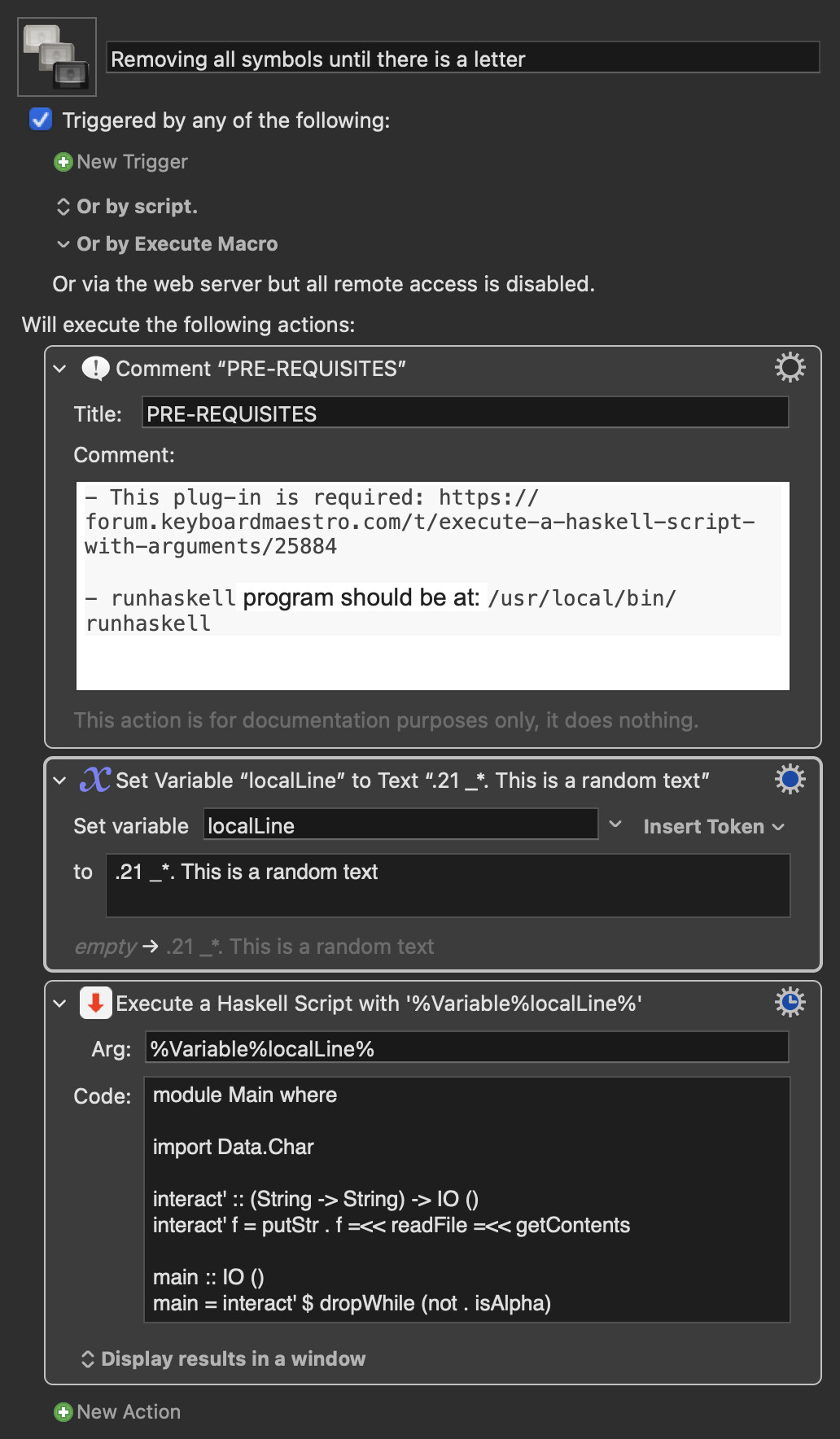
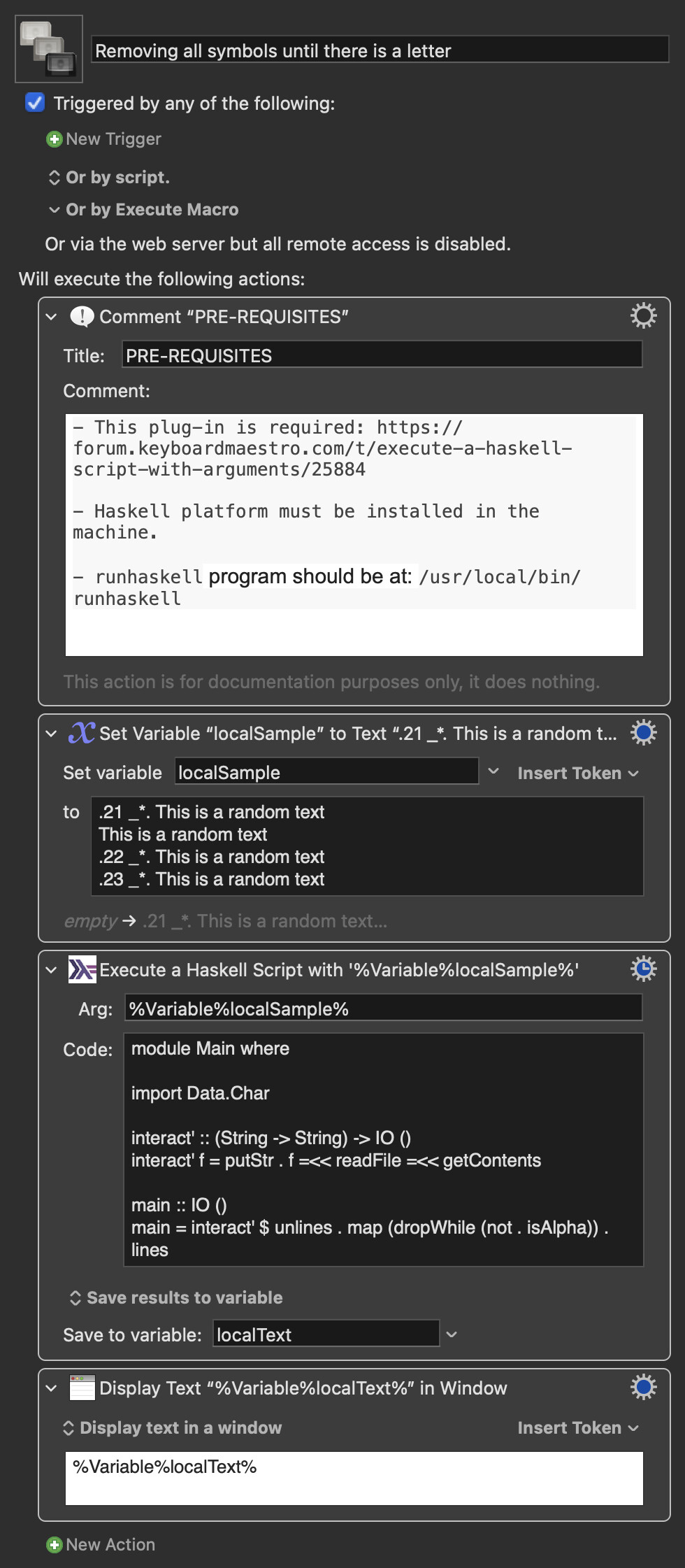
Not sure this is useful since you're asking for a regular expression.
Nevertheless, here is a Haskell Script that attempts to solve your problem. It only uses one higher-order function: dropWhile applied to the predicate not . isAlpha, that is dropWhile (not . isAlpha). In words, the function "drops" characters while an alphabetic character is not found.
Hey, I've tried to use the thing that you've sent me but i had trouble with your plugin.
After dragging it onto the Keyboard Maestro in the toolbar and running the macro it was saying "Plug in failed with script error"
Hey!
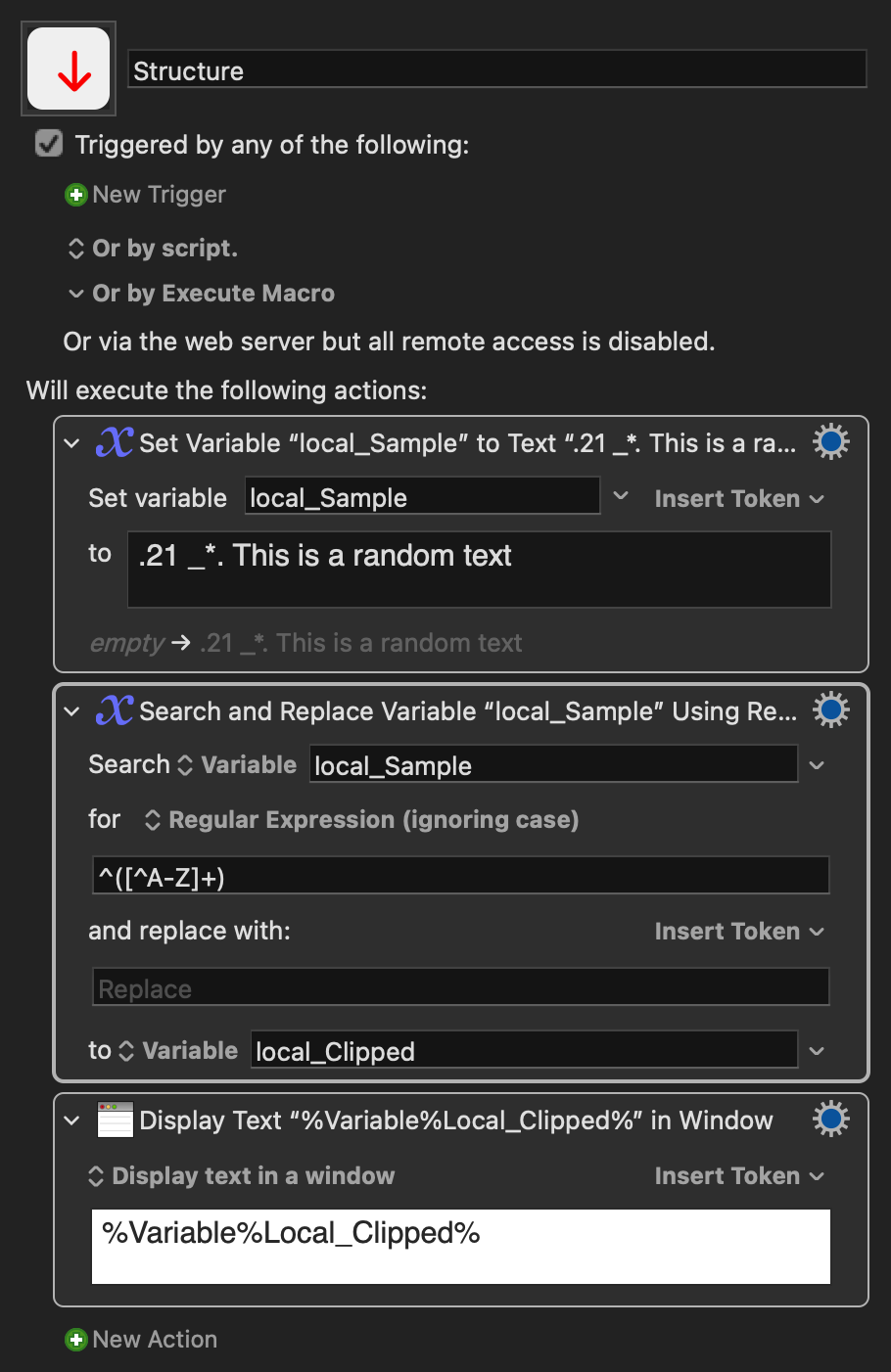
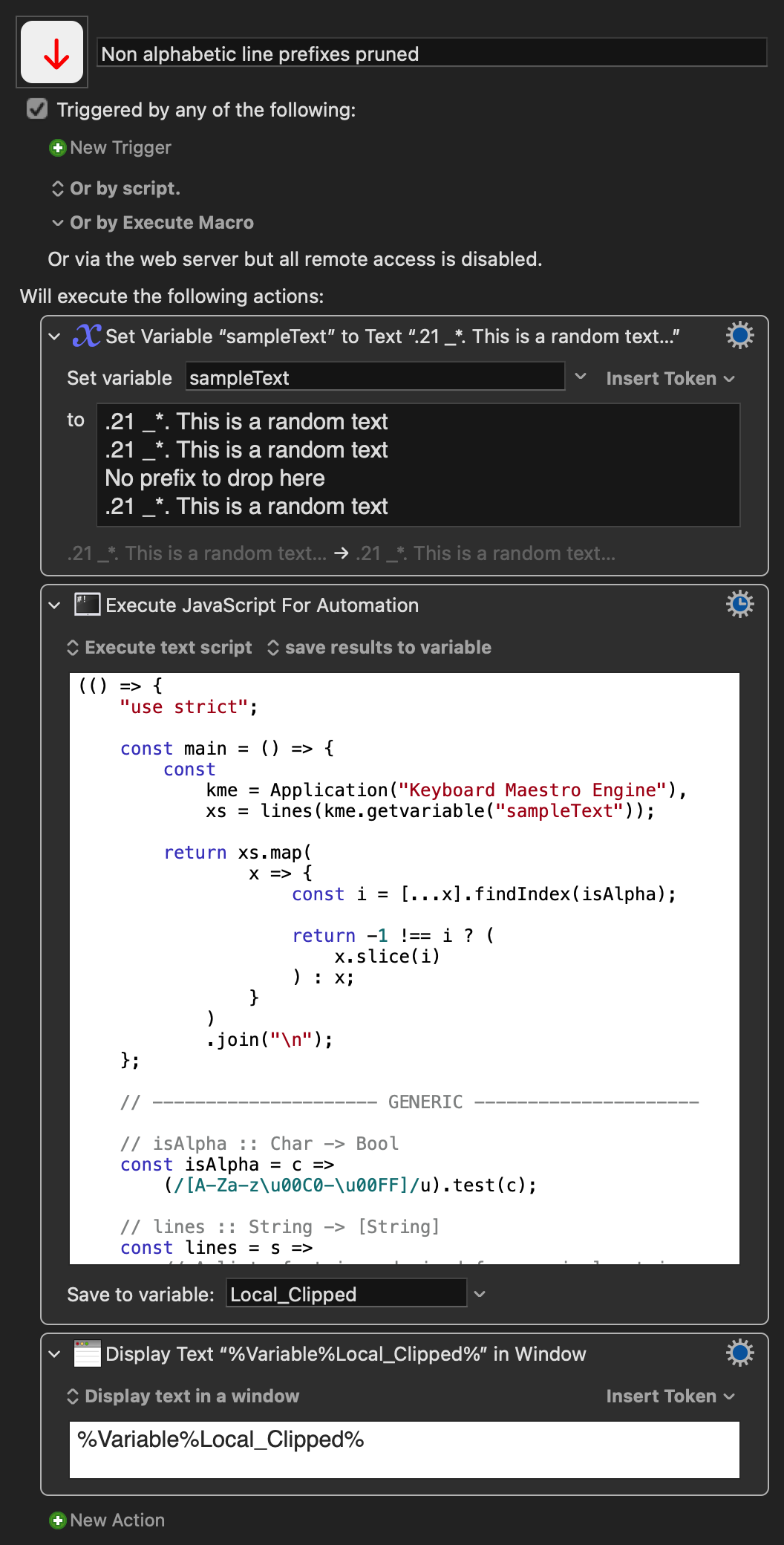
Your solution worked quite well but i have a lot of lines with those sentences and the RegEx only applies to the start. Do you have any ideas on how to make it to transform more lines at a time?
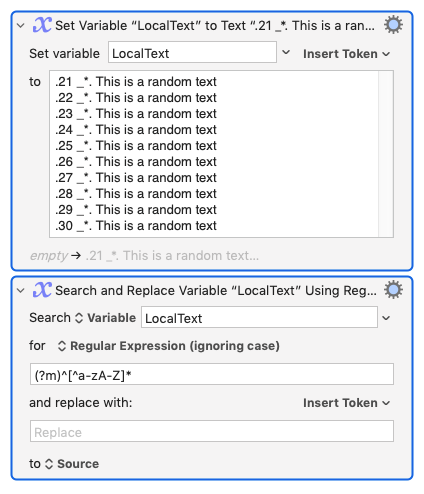
I may be being exceedingly dumb here (and/or missing the point!), but couldn't you use KM's "Search and Replace" with a regular expression of "from the start of each line, find the longest match of non-alphabetic characters and replace them with an empty string"?
So your match expression would be (?m)^[^a-zA-Z]* and your "replace with" would be left blank.
Using sed in a Shell Script action should also do the trick: sed 's/^[^a-zA-Z]*//'.