You're close. The Regex to do this is: (?mi)^DND_ETC__List\d+\R(.+)
For details, see
Use the same pattern of For Each Actions that I have used in the other questions you have asked.
I think you're ready to step up and apply what you have learned.
Give it a shot. You'll learn a ton more doing it yourself.
If you really get stuck, post back here and we'll help.
I actually do quite a bit outside of the forums and have built over 100 macros I use regularly to for my work. I really get stuck with the regex though but can understand a bit of it now. Such as your Regex for this one I know what that line means but get stuck implementing it. It really helps that you link to the tester so I can see what each character does.
Here is what I have for it but the display box does not show that it is finding and logging it correctly however. Also I want to add one more variant to the find but was hoping to have this hashed out before asking I wanted to know if I could also make it so that if the difference between B and C was less than a number, like say 100,000, it would get the next line instead until it found one that was higher than 100,000. Also, if the set (any of them like say DND_ETC__List1) had only one line then it would log that line. And finally if none were greater than 100,000 to log the one with the highest value.
OK, it is a bit confusing when you need to use two different RegEx blocks to process all data in a list:
First RegEx -- find and extract the text which repeats in the list
Second RegEx -- Process the text found by #1.
So here is the pattern I was referring to. Perhaps there was not an exact match for this pattern in your previous questions. So, let's continue the lesson:
I'm not going to post the macro file for the solution to this question.
I want you to review the above graphic, and fully understand it. Ask questions if you need to.
Then implement in a macro. Let's stick with your initial question for now. When you get that working, we can address the more complicated issue of matching data based on its value.
I love this idea Michael. OK so I tried setting it up but was getting a blank list at the end. I put a display box as the first action in 'for each' like below and it wasnt even showing up.
and of course when I have regex tester open it absolutely is finding the right line (first line). So I thought maybe there was a command in there that didnt work with my old OS (maybe you can answer that) so I changed to /R to /n in regex tester and it looked to do the same thing for what I needed. I think this might have been setting me back earlier in the morning when I was trying to hash this out.
When I plugged in (?mi)^DND_ETC__List\d+\n(.+) I was able to get that right line.
So then I set up a display window (and cancel macro right after) to display the findings of the first "Local__Block" find which showed up as
DND_ETC__List1
SK BDC ,178554794,178614633
Stepping this through, I understand now after seeing the display window why you need the second regex. And with the second regex I had to do the same thing, change /R to /n tested it out in Regex tester, looked good, tried it in macro and bingo, display window showed up with only first lines from each set XD
I would like to try the next parts. Is there one you think I should start with?
Sorry, I forgot that \R doesn't work on your system.
Note that it is backslash \ not forward slash /.
OK, great! Glad to see that you worked it out.
OK, but there is a major issue here: RegEx deals only with characters, NOT numerical values. So there is no direct way to compare the text to see if it exceeds the number 100000.
IAC, looking at your requirements:
These really need a script to analyze and make the comparisons, well beyond the scope of RegEx. Could we make it work with a combo of RegEx and KM calculations (like we did before), probably. But I'm not sure that is the right approach at this point.
As we solve one of your problems, you come up with the next, usually more complex. So, I need to ask: Do you know the full scope of the processing you ultimately want to do? If so, it would be best to lay it out now, so we can design the best architecture. It could still be implemented in parts, but we would know where we are headed, and make smart choices.
I'm getting an indication, based on what little I know, that it might be better to put all of your raw data into a database, and then use SQL and scripts to generate the results you need at any one point. Does this make sense to you?
OK let me run this for a few days. I find that if I test the macro over a few days all the things I hadnt considered creep up.
This already gets me like 95% of what I need it to do really. I was trying to think ahead which is why I asked about the additional function of determining if the difference was less than 100,000 but to be totally honest this is going to be a rare case and not a show stopper for me.
Totally agree, Ive learned that lesson on the last few threads I have started. I initially think hey I just need it to do this one thing and Im golden, only to find out I didnt consider x,y,z. Like I mentioned let me run this for a few days in different scenarios to see if there are any other factors I am not considering.
I had to look up SQL and from what I understand a database would certainly come in handy. The dataset will change daily but if one of the names from column A in a new dataset shows up again I would definitely like to know. So in other words if I ran my macro that logs this information and it finds say "SK BDC " it could check against the database to see if it has seen this name before. and pulling out farther than that each database would have to be a specific set depending on the day so Monday I would use/add to/check against databaseA. Tuesday databaseB. etc
I want to post an update on the new thread but there is one teeny thing holding me up. I actually made a ton of progress on my macro and had to correct some things I hadnt considered (as per usual ) The GREAT news is that I was able to pull from what I learned in the other threads and have achieved what I needed.
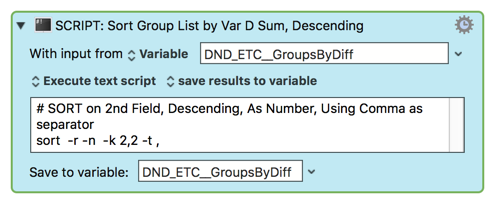
Anyway, the one thing holding me up is I was wondering what a shell command would look like to organize the list by Variable B. After I work that action in I will post my update so you can see my progress
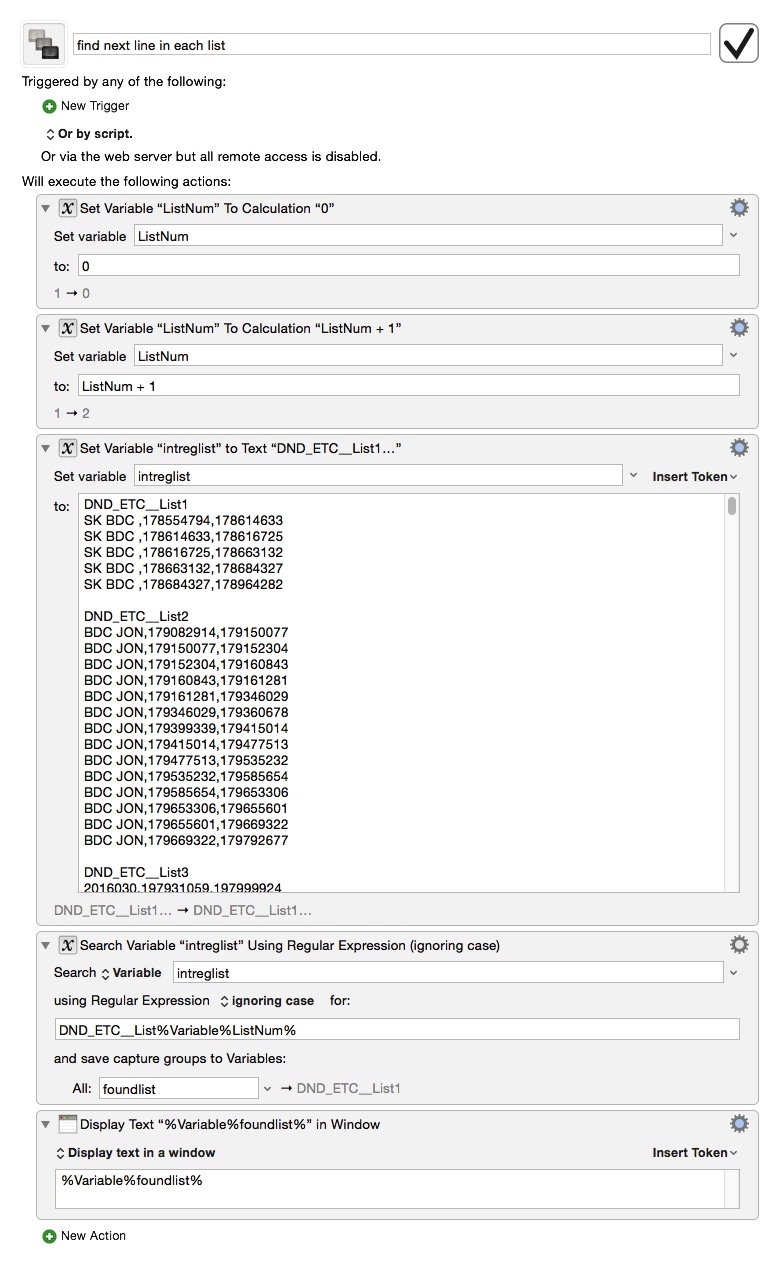
 I wanted to know if I could also make it so that if the difference between B and C was less than a number, like say 100,000, it would get the next line instead until it found one that was higher than 100,000. Also, if the set (any of them like say DND_ETC__List1) had only one line then it would log that line. And finally if none were greater than 100,000 to log the one with the highest value.
I wanted to know if I could also make it so that if the difference between B and C was less than a number, like say 100,000, it would get the next line instead until it found one that was higher than 100,000. Also, if the set (any of them like say DND_ETC__List1) had only one line then it would log that line. And finally if none were greater than 100,000 to log the one with the highest value.
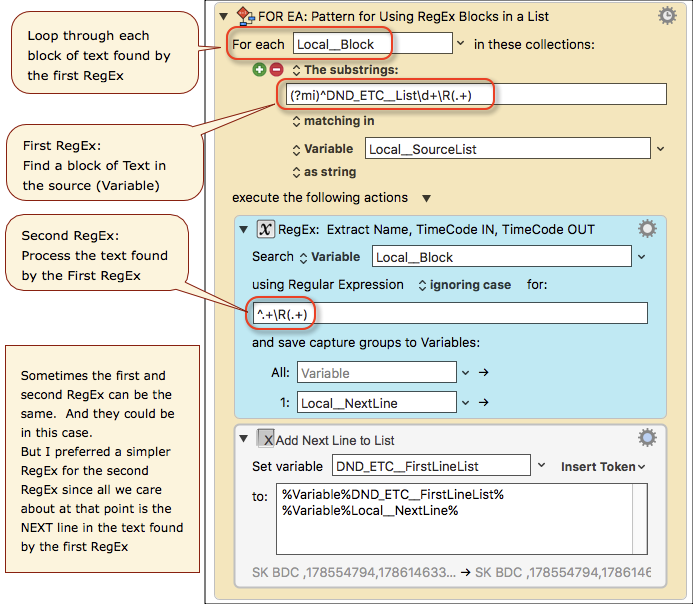
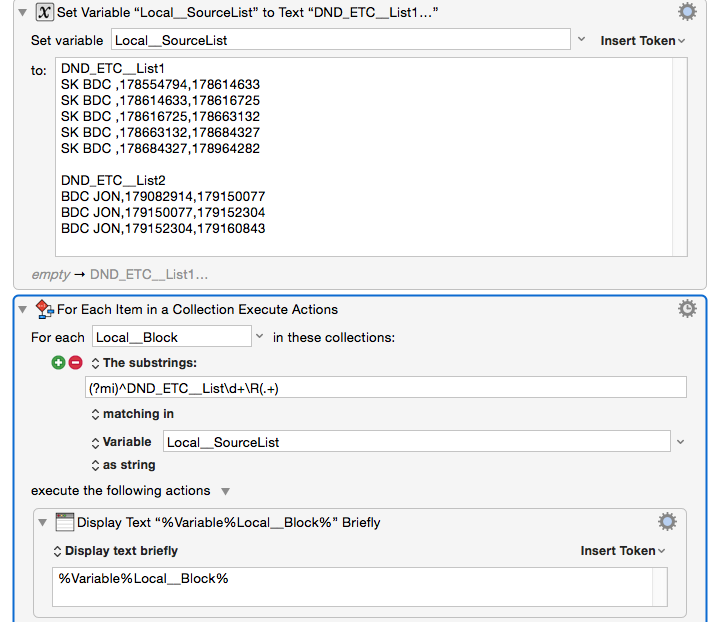
 ) The GREAT news is that I was able to pull from what I learned in the other threads and have achieved what I needed.
) The GREAT news is that I was able to pull from what I learned in the other threads and have achieved what I needed.