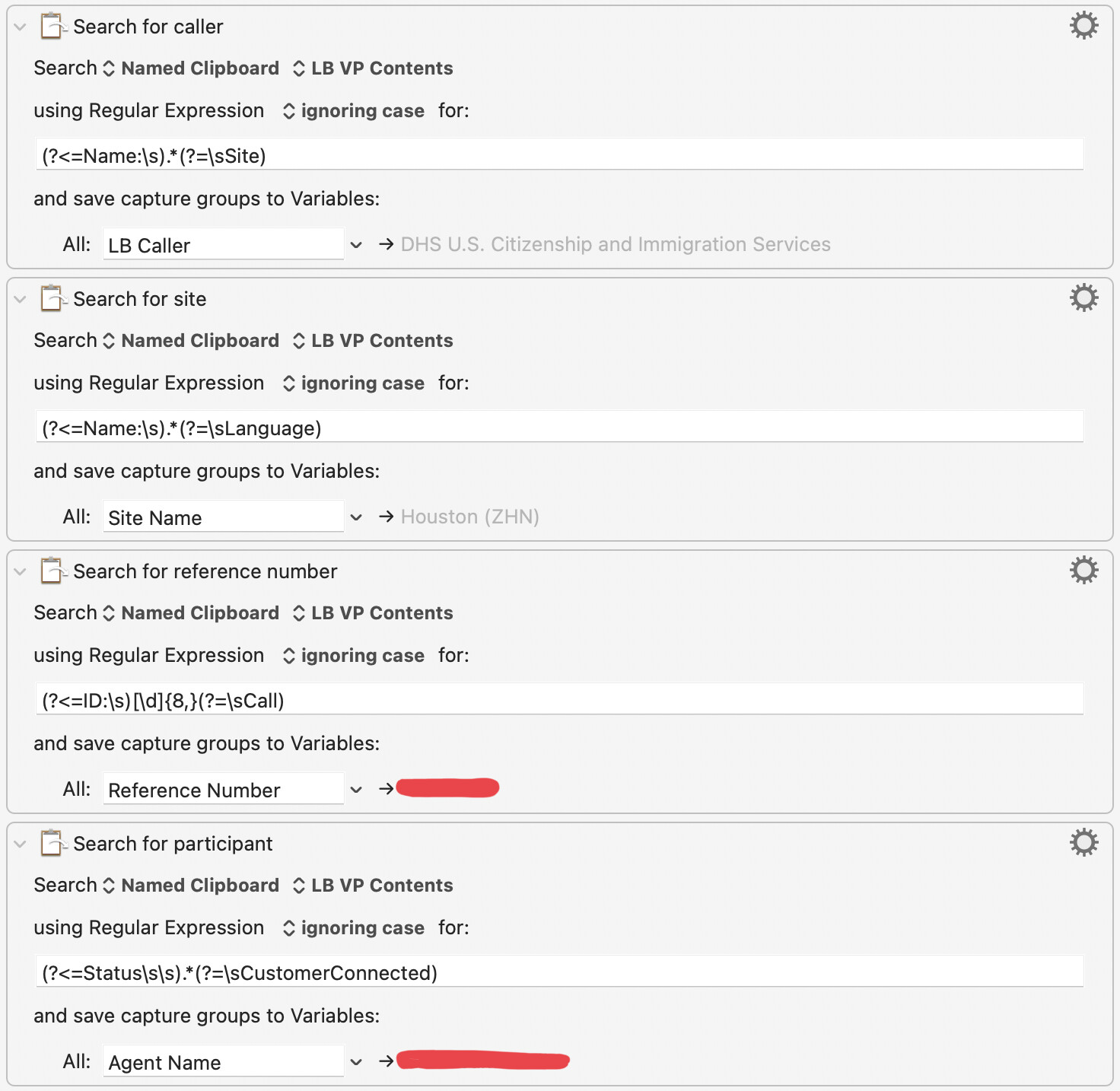
Thanks! I should look more into the capture groups, because this is actually just one of four pieces of information I need to extract from a page. Right now I have them setup the following way.
Ideally I would set it up to extract all that info in one shot, with a single action. But at least for now I have greatly streamlined it, going from literally 20 actions to only 4. So I'm making progress. I was just trying to understand why I was having trouble writing in a RegEx for multiple white spaces in the participant search. Thanks again for your help!
You just described what my wife has often accused me of...always wanting to refine something that already works
But you’re both very right...sometimes it's best to leave something alone once it works well enough. Thanks again for your help with AppleScript and RegEx!
It's possible to do multiple capture groups in one action, provided the text follows the same format. You will need to provide the relevant sample text block for test.
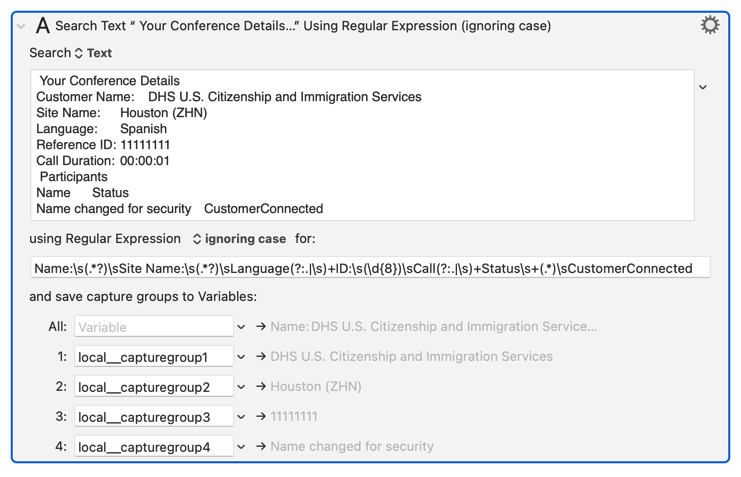
I think I'll follow Chris' (@ccstone) advice and leave the macro itself alone since it works quite well. BUT, I also want to learn some more so I've included the sample text block for you to take a look at.
Your Conference Details
Customer Name: DHS U.S. Citizenship and Immigration Services
Site Name: Houston (ZHN)
Language: Spanish
Reference ID: 11111111
Call Duration: 00:00:01
Participants
Name Status
Name changed for security CustomerConnected
I changed the reference ID and customer's name for security reasons, but they are still in the same format as what the actual text would read.
I need to extract the following info:
DHS U.S. Citizenship and Immigration Services
This name can be just one word or several as you can see.
Houston (ZHN)
This name can also be just one word or several.
11111111
Obviously that's not the real number, but it is always an 8-digit string.
Name changed for security
This is usually two or three words depending on if it's the actual persons name, or the name of their office.
So just for curiosity sake at this point (because why screw up a perfectly good macro I managed to reduce from 20 actions to 4? ) would there be a way to parse this information with a single action, and set each set of data to a separate variable?
The page's format is the same every single time...well, 98% of the time. For the other 2% I have 4 separate macros that can extract just one single item in case one of those items is missing (sometimes the participant's name is missing for example).
I must have messed up the formatting when I posted it, because using the action you built doesn’t return me any results. I’ll take a closer look at it tomorrow though and see what I can figure out.
Copy contents of page to system clipboard and then filtering to remove styles. But I have several copies saved in text files on my computer to test things with and I used one of those in a previous post. It must have gotten corrupted somehow; likely I deleted some white space character or the like.