Hi and welcome to the forums!
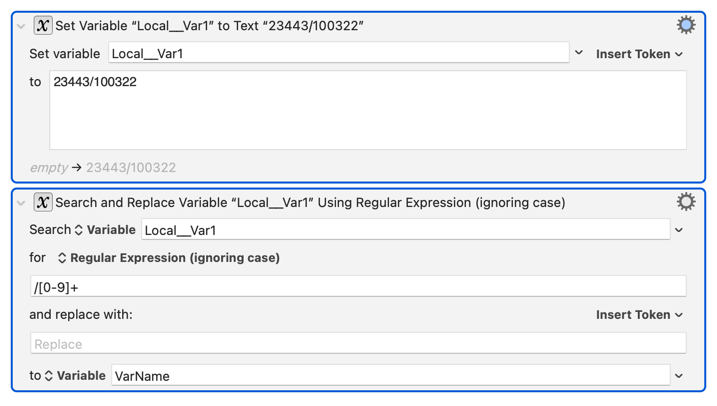
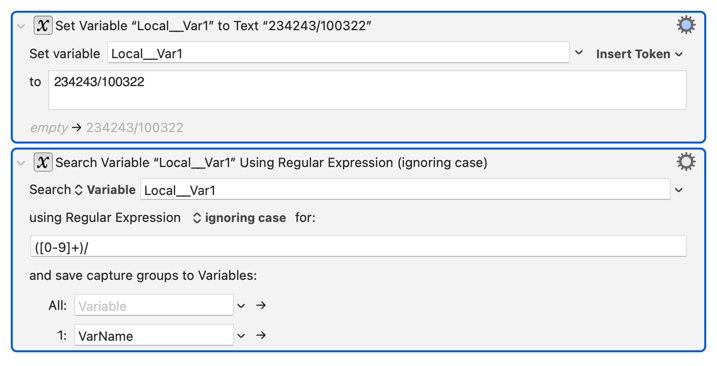
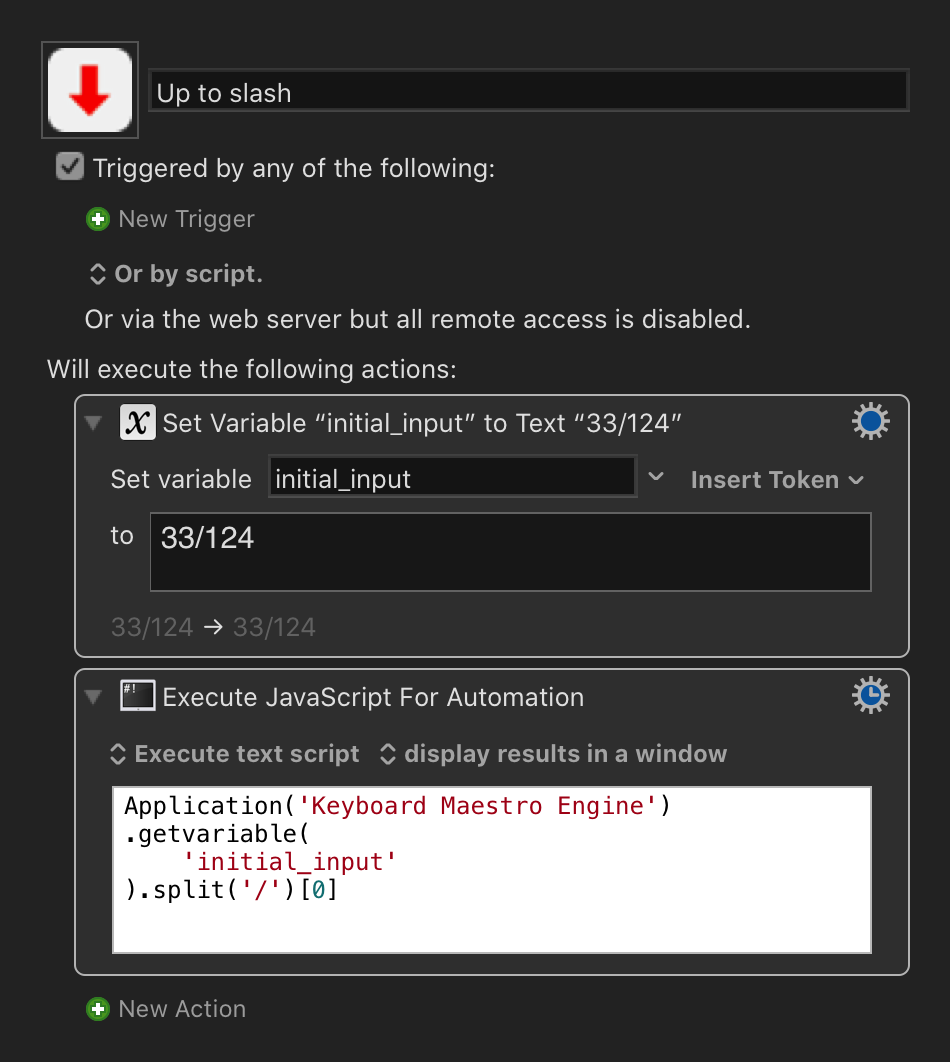
I only know how to do this with a shell script. Someone else who knows more about working with regex in Keyboard Maestro might have a more “native” answer, and hopefully, they will add their answer as well.
(Note: it took me so long to write this, someone else did exactly that. Oh well. I’ve learned something from them, and will leave this here in case anyone else finds it interesting.)
Here's what I came up with:
Take Input Remove Slash and Everything After It.kmmacros (2.6 KB)
(You can click on that  to download it, and then double-click to import it into Keyboard Maestro.)
to download it, and then double-click to import it into Keyboard Maestro.)
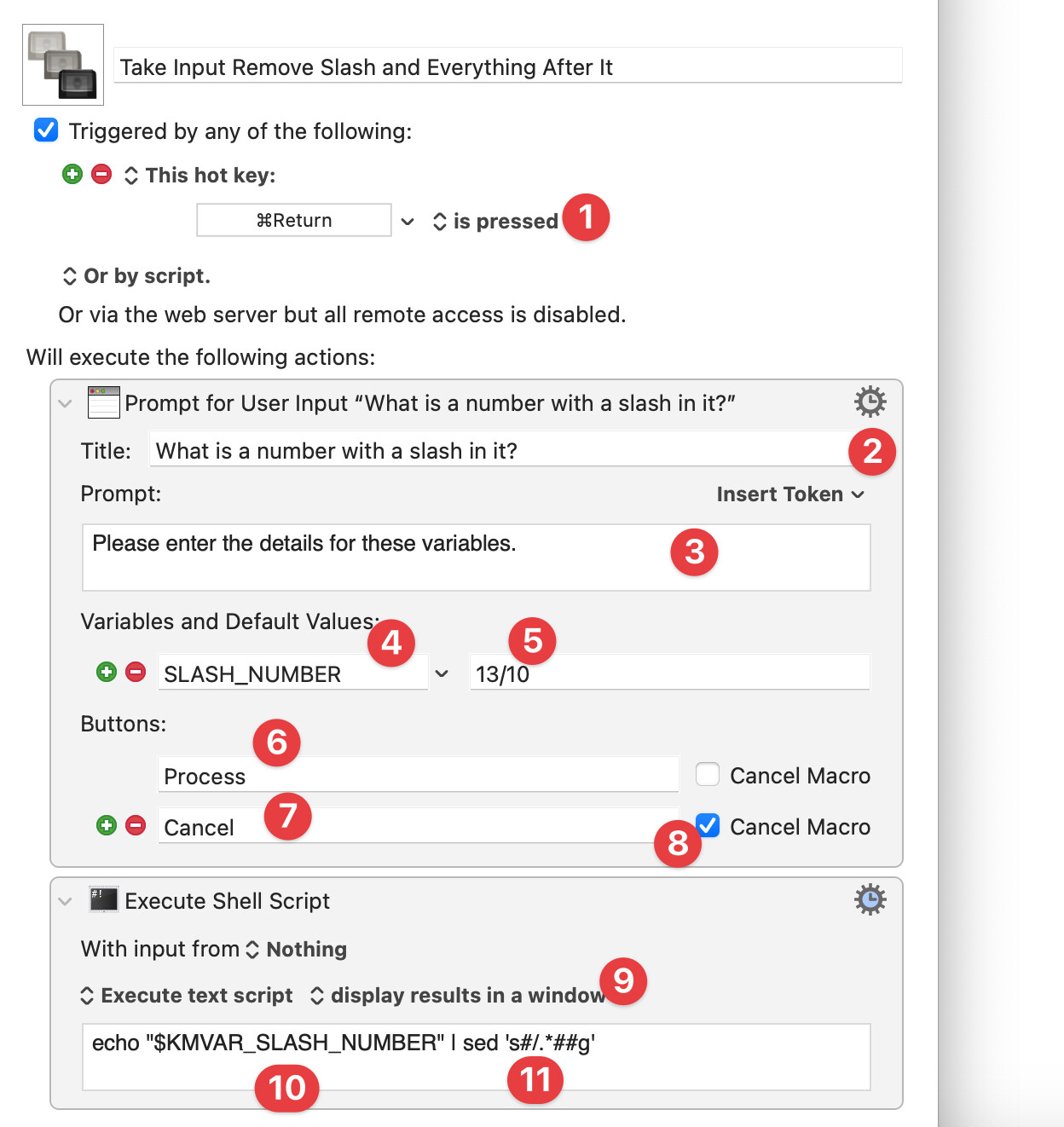
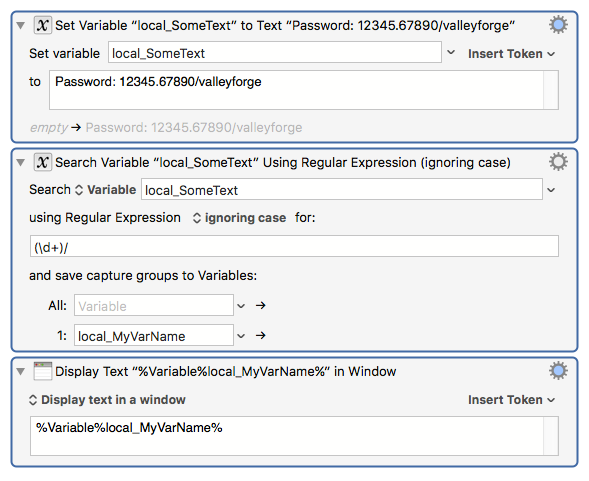
Here's a screenshot with some numbers we'll use as reference points:
(I’m not sure of your experience level with Keyboard Maestro so I’m going to write this assuming none. Please take no offense, even if you don’t need all of this explained, someone else might.)
-
This is the keyboard shortcut that I assigned, which is the command key plus return. Obviously, feel free to edit that.
-
This will be the title of the input window which is shown to the user.
-
This will be the sub-title of the input window
-
This is the variable name. It can be whatever you like. I use ALL_CAPS with an _ between words, but you can use whatever you prefer.
-
This is the default value. It is probably best to leave this blank, but I wanted to be able to show how it works even for someone who wasn't sure what it was going.
-
This is the text that will be shown on the “Yes, Go Ahead, Do It” button
-
This is the text that will be shown on the “No, on second thought, don’t do it” button.
-
With this option set, if someone chooses #7, it will cancel the macro
-
You can click here to show other things you can do with the result, including saving it to the clipboard (useful) or saving it to another Keyboard Maestro variable (also useful). The option I've chosen is less useful, except for the purposes of this exercise.
-
When using a Keyboard Maestro variable in a shell script, there are two important things to remember:
- Be sure to add
$KMVAR_ as a prefix before the variable name
- ALWAYS ALWAYS ALWAYS put "double quotes" around the whole thing, so:
| Good and Bad Examples |
Outcomes |
| echo "$KMVAR_SLASH_NUMBER" |
 Good Good |
| echo '$KMVAR_SLASH_NUMBER' |
 Wrong - single quotes won't work Wrong - single quotes won't work |
| echo $KMVAR_SLASH_NUMBER |
Wrong - missing double quotes |
| echo "$SLASH_NUMBER" |
Wrong - missing $KMVAR_ prefix |
- This is where we process the variable using the Unix
sed command.
sed will take input and can either delete or change it before sending it to output. When you are doing these sorts of replacements in sed you use s at the beginning and g at the end. What you want to match and what you want to replace it with are separated by #
This gives us the basic format of this:
sed 's#A#B#g'
Where A represents what we want to match and B represents what we want to replace it with.
(Note that you do not have to use # you could use / or other punctuation, but for the sake of clarity, I like to use # unless I am trying to replace something that has a # in it.)
Examples
So, for example, if I did this:
echo apple orange grapefruit banana | sed 's#apple#PEACH#g'
the output would be
PEACH orange grapefruit banana
Notice that the word on the right has replaced the word on the left.
But it doesn't have to be complete words. If I wanted to change all of the a characters to A I could do this:
echo apple orange grapefruit banana | sed 's#a#A#g'
and get
Apple orAnge grApefruit bAnAnA
Note that all of the matching a characters are now A.
If I want to delete the word 'grapefruit' I would do this:
echo apple orange grapefruit banana | sed 's#grapefruit##g'
Notice that there is nothing on the right side. What we're basically saying is “replace the word grapefruit with nothing.”
This is what we would get:
apple orange banana
It may be difficult to see on a webpage, but there are two spaces between orange and banana because there was a space before and after the word grapefruit.
Getting Closer…
If I want to delete the word grapefruit and anything that comes after it then I would use a period and an asterisk: .* like this:
echo apple orange grapefruit banana | sed 's#grapefruit.*##g'
which means "replace the word 'grapefruit and anything that comes after it with nothing" which effectively deletes it.
So, for your example:
You want to take the input and delete / and anything after it, so you want to use /.*
echo "$KMVAR_SLASH_NUMBER" | sed 's#/.*##g'
Voilà!
I hope this helps or at least has been slightly amusing/educational