I concluded that the Macro Library forum is the best location for this post, but if an admin disagrees, they can move it. It contains code fragments for macros.
Rich Text Files (RTFs) are essentially what you get when you cross a plain text file with a word processor file. They can support fonts, styles, but not some important things like pagination details. And to make their limitations even less tolerable, Apple and Microsoft went in two different directions when adding features to RTF. Apple's variation is called RTFD, while Microsoft retained the name RTF. Apple allows you to edit basic RTF files up to a point, but if you try to use certain features, Apple software will force you to save as RTFD, or lose some of your document if you save as RTF (like losing your images.)
Some programs don't support AppleScript, but most support Copy and Paste. Therefore Copy and Paste are the only ways to get data out of some apps. When you copy text out of an app, you get either plaintext or rich text (in Apple's case, RTFD rich text because it may contain images.) I decided to try to parse this rich text in order to get the data I wanted out of it (because the apps I'm using don't always support AppleScript so I can't direct the app to give me only the data I want.) So I thought I would copy text from the app's window (CMD-A;CMD-C) and then "process" the Rich Text clipboard to "understand" the RTFD text. I was hopeful to succeed, but the internals of RTF files aren't as simple as I had hoped. Nevertheless I'm posting the success I did have for others to pursue if they want to.
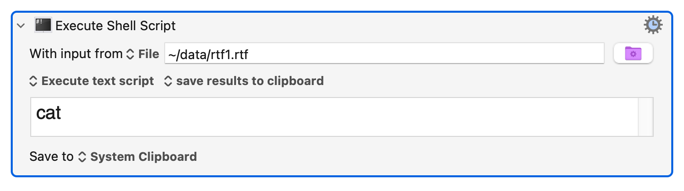
The first problem is obtaining the data for the RTF file. Normally that's just copying the rich text from the app using CMD-C. Easy enough.
The second problem is saving the text to an RTF file type. Like this:

The third problem is fetching the RTF file back into the clipboard, but doing it in a way that lets you view all the codes, rather than loading it as an RTF file. I figured out that you can do that with the "cat" command. This is as opposed to the Read action in KM which (I believe) would interpret the codes into an RTF-style clipboard. (Note: it might be safer to use the cat -v option. It can't hurt.)
Bear in mind that RTF files are 7-bit ascii files, which means many ASCII characters and all Unicode characters have to be represented by escape sequences. Also bear in mind that Apple invented the RTFD format which is a slightly enhanced version of RTFD which is supported only on Macs (and some advanced RTF features are NOT supported on Macs, like images. Apple and Microsoft have not been cooperating here.)
Now comes the hard part, which I was partially successful at.
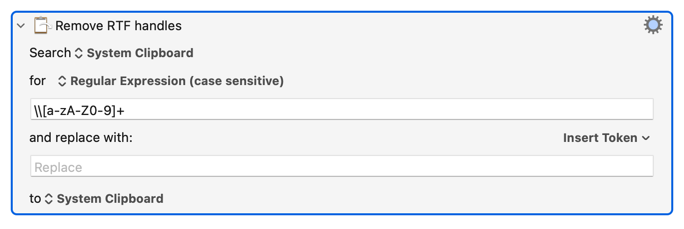
RTF files are filled with thousands of codes which tend to look like this: "\codename101". They always start with a slash followed by letters and/or numbers. There's no guaranteed termination character, but usually one code is followed by another code so you see lots of this sort of thing: "\abc12\abc34\someothername". It's not too hard to strip these codes out using a few Regex commands.
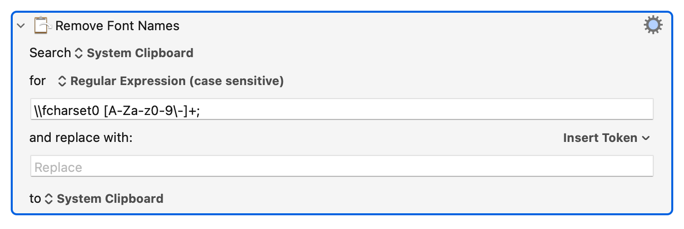
The first Regex we want to perform is a special case. That's because there's one common code that tends to look like this:
\\fcharset0 Helvetica-Bold;
Yes, this code contains a space and a font name and a terminating semicolon. These can be remove with the following command:
Once that is done, another Regex can get rid of the bulk of the remaining codes:
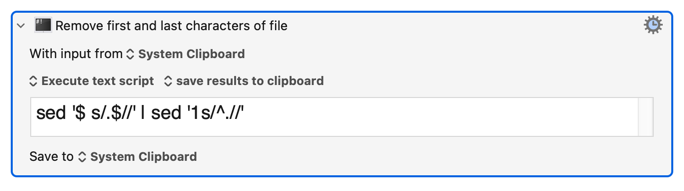
But there's still a lot more to do. And here's where things start to go wrong. I was unable to understand the syntax of many RTF commands. but most of them occur in braces ( {} ) and as long as your document doesn't include braces, (I suppose you could test this before you saved it, above) you may be able to use this to remove more characters. But the problem is RTF content doesn't have balanced braces! (More accurately, I don't understand how braces are used in all cases.) And to make matters trickier, the first and last characters of an RTF file are a set of braces. In order to remove the outer braces, this should work:
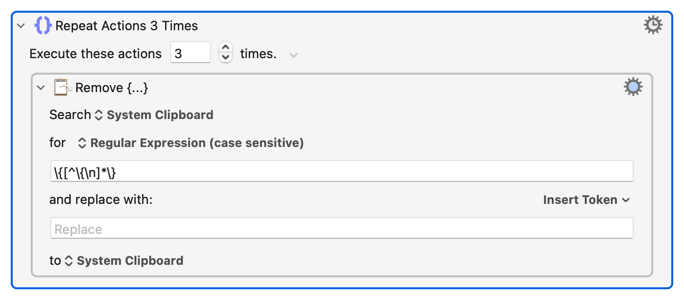
In order to remove pairs of braces and their inner values the following probably should work, but is not very accurate and I'm not sure why: (I'm using a Repeat loop to remove nested brackets, because I'm not very adept with Regex.)
But even if I could have solved all the above problems, there's a final bigger problem. And that is, the linguistic contents of an RTF file is not sequential (ie, not in the same order as you would read the words.) Specifically, when I examine the contents of a page from wikipedia, most hyperlinks (the part that you can read) are found in a later portion of the document. For me, that was an intractable problem. Someday I might come back to fight this battle, but not today.
So if anyone wants to carry the torch of processing RTF file contents, this article may help a little bit.