Howdy folks, I am trying to figure out a way to search the clipboard for three objects that are different with each work call I receive. The three objects are:
- Customer Name
- Reference Number
- Participants Name
Below I have pasted the relevant section of the clipboard so you can see an example of what I am working with.
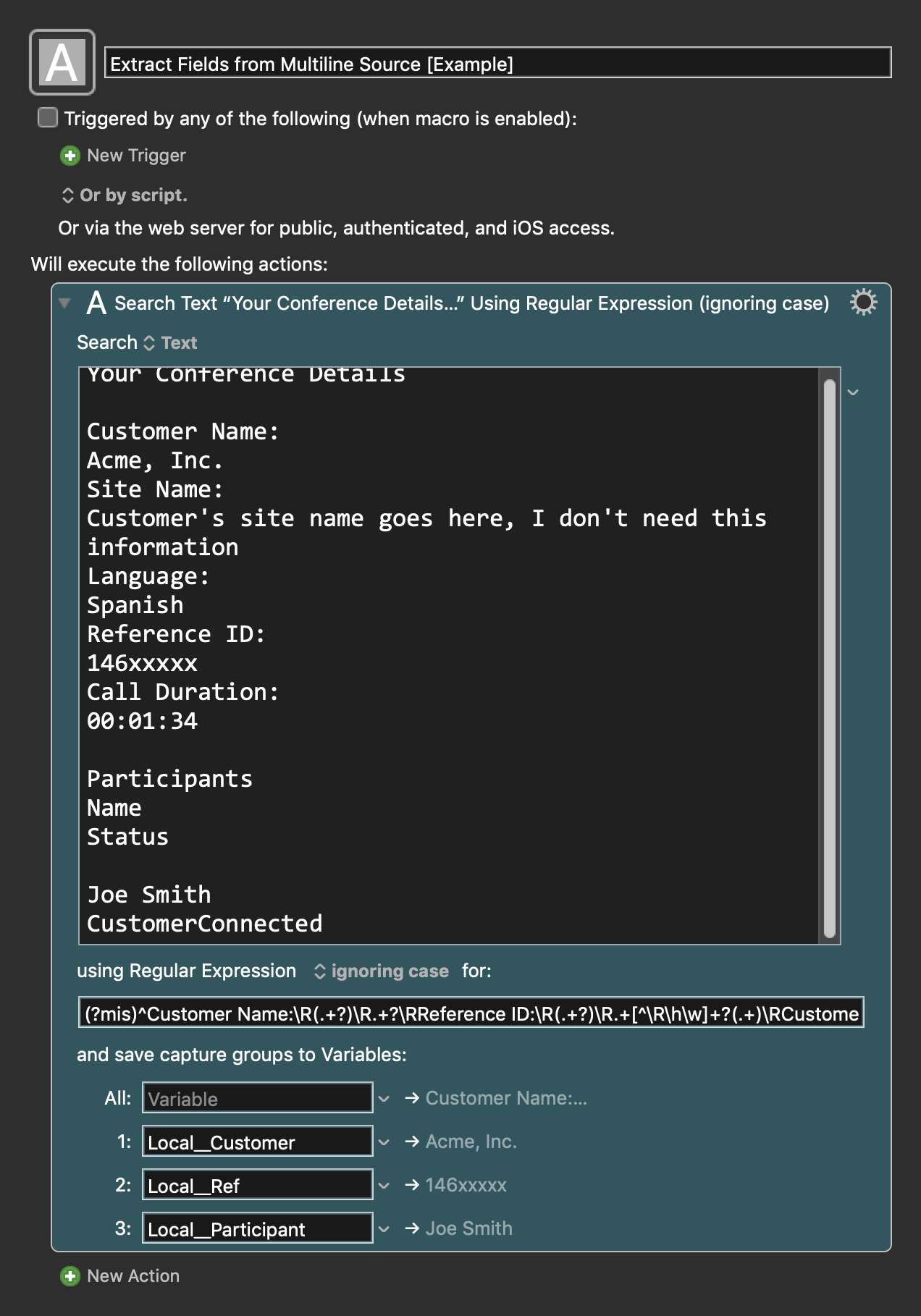
Your Conference Details
Customer Name:
Customer's name would appear here
Site Name:
Customer's site name goes here, I don't need this information
Language:
Spanish
Reference ID:
146xxxxx
Call Duration:
00:01:34
Participants
Name
Status
Joe Smith (this is the participant name I need to extract)
CustomerConnected
So essentially I need to find a customer name, reference number and participant name that is different with each call. I worked up a crude way of doing it by just copying the contents of the entire page, stripping it of it's formatting, pasting it into my work notes and then using menu commands to search for Customer Name, Reference ID and CustomerConnected, simulating keystrokes to get to the relevant information from there and copying to my corresponding variables. It works fairly well, but I imagine there is a simpler, more efficient way of doing this from within the clipboard itself. But I don't have a lot of experience with the clipboard and essentially none using special characters and Regex commands or whatever they're called.
I'm hoping somebody can give me some ideas of how I might accomplish this. Thanks in advance for any help!
EDIT: I was able to reliably get the reference number by searching the clipboard for the following Regular Expression and saving it to a variable: [0-9]{8}
Still looking for a way to find the customer and participants names though.
EDIT 2: I found another Regular Expression that searches for words between a set of two specified words and saves them to a variable: \bStatus\W+(?:\w+\W+){1,6}?CustomerConnected\b
Then I use a search and replace to remove the two words that formed the search parameters and that leaves just the info that appeared between them.
This appears to work quite well. But if anybody has an easier / more efficient / more reliable way of doing this I'm still open to suggestions.
Sometimes it is best to use multiple RegEx searches rather than trying to extract multiple fields from one search. If the format of the output you want to search is consistent, then this should work fine:
RegEx:
(?mis)^Customer Name:\R(.+?)\R.+?\RReference ID:\R(.+?)\R.+[^\R\h\w]+?(.+)\RCustomerConnected
For details see: regex101: build, test, and debug regex
Below is just an example written in response to your request. You will need to use as an example and/or change to meet your workflow automation needs.
Please let us know if it meets your needs.
~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
MACRO: Extract Fields from Multiline Source [Example]
-~~~ VER: 1.0 2020-06-24 ~~~
Requires: KM 8.2.4+ macOS 10.11 (El Capitan)+
(Macro was written & tested using KM 9.0+ on macOS 10.14.5 (Mojave))
DOWNLOAD Macro File:
Extract Fields from Multiline Source [Example].kmmacros
Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.
That appears to work well with a couple of slight adjustments. The webpage I extract the data from uses tables so I have to copy the contents to a clipboard so I can remove the formatting before reading it with RegEx. Other than that it works great.
I still have three separate macros to extract that info one piece at a time because sometimes I need to pull just one piece of information instead of all three. But I have added this one as a backup, with the last step to display the info in a window in case I just need to reference all of it real quick without going back to the beginning of my workflow. It works great for this purpose. Thanks for your input!
For future reference, it is always best to post the actual, real-world source text when you want help with extracting data from it. Most likely a RegEx can deal directly with the initial source from the web page.
Good to know. Unfortunately when it’s work related I can’t always do that for confidentiality reasons. Thanks again for your help!
Usually this can be done just by changing any sensitive data, but keeping the same form/format, that is in the original source.
1 Like
And good way to do this generally is just to change all the data parts letters to "x" and numbers to "5", but keep any of the remaining “tag” information unchanged.
So like:
Customer Name:
xxxxxx xxxx
Site Name:
xxxxx xxx, xxx, xx, 555
Language:
xxxxxxx
Reference ID:
5555555
Call Duration:
00:01:34
This helps spot things like the fact that Site Name has commas (or whatever, just an example). Regex tend to be rather unforgiving in their matching, so it is important to know exactly what is possible (including things like punctuation and UTF8 characters for example).
Personally I don't like that approach. It makes verification that you have extracted the proper data more difficult.
I prefer that the minimal changes be made to obscure the sensitive data.
For example, if the Customer Name was "Apple, Inc.", then change it to "Acme, Inc."
If the Participant is "Mr. Steve Jobs, II", change it to "Mr. John Smith, II".
etc.