I'm sure there is a Regex expression to do this and someone will supply if for you.
In the meantime, I was wondering if you could extract the "1910" from a string that includes a birth date in the form you have quoted using just native Keyboard Maestro Actions.
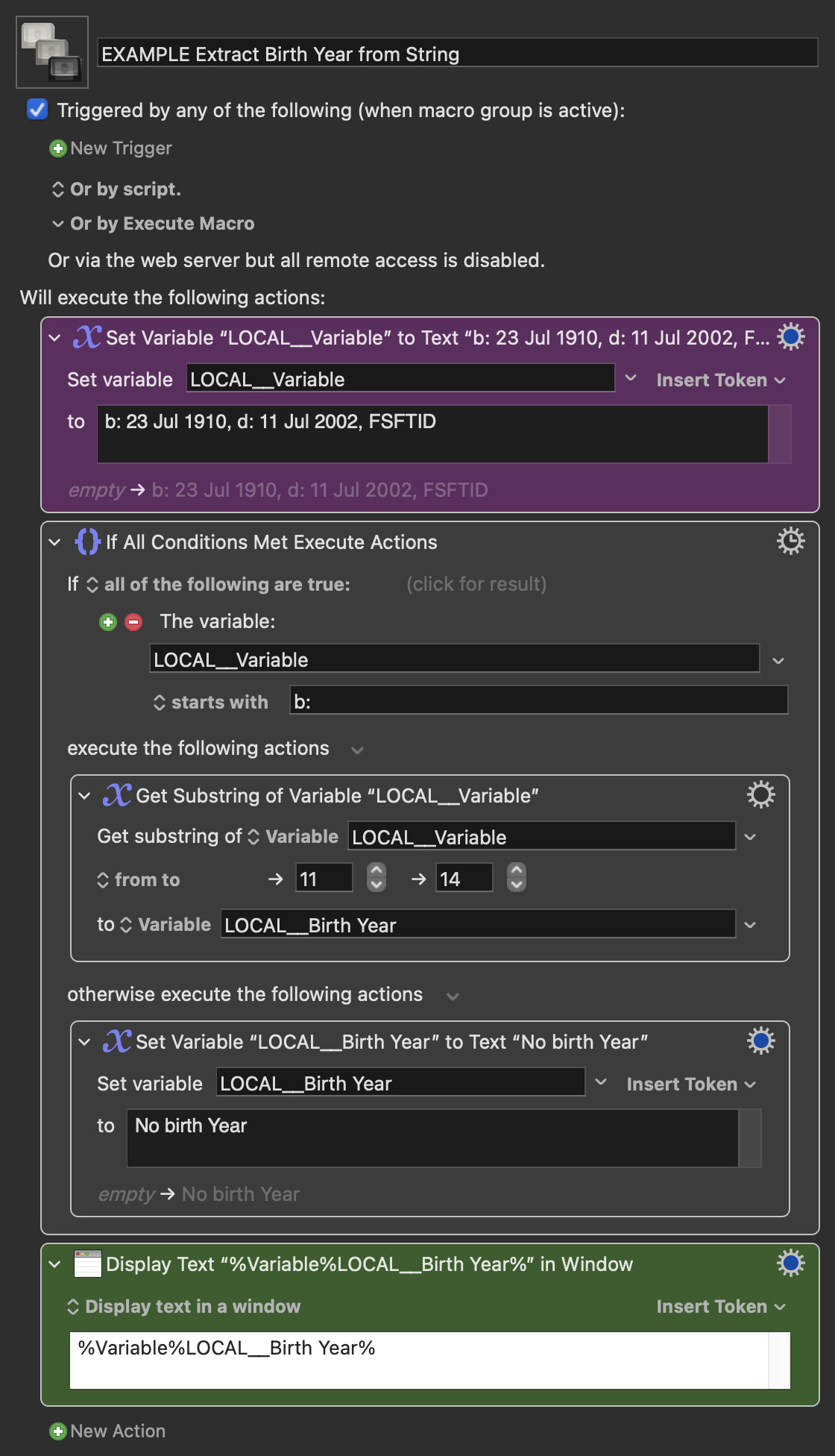
If the logic is that the string will contain a birth date if it starts with "b:" then the year will be characters 11 to 14. If the string does not start with "b:" then presumably it doesn't contain a birth date. Anyway, this is the kind of logic you can use with Keyboard Maestro directly.
(Of course I might be making a wrong assumption about "b:" not being in the string when the birth date is missing as you did not give an example string when the birth year is missing. But the point is that native Keyboard Maestro Actions can achieve quite a lot and are easy to understand and edit.)
But there are other patterns which are as good and may be better, depending on your "bad" strings' contents, eg (\d{2,4}), [^F] (2-4 digits then a comma then a space then anything but an "F") or b:[^:]+ (\d{2,4}) ("b:" then one or more non-colons, then a space and 2-4 digits), and that's without getting into complicated look-aheads etc.
The first thing to grasp about Regular Expressions is that they seldom the provide the quickest or most solid approach.
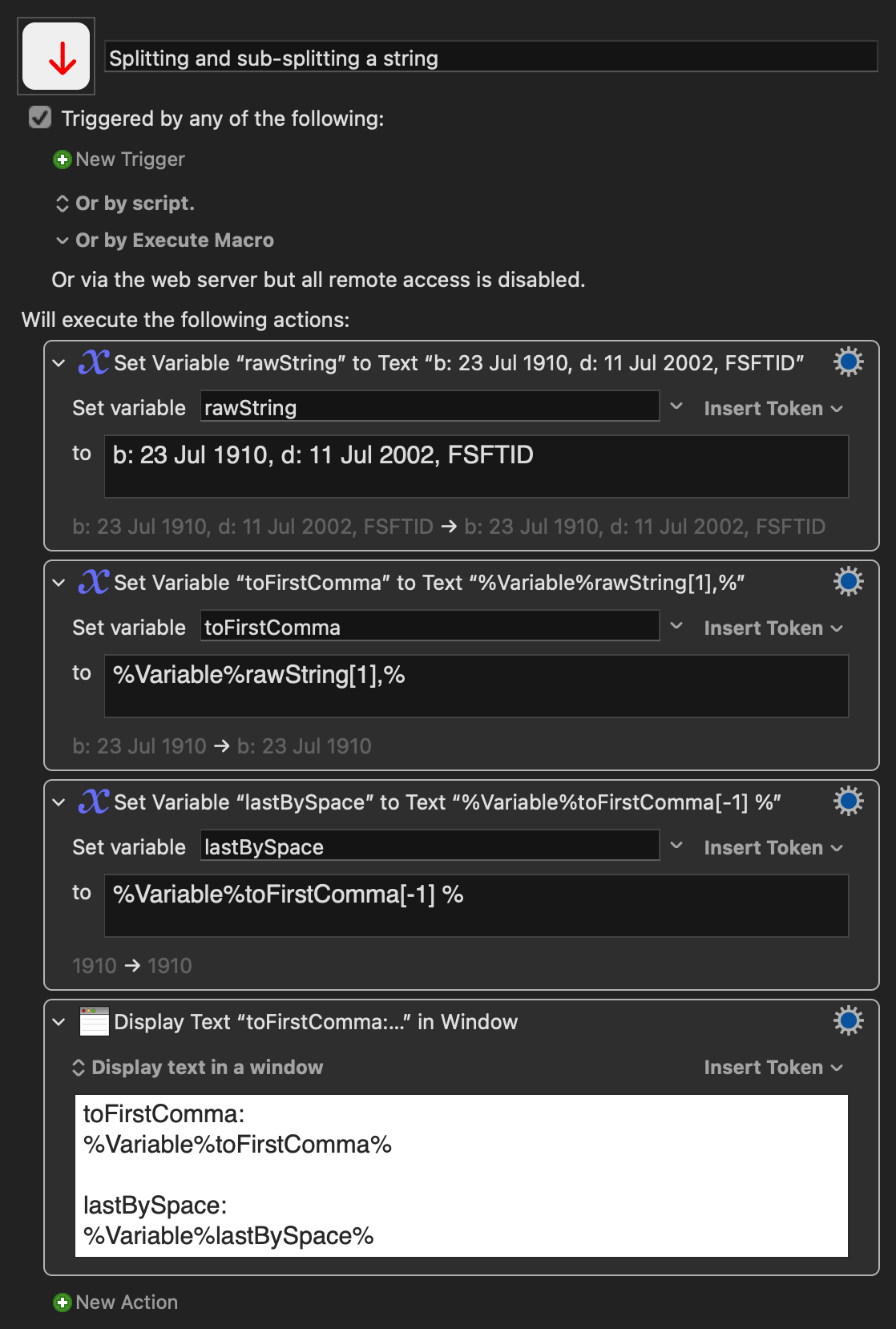
Just splitting, for example, is often conceptually simpler. You can split any Keyboard Maestro variable into an 'array' of parts with any delimiter you like.
I believe the saying is "I had a problem, which I solved with a Regular Expression. Now I have two problems."
But here we don't have enough information to decide which method is best -- we know the year might be missing (so your macro needs a check for that. What's the best way to "is a number?" in KM?) but we don't know what other formats, if any, the DoB may be presented in -- "b: Dec 23, 1910," would fail a comma-split but is fine with the regexs.
(Also, OP was specifically asking about regex and may have just given an example for learning purposes. Whilst an important lesson is "It's often better to use something other than a regex", it isn't the only lesson.)
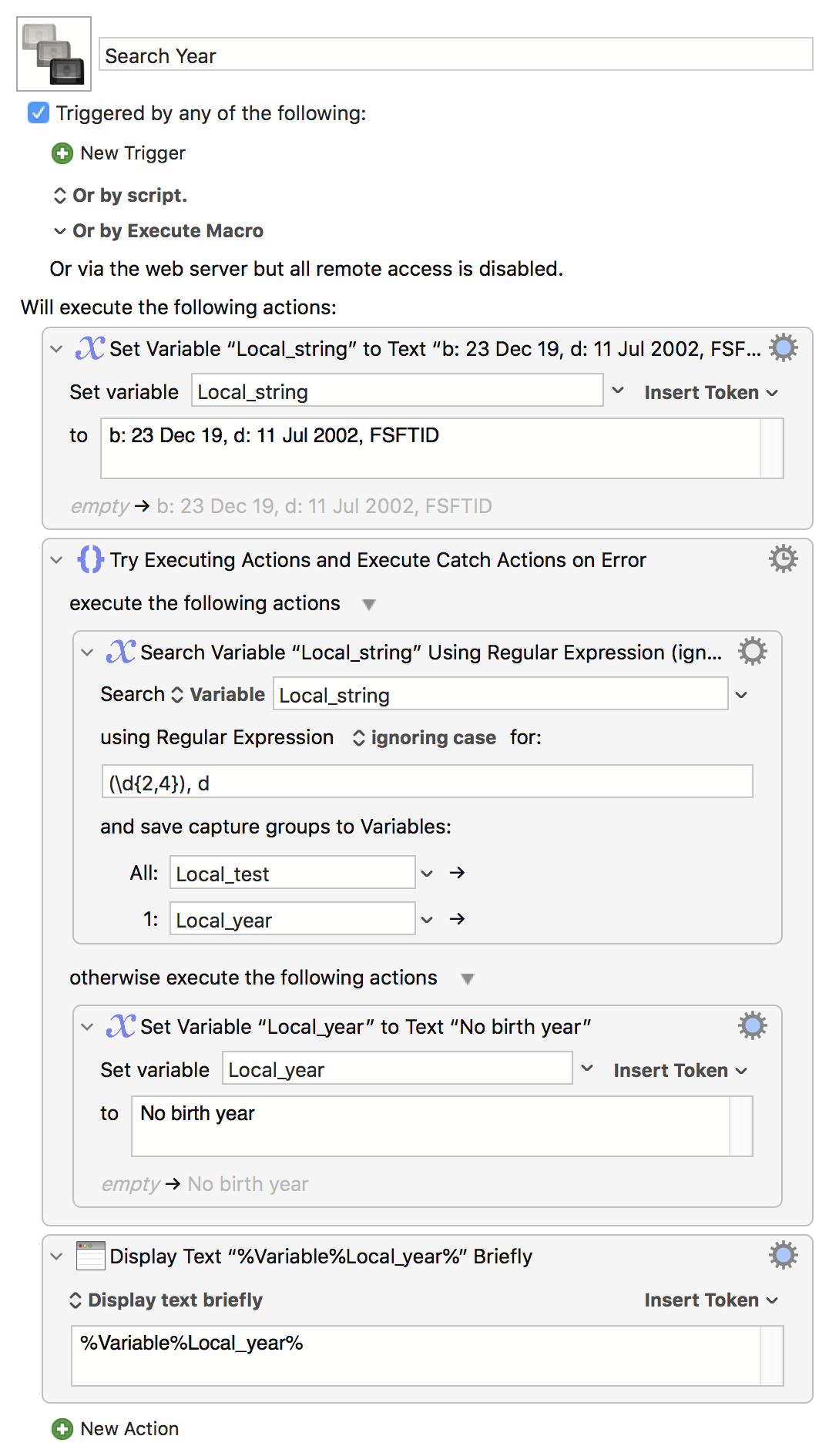
\d{4}, d This did the trick except it also selects the , d and gives me this 1990, d as a result where I only want 1990. How would I remove the , d. I know could write another line of code to remove them but I would like to only use one line of code.
Is there a and maybe && that could be used to have 2 Rexeg expressions in one line?
I think you missed out the parentheses -- (\d{4}), d, which puts the four-digit year into the first capture group (the "1:" variable line in the action).
But take @ComplexPoint's comments to heart -- do you need a regex, or will string splitting work?
Yes there are other ways of doing it using just KBM but I am trying to learn how to use Regex. By using Regex I can run it in an Apple Script, java script, java, python without much changes.
Not natively (in case you didn't already know that). There are things like the Satimage OSAX, but don't forget that as a KM user you have access to KME's search and replace functionality -- including regex.
set theString to "b: 23 Jul 1910, d: 11 Jul 2002, FSFTID"
tell application "Keyboard Maestro Engine"
set theResult to search theString for ".*(\\d{4}), d.*" replace "$1" with regex
end tell
return theResult
This is my first time looking at this -- I couldn't quickly see a way to search and return the found pattern rather than search and replace everything with the found pattern, which is why the regex is different.
But @ComplexPoint's comments still stand -- if you've a relatively well-defined input it's often easier and more comprehensible to use a languages's text-split and array functions. Again in AppleScript:
set theString to "b: 23 Jul 1910, d: 11 Jul 2002, FSFTID"
set {oldTIDs, AppleScript's text item delimiters} to {AppleScript's text item delimiters, ","}
set theResult to word -1 of text item 1 of theString
set AppleScript's text item delimiters to oldTIDs
try
(0 + theResult)
return theResult
on error
return "No birth year given"
end try
Bravo! As @ComplexPoint points out, there are other ways to grab a substring, but I bless the day I discovered regular expressions. They are all about pattern matching and @Nige_S has eloquently matched your pattern efficiently (as you discovered).
It turns out people are not quite so good at pattern matching as they think they are. They like to embrace sea-to-shining-sea patterns when what anyone really wants is the simplest expression of the pattern. The most concise, as @Nige_S delivered.
So don't be deterred from learning about these magical incantations that can bend a string to your will.
Splitting in AppleScript, might look, for example, like:
on run
set haystack to "b: 23 Jul 1910, d: 11 Jul 2002, FSFTID"
set beforeComma to item 1 of splitOn(",", haystack)
item -1 of splitOn(space, beforeComma)
--> "1910"
end run
------------------------- GENERIC ------------------------
-- splitOn :: String -> String -> [String]
on splitOn(pat, src)
set {dlm, my text item delimiters} to ¬
{my text item delimiters, pat}
set xs to text items of src
set my text item delimiters to dlm
return xs
end splitOn
And to be fair, if you:
import the Foundation classes
use the foreign function interface to ObjC
escape certain characters in the Regular Expression string, and
adjust between zero-based ObjC indexes, and 1-based AppleScript indexes,
then you can also find your way towards a Regex route in AppleScript:
use framework "Foundation"
on run
set haystack to "b: 23 Jul 1910, d: 11 Jul 2002, FSFTID"
set regexNeedle to "\\d{4},"
set matches to regexMatches(regexNeedle, haystack)
if {} is matches then
"pattern not found: " & regexNeedle
else
tell item 1 of matches
set patternStart to its location
set patternLength to its |length|
end tell
-- Zero-based ObjC matches, but 1-based AppleScript indexes
text (1 + patternStart) thru ((patternStart - 1) + patternLength) of haystack
end if
end run
-- regexMatches :: Regex String -> String -> [[String]]
on regexMatches(strRegex, strHay)
set ca to current application
-- NSNotFound handling and and High Sierra workaround due to @sl1974
set NSNotFound to a reference to 9.22337203685477E+18 + 5807
set oRgx to ca's NSRegularExpression's regularExpressionWithPattern:strRegex ¬
options:((ca's NSRegularExpressionAnchorsMatchLines as integer)) ¬
|error|:(missing value)
set oString to ca's NSString's stringWithString:strHay
script matchString
on |λ|(m)
script rangeMatched
on |λ|(i)
tell (m's rangeAtIndex:i)
set intFrom to its location
if NSNotFound ≠ intFrom then
text (intFrom + 1) thru (intFrom + (its |length|)) of strHay
else
missing value
end if
end tell
end |λ|
end script
end |λ|
end script
script asRange
on |λ|(x)
range() of x
end |λ|
end script
map(asRange, (oRgx's matchesInString:oString ¬
options:0 range:{location:0, |length|:oString's |length|()}) as list)
end regexMatches
-- mReturn :: First-class m => (a -> b) -> m (a -> b)
on mReturn(f)
-- 2nd class handler function lifted into 1st class script wrapper.
if script is class of f then
f
else
script
property |λ| : f
end script
end if
end mReturn
-- map :: (a -> b) -> [a] -> [b]
on map(f, xs)
-- The list obtained by applying f
-- to each element of xs.
tell mReturn(f)
set lng to length of xs
set lst to {}
repeat with i from 1 to lng
set end of lst to |λ|(item i of xs, i, xs)
end repeat
return lst
end tell
end map
( Though by now, of course, the new problem of getting your Regex to work is already an order of magnitude larger than the original problem of finding a substring at some position between some delimiters )
In JavaScript and Python etc, a split function is built in.