This looks like you're wanting to retrieve the HTML source code for the whole page. In many cases, you can just use Safari's source property, which is a property of tab and document objects in its AppleScript dictionary.
For example:
tell application "Safari"
get the source of the front document
end tell
which is largely equivalent to:
tell application "Safari"
get the source of the current tab of the front window
end tell
If, for some reason, this version of the source code doesn't contain up-to-date source elements, say, from client-side DOM manipulation that negates page refreshing; or some other situations where it varies slightly or significantly to what you see in the developer console, then your JavaScript code is essential fine.
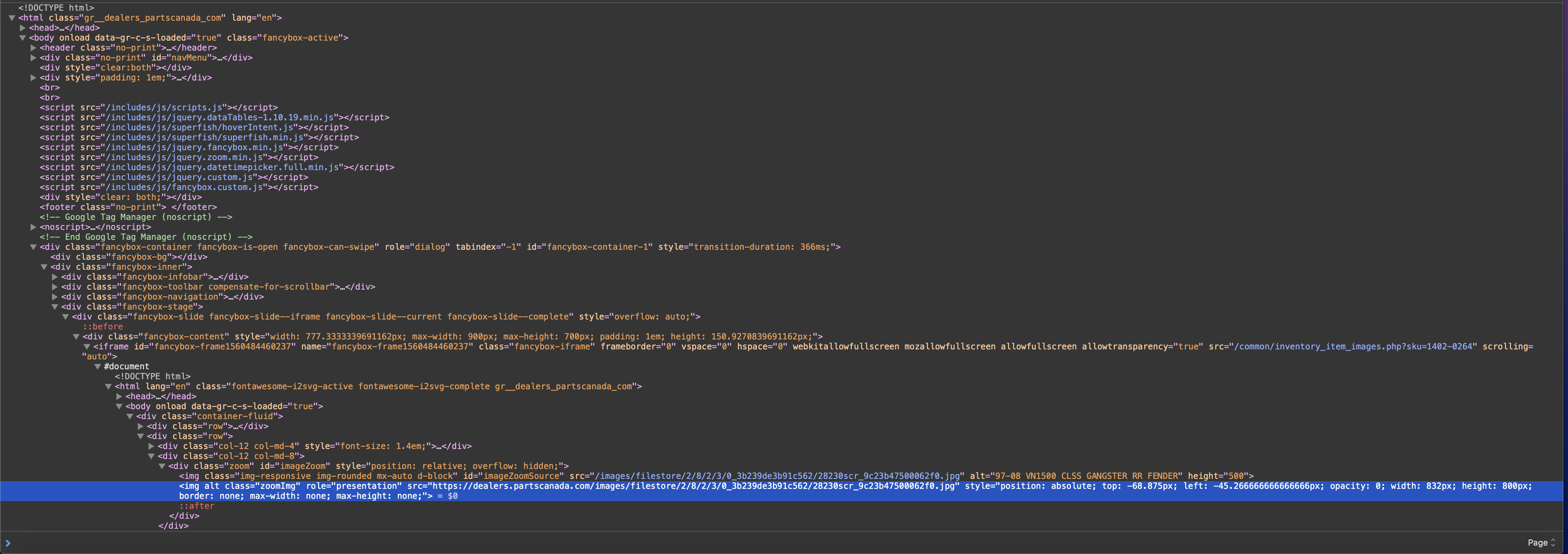
While it's very difficult to make good sense of the link to the HTML source you provided (it fails to render anything meaningful), what I do notice is that the img element you're directing us to appears to reside in a shadow DOM, indicated by the #document node. This is an encapsulated DOM hierarchy that is distinct from (although still attached to) the main DOM.
This would explain why your JavaScript call didn't find what you were looking for, as calls made to the main document object are specific to its DOM tree. To illustrate, try running this command, which one would typically expect would return the img element in question:
document.querySelector('#imageZoomSource');
My guess is that it won't, and you'll receive a null return value.
If it does return an element, my second guess that it will be a different element to the one you want, and that the main DOM happens to have an <img> element that shares that specific id attribute. id attributes are always unique within a DOM tree, but since a shadow DOM has a separate DOM encapsulation, it can use any id values that it itself doesn't already use, even if the main document object does.
To access the elements inside a shadow DOM, you generally want to access its containing element inside the main DOM, then switch DOMs at that node. Here is the block of HTML that's relevant:
<div class="fancybox-content" style="width: 921.3333339691162px; max-width: 900px;
max-height: 700px; padding: 1em; height: 126.13020896911621px;"
class="fancybox-iframe" frameborder="0" vspace="0" hspace="0"
webkitallowfullscreen mozallowfullscreen allowfullscreen allowtransparency="true"
src="/common/inventory_item_images.php?sku=1402-0264" vspace="0"
webkitallowfullscreen>
#document
<!DOCTYPE html>
<html lang="en" class="fontawesome-i2svg-active fontawesome-i2svg-complete gr__dealers_partscanada_com">
<head>...</head>
<body onload data-gr-c-s...
.
.
.
<img alt="97-08 VN1500 CLSS GANGSTER RR FENDER" class="img-responsive
img-rounded mx-auto d-block" height="500" id="imageZoomSource"
src="/images/filestore/2/8/2/3/0_3b239de3b91c562/28230scr_9c23b47500062f0.jpg">
<img role="presentation" alt src="https://dealers.partscanada.com/images/filestore/2/8/2/3/0_3b239de3b91c562/28230scr_9c23b47500062f0.jpg"
class="zoomImg" style="position: absolute; top: -35.34375px; left: -9.936655583424669px; opacity: 0; width: 832px; height: 800px;
border: none; max-width: none; max-height: none;">
.
.
.
I'm wondering if the first <div> tag was accidentally merged with a child <iframe> tag when you copied over some of the code, because the attribute list seems incongruous, and features attributes that are specific to <iframe> tags rather than <div>. I'm going to assume that this is the case, so I'll be referencing the non-apparent iframe element through its class:
document.querySelector('iframe.fancybox-iframe');
which will be the entry point into the shadow DOM. In the simple cases, you can access it through its contentDocument property:
document.querySelector('iframe.fancybox-iframe').contentDocument;
Then you can treat this object pretty much the same as you would the document object. For example, to retrieve the HTML source code for it:
const $document=document.querySelector('iframe.fancybox-iframe').contentDocument;
$document.documentElement.outerHTML
Or to retrieve the img element using the earlier technique applied to this shadow document object:
$document.querySelector('#imageZoomSource');
which is equivalent to:
$document.getElementById('imageZoomSource');
Obtaining its src attribute value, i.e. the URL to the image, is done like so:
$document.getElementById('imageZoomSource').src;
which appears to contain a relative URL, namely "/images/filestore/2/8/2/3/0_3b239de3b91c562/28230scr_9c23b47500062f0.jpg", so you can just remember to prepend the domain and scheme, which will be "https://dealers.partscanada.com".
The second img element contains exactly the same image retrieved from the same URL, but its src attribute value provides the full (absolute) URL that saves a job, I suppose. However, it doesn't have an id attribute, and both the class and role attributes sound very much non-specific enough that other elements might share these values, in which case the following snippet will return multiple elements and be of lesser value:
$document.querySelectorAll('img[role=presentation].zoomImg');
In more complicated situations, the shadow DOM can have be kept from exposing itself or parts of itself to the parent, making it trickier to access its tree through JavaScript. Also, if the sub-document is loaded from a different domain, then it will be subject to the cross-origin restrictions that further roadblocks your API calls.
In the middle between "simple" and "complicated", there's "slightly annoying" if the nested document object doesn't necessarily load at the same time as the main document object, meaning a JavaScript call acting upon the shadow document will initially fail (because the document object either doesn't exist or contains no content), in which case you need to attach an event listener to act on it as and when it does load. But we'll address that if it's needed.