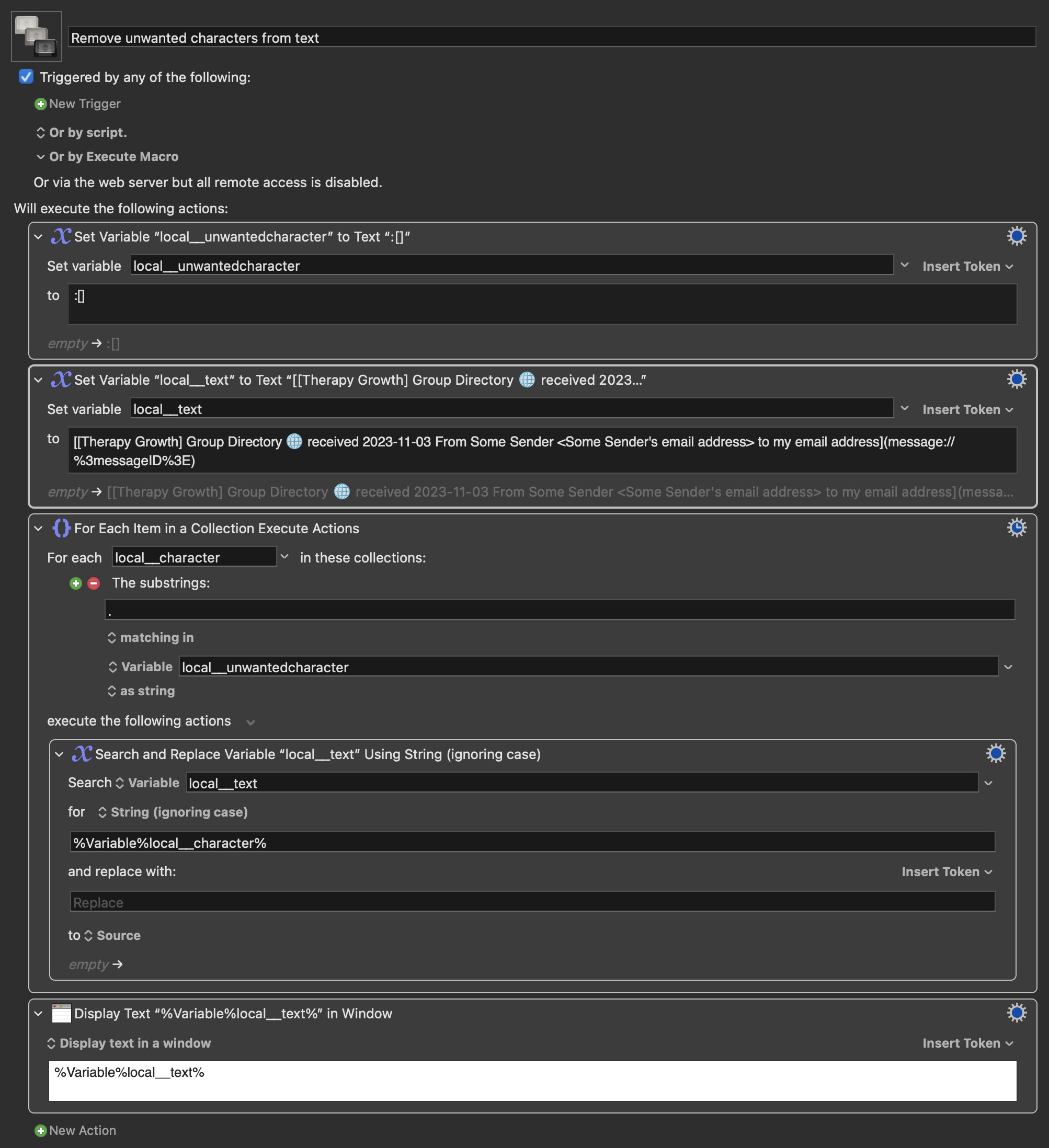
There seem to be quite a few examples of using Regex to remove unwanted characters from strings, but I have a case that doesn't quite fit what I have found in the forums, and needs a lot more brain power than I have.
I found an Apple Script that will get some information from a message in Apple Mail and gives me a result in this sort of format:
[[Therapy Growth] Group Directory 🌐 received 2023-11-03 From Some Sender <Some Sender's email address> to my email address](message://%3messageID%3E)
I would like to paste this into a note in Obsidian (which is why it is formatted as a markdown link). However, subject lines sometimes include characters that interfere with linking, such as the square brackets in the example above, and others such as :). Of course, such characters might appear anywhere in the subject line, and in almost any combination, which makes me think it might not be feasible to use Regex magic to replace them. However, I thought I would put this out there as an interesting problem that somebody might be able to solve.
For my own part, I think I might take the simple option and go for
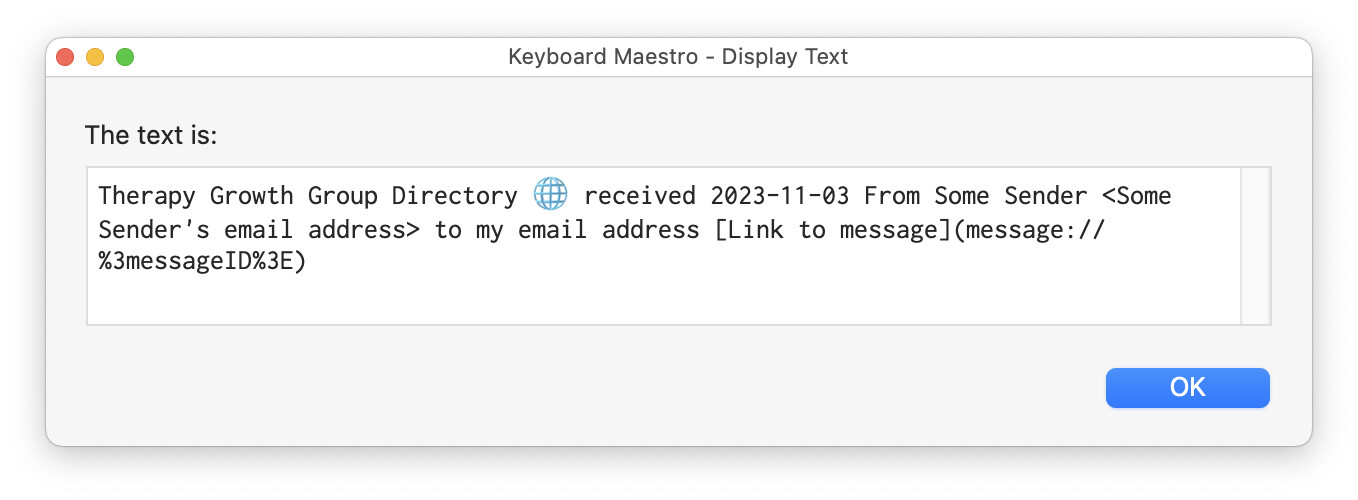
[Therapy Growth] Group Directory 🌐 received 2023-11-03 From Some Sender <Some Sender's email address> to my email address [Link to message](message://%3messageID%3E)
... and consider that the 24 hours I have spent with this problem have been useful at staving off mental decline and providing me with more evidence of why I ought not to attempt to do things which are beyond me ...
What you want should be doable with regex, but unless I'm missing something, I can't tell exactly what you want to remove. The only difference I see between your two output examples is that you've removed the first square bracket, and added [Link to message] before the link.
In order for someone to help you, we'll need a very precise definition of what you're trying to accomplish. If I were to guess those rules from your example, they would be "Remove any leading open brackets, and insert '[Link to message]' before a section that begins with '(message'" ... but I don't think that's what you really want, right?
The more detail you can provide on exactly what it is you need to accomplish, the easier it will be for us to come up with a regex solution (or alternative solution) for you.
The basic problem is that the subject line of an email may (legitimately) contain characters that mess things up when you want to create a markdown formatted link to that same email using the subject line as the clickable part of the link. Someone only has to put [Important!] or [For next week] , or :-( somewhere in the subject line, and you might need to do some fiddly editing to weed out the characters that are messing up the linking.
As I wrote:
and that is part of the problem -- where they might be and how many there might be is not predictable. Moreover, while replacing something like [Important!] with *Important* might not be too hard, I'm not sure what one could do with text emojis (or whatever they are called). On second thoughts, however, the latter may be a red herring -- they might not interfere if they are inside square brackets. I'll have to experiment some more.
Not knowing where or how many isn't a problem. What is a problem is not knowing what those characters might be. As of now, I only know you don't want [ and : ... but if there are other characters, we'd need to know what they are in order to remove them, too. But the order and quantity is irrelevant.
Once we know what the characters are, then you can do this quite easily with regular expressions.
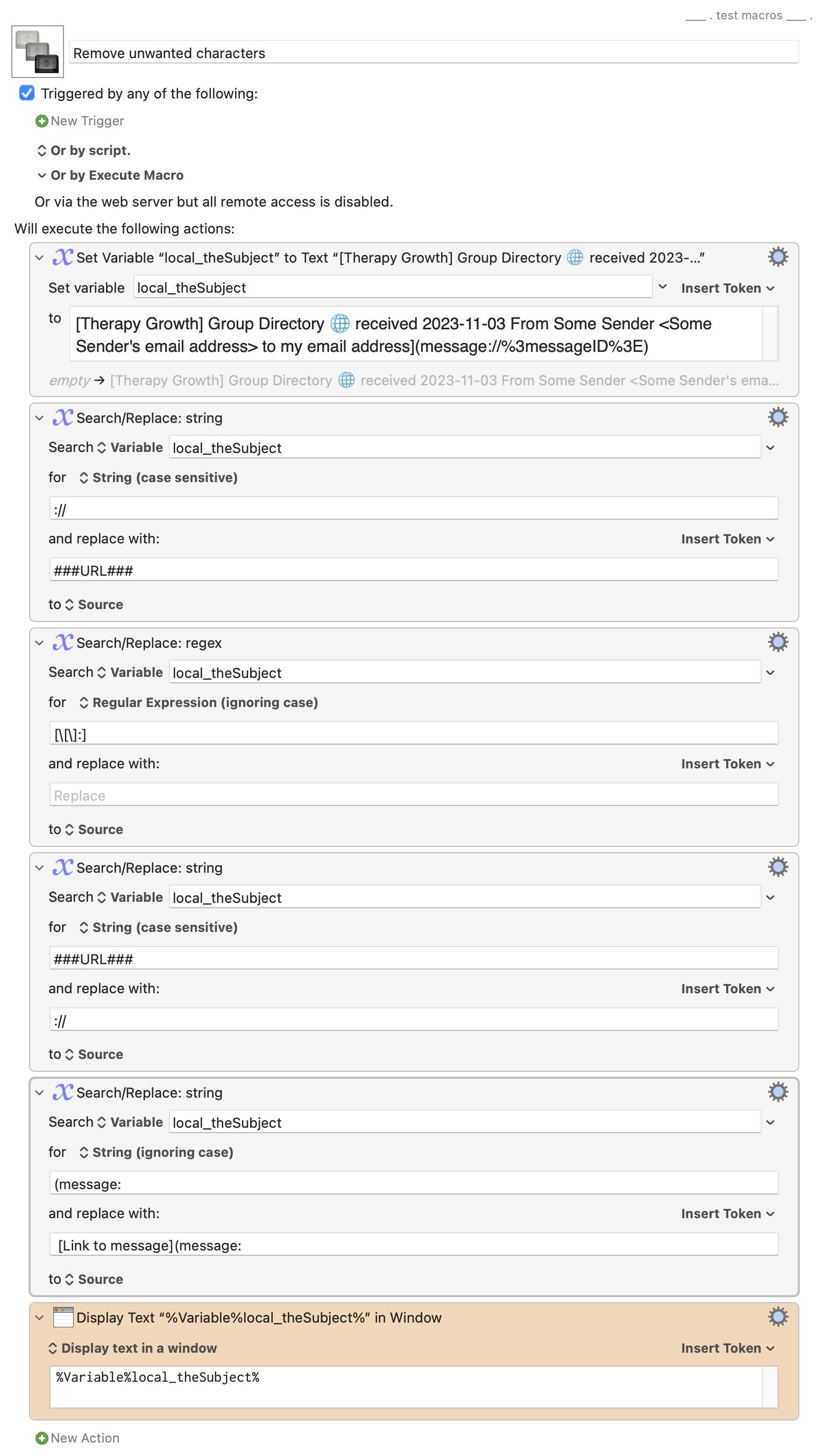
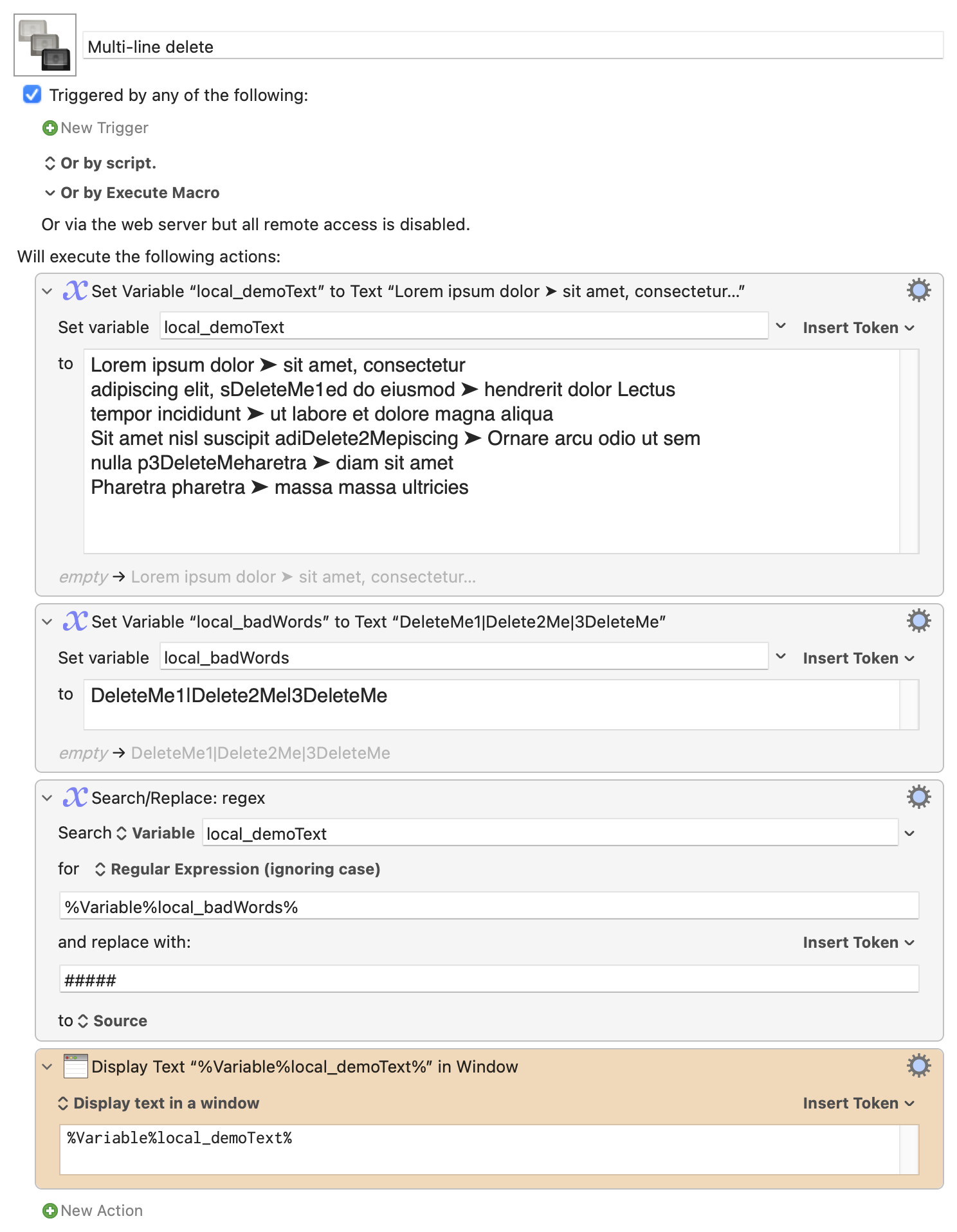
The first command changes the "://" bit into a string that's unlikely to occur in a regular subject line, so we can fix it later (because we want to keep this colon, unlike any others).
The second command is the list of characters you want to remove. They are within square brackets, but because square brackets have special meaning in regular expressions, they have to be escaped with backslashes to actually find them. You can add any other characters you want to remove inside the square brackets, taking care to escape any other special ones—parentheses, backslash, and others.
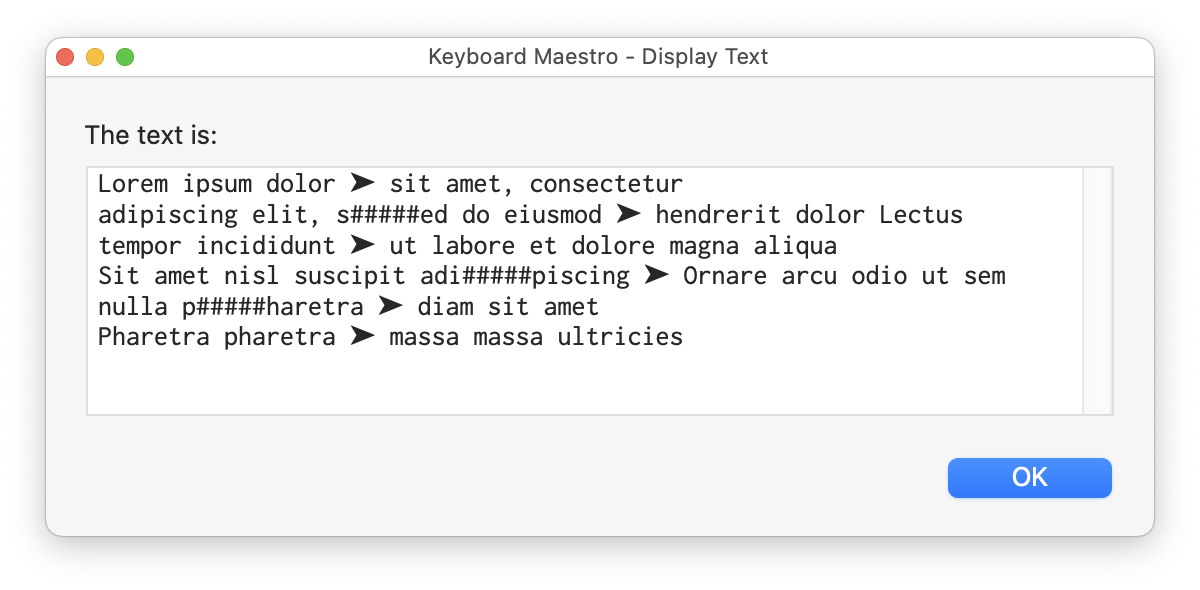
The third command replaces our URL placeholder with the :// again. The last command inserts the "Link to message" bit. And here's the result:
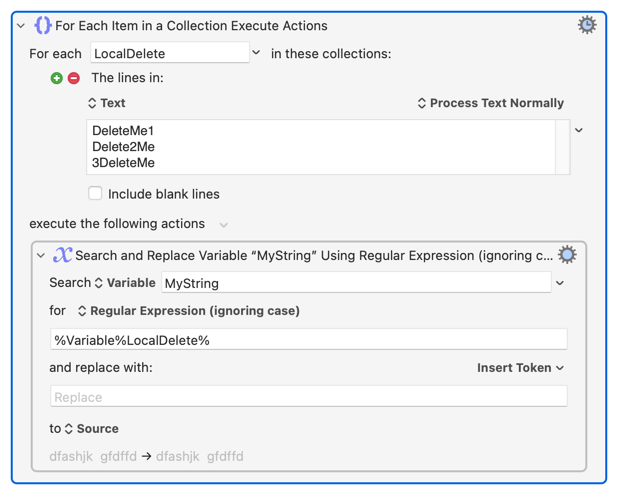
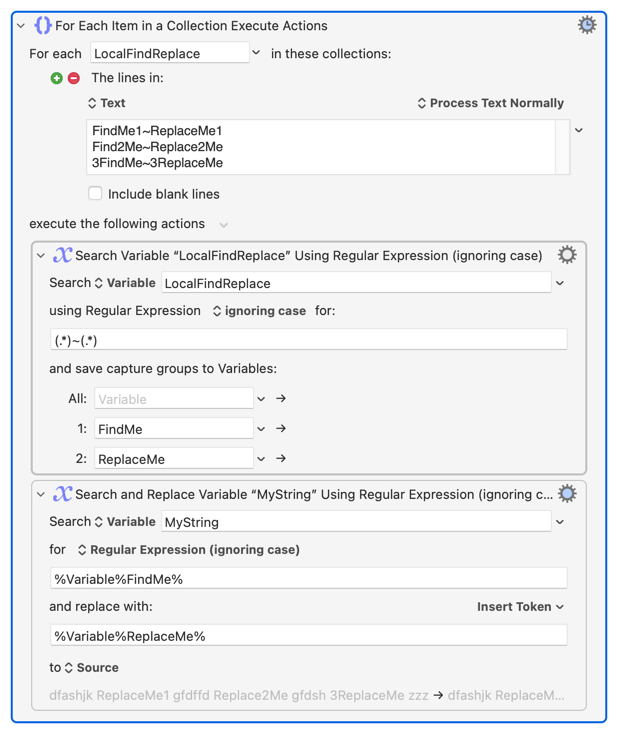
Don't forget you can probably use a loop containing one or two parameters separated by a comma. For example, to remove a list of strings you could do this:
Then I would create a second loop that lets you specify two strings, if you also want to "replace" one string with another. It's just slightly more complex.
I replaced the "bad words" with # signs, just to make it obvious. In regular expressions, the vertical pipe means "or," so it'll search for all of those words, anywhere they occur, and as often as they occur.
Yes, but I think he wanted a different replacement string for differing search strings. My method can be modified to accommodate that. I'm not certain how to best modify your method.
To create a link, enclose the link text in brackets (e.g., [Duck Duck Go] ) and then follow it immediately with the URL in parentheses (e.g., (https://duckduckgo.com) ).
This is fine unless the text element (the part inside square brackets) contains characters that confuse a program about where the text for the link ends or begins. So when I pasted the example I originally gave at the top of this thread into Todoist, it treated the text within square parentheses as three different links, which produced different results when clicking on them.
It would be nice to be able to arrive at a string of text within the square brackets that gets interpreted as a single link, and for this it seems to be necessary to strip out, or replace, characters which might confuse the issue. Among those characters are square brackets, and also, it seems, angle brackets. I thought that parentheses might also cause problems, but it seems they do not. (At least, not in the experiment I tried.)
You have given me an abundance of suggestions for methods of doing this, and for that I am most grateful. I think it will take me a while to go through them all and understand what they are doing. So, for now, many thanks.
So I think you are trying to extract data from (parts of?) HTML variables. Yes, that's possible, but HTML is such an eclectic collection of possible syntaxes, that it's a real challenge to always get it 100% right. There are entire threads on this website about this topic, like:
There are also entire programs on the internet that can do this. With varying levels of success I've done it myself. But sometimes I discover some HTML that my script fails to process, and I usually give up trying to fix it. But if you are sure you can isolate the element, you can probably make this work.
No, not at all. I'm simply trying to get a link so that when I am in a program like Todoist or Obsidian, I can click on it and have an email open in front of me. I'm beginning to lose track of emails that relate to certain things I am doing, and I thought it would be nice to be able to collect links to them so that I don't have to go searching for them. But such simple things often turn out to be less simple than originally thought ...