Hey Bill,
Don't bang your head against the wall (without making progress) for more than 30 to 60 minutes at a time. We don't need no dain brammage! 
There are many ways to complete this particular task.
RegEx ⇢ Search Variable for First 3 Words.kmmacros (2.9 KB)
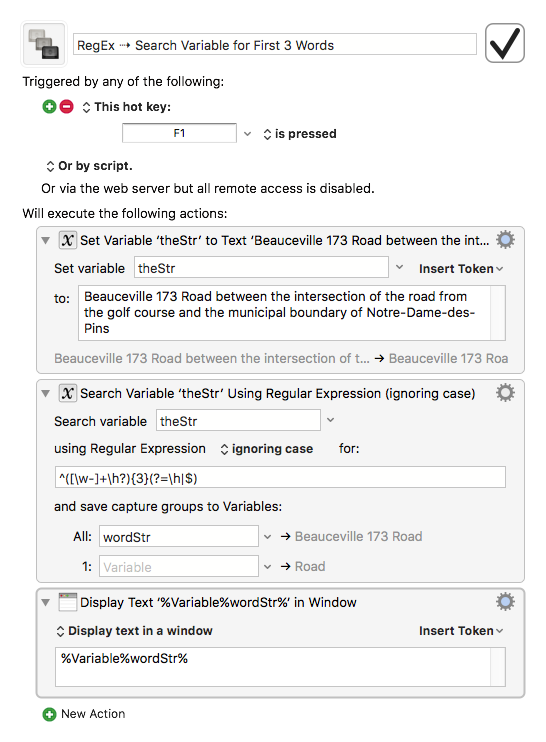
I've used a little more complex regular expression than JM's to limit the found-string to word-characters and hyphens.
(This method can be problematic if you have punctuation in words.)
I've also used the horizontal whitespace token and a Positive-Lookahead-Assertion to stop before the last appropriate space (or end-of-line).
Once you wrap your head around AppleScript's text item delimiters this kind of job is easily done with AppleScript.
set theStr to "Beauceville 173 Road between the intersection of the road from the golf course and the municipal boundary of Notre-Dame-des-Pins"
set AppleScript's text item delimiters to space
set breakStrIntoList to text items of theStr
set firstThreeWords to (items 1 thru 3 of breakStrIntoList) as text
By doing it this way I don't have to be concerned about punctuation or other strange characters in words.
I can do the same thing in awk quite easily, since it looks at lines as records and words as fields with horizontal-whitespace the default field separator.
A couple of ways to print the first three fields of a string with awk:
strVar='Beauceville 173 Road between the intersection of the road from the golf course and the municipal boundary of Notre-Dame-des-Pins'
# Super-simple awk — print fields 1, 2, & 3 with a space in between:
echo "$strVar" | awk '{ print $1" "$2" "$3}'
# Slightly more complex awk — set the output-field-separater to space — print with comma-notation to use the OFS.
echo "$strVar" | awk 'BEGIN {OFS=" "} {print $1,$2,$3}'
I'll do three more with AppleScript and the Satimage.osax:
This script like the TIDs method splits the string on whitespace and then rejoins the first three words.
set theStr to "Beauceville 173 Road between the intersection of the road from the golf course and the municipal boundary of Notre-Dame-des-Pins"
set firstThreeWords to splittext theStr using "[[:blank:]]+" with regexp
if length of firstThreeWords ≥ 3 then
set firstThreeWords to items 1 thru 3 of firstThreeWords
set firstThreeWords to join firstThreeWords using space
end if
This method uses the Satimage.osax's regular expression support with an even more simple patttern:
set theStr to "Beauceville 173 Road between the intersection of the road from the golf course and the municipal boundary of Notre-Dame-des-Pins"
try
set theStr to find text "^\\S+ \\S+ \\S+" in theStr with regexp and string result
on error
set theStr to false
end try
Since the Satimage.osax's regex flavor is a bit different than Keyboard Maestro's I have to write my original pattern differently to work with it.
set theStr to "Beauceville 173 Road between the intersection of the road from the golf course and the municipal boundary of Notre-Dame-des-Pins"
try
set theStr to find text "^(\\S+[[:blank:]]?){3}(?=[[:blank:]]|$)" in theStr with regexp and string result
on error
set theStr to false
end try
-Chris