FIrst time posting here, so go easy on me. ![]()
I've been working on this problem for a few days now, and just can't seem to figure it out. I've read a ton of other discussions on the use of regular expressions/searching multi lines for use with Regex to parse out individual bits of info.
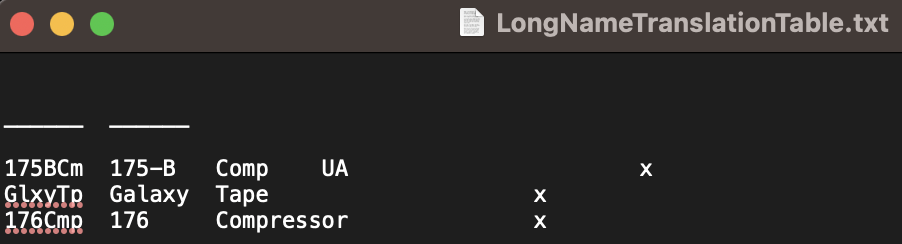
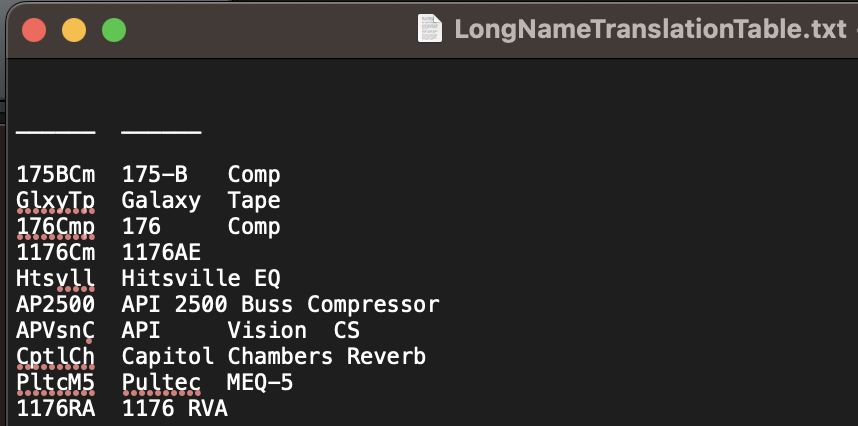
In a nutshell, I have a tab delimited lookup table that I have set up in a text file. There are only a few rows in it now, but there will ultimately probably be several hundred rows in it when it's all said and done. Nevertheless, the four rows I have in it now should be enough to develop a proof of concept.
The first column contains a unique six character identifier in each row. These six character identifiers are taken from plugin names assigned by the Mackie MCU protocol used in my DAW. The next three columns are intended to be used as a place where I can then input up to a max of three words (one in each column) which will then ultimately be combined into a single variable for use with the KM "Stream Deck Set Title of Button" action.
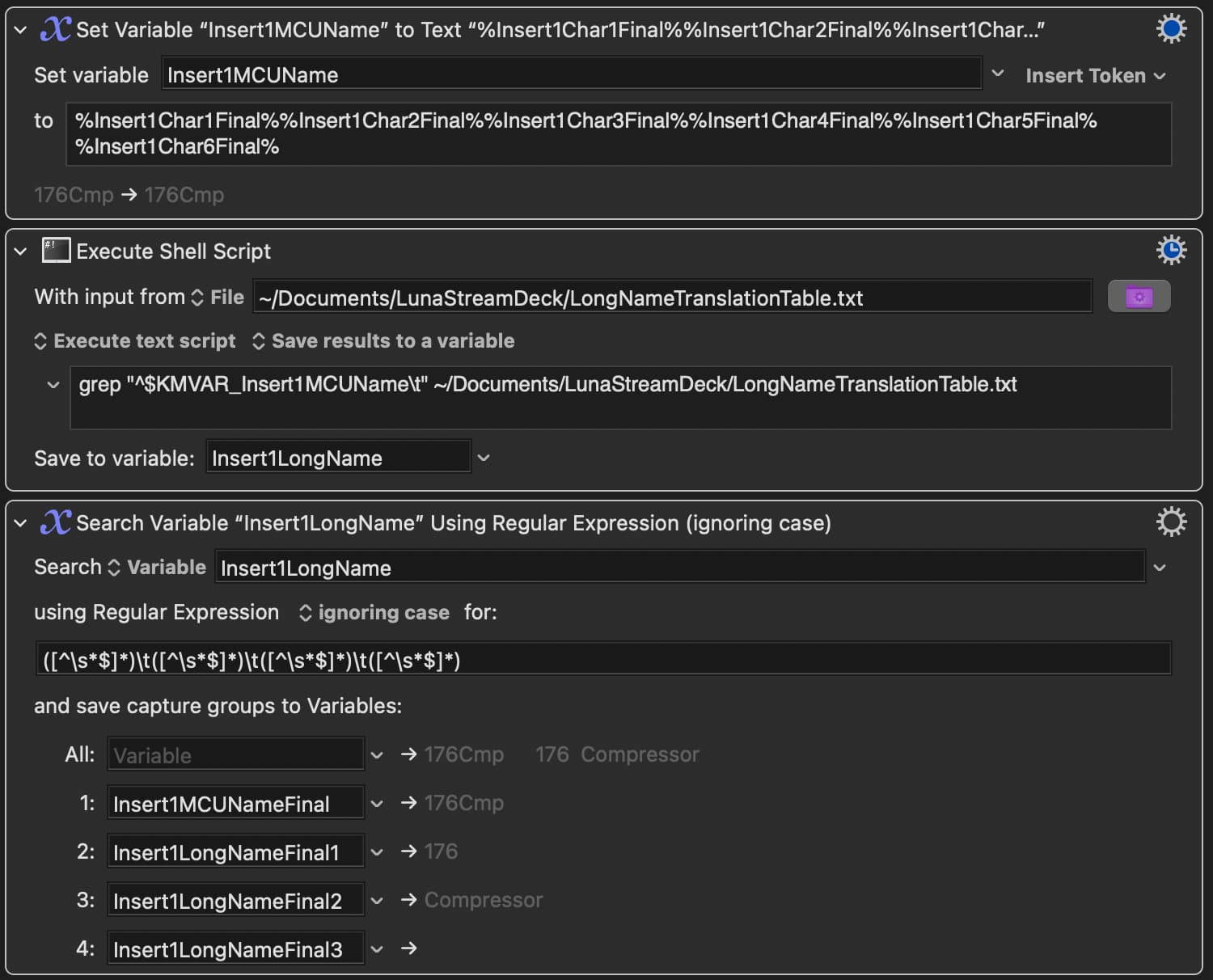
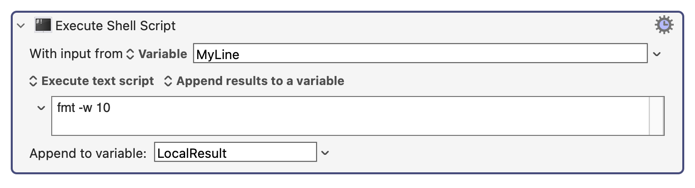
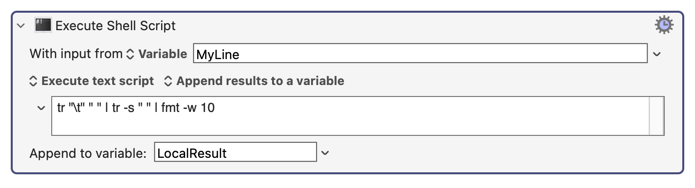
I've successfully used a shell script in KM to locate and produce the appropriate info from the desired row in the table, based on the unique six character identifier I'm asking it to look for. This six character identifier dynamically changes, but I've got that part figured out, and don't have an issue getting this dynamic info to the shell script. It always spits out the corresponding info from the adjacent columns, for that given row where the six character identifier is located. So I'm good there.
However, when I go to use the "Search Variable" action, using regular expression, this is where I run into problems. I've gotten it to spit out the word in each adjacent column, but it's having trouble if I leave any of these entries blank in the lookup table. I may not always have need for use of a word in each of the three columns in the lookup table, so I want to be able to leave some of them blank. It may be that I only need to enter a word into the first and/or second columns of the lookup table, leaving the third column blank, for example. This causes problems.
It seems to maybe be related to something to do with the end of each line not being defined? I'm not sure. I have noticed that when I just go and add "X" in a column further to the right in each row of the lookup table, the problem goes away. If I remove the X out to the right in each row of the lookup table, the regular expression action in KM just returns nothing for each capture group. If I put the Xs back in, it works again.
However, I don't want to have to go in and place an X in each row. I'd like to understand what the problem is here, and fix it so that you just enter a word or words into any or all of those three columns without worry that the Regex isn't going to function properly. So the problem is two fold. One, it doesn't like me leaving an entry field blank for any of the rows/columns. Two, for this to work, it seems to need an entry (using an "X" here) in a column to the right of the columns I actually care about.
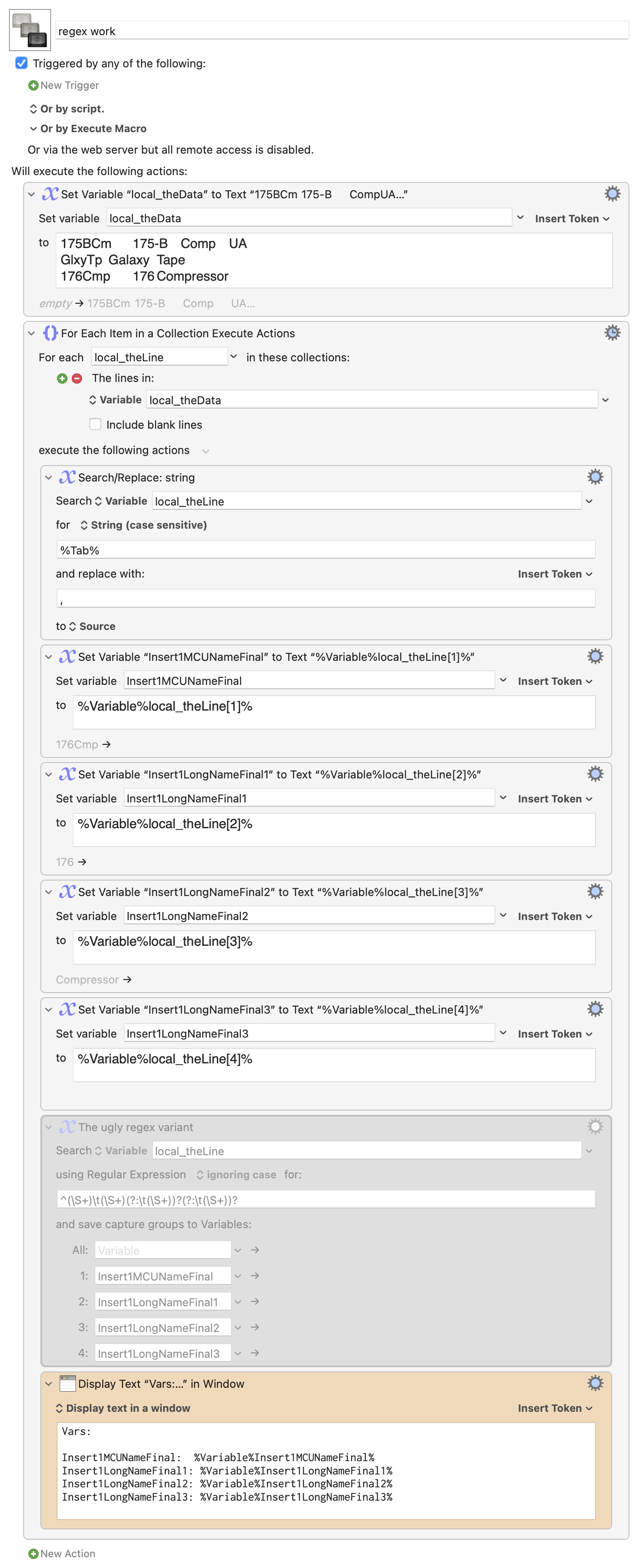
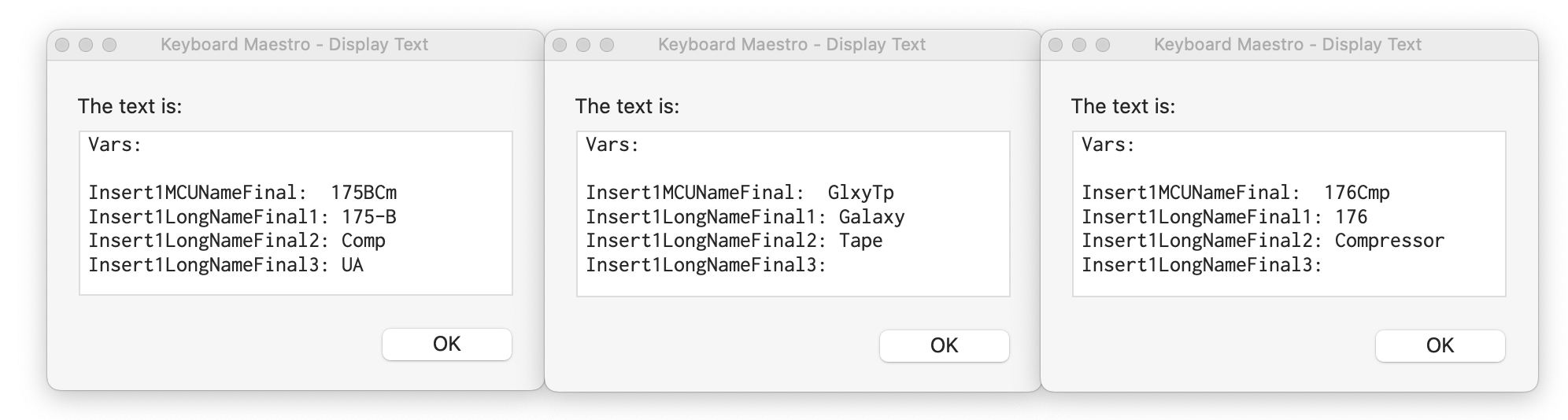
The problem seems to likely be with how I've got my Regex set up. I'm pretty much a novice with Regex, so I imagine it comes down to a mistake I've made there. Can somebody help me understand how I need to setup my Regex to do what I want it do? I've included a screenshot from KM for the relevant part of my macro. I've also included a screenshot of my lookup table. Thanks