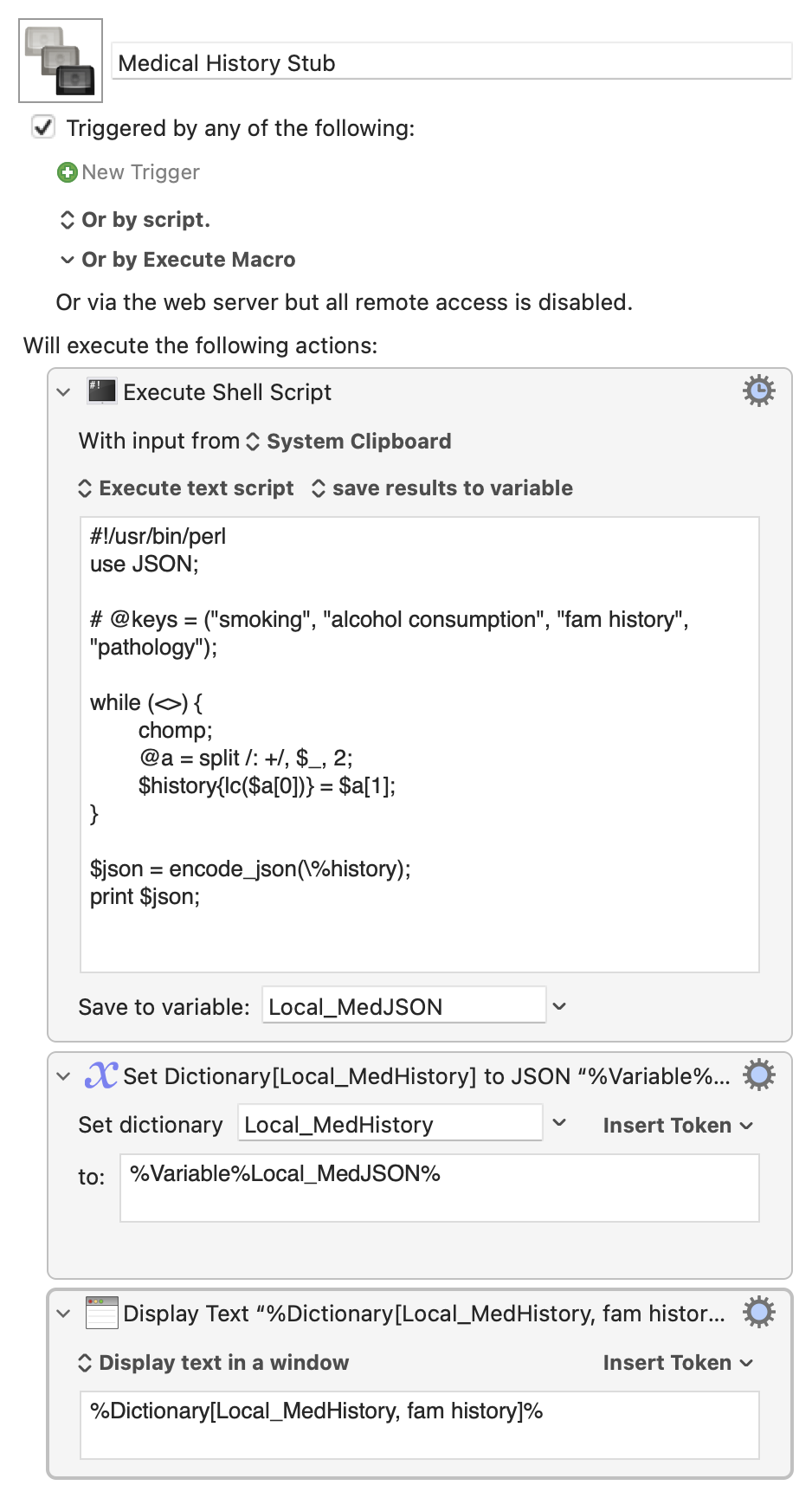
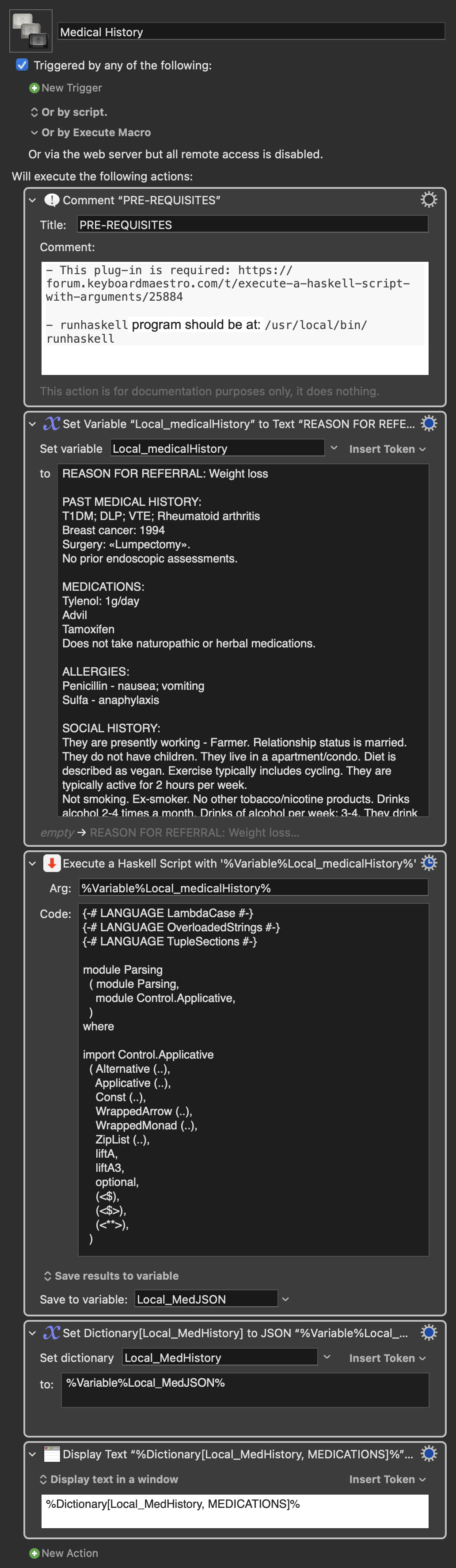
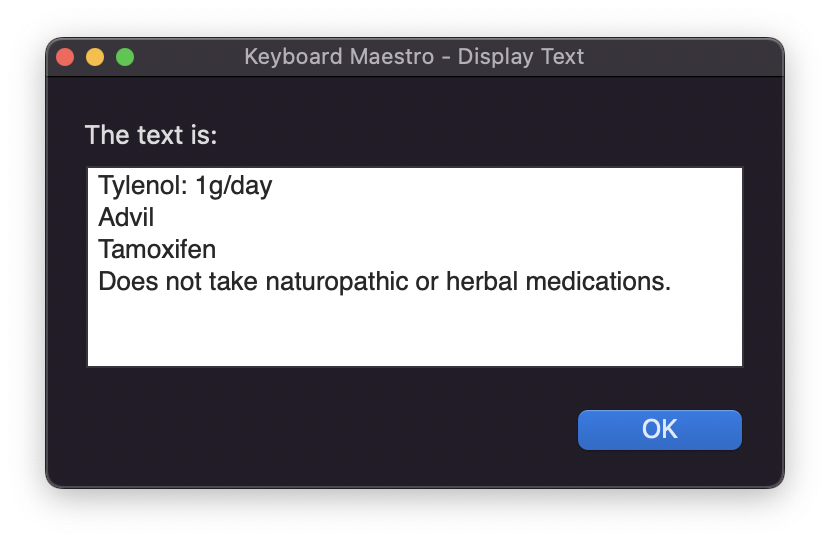
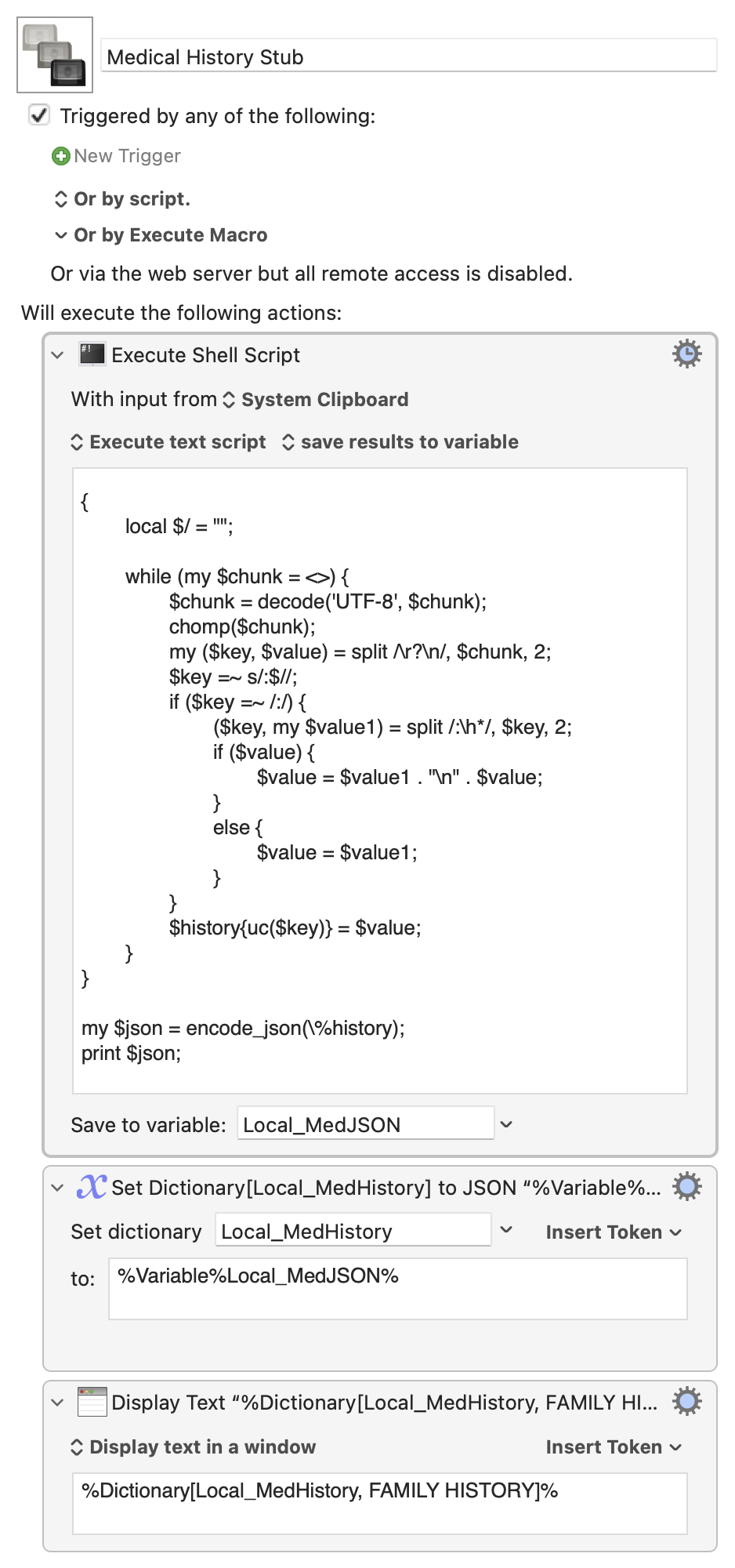
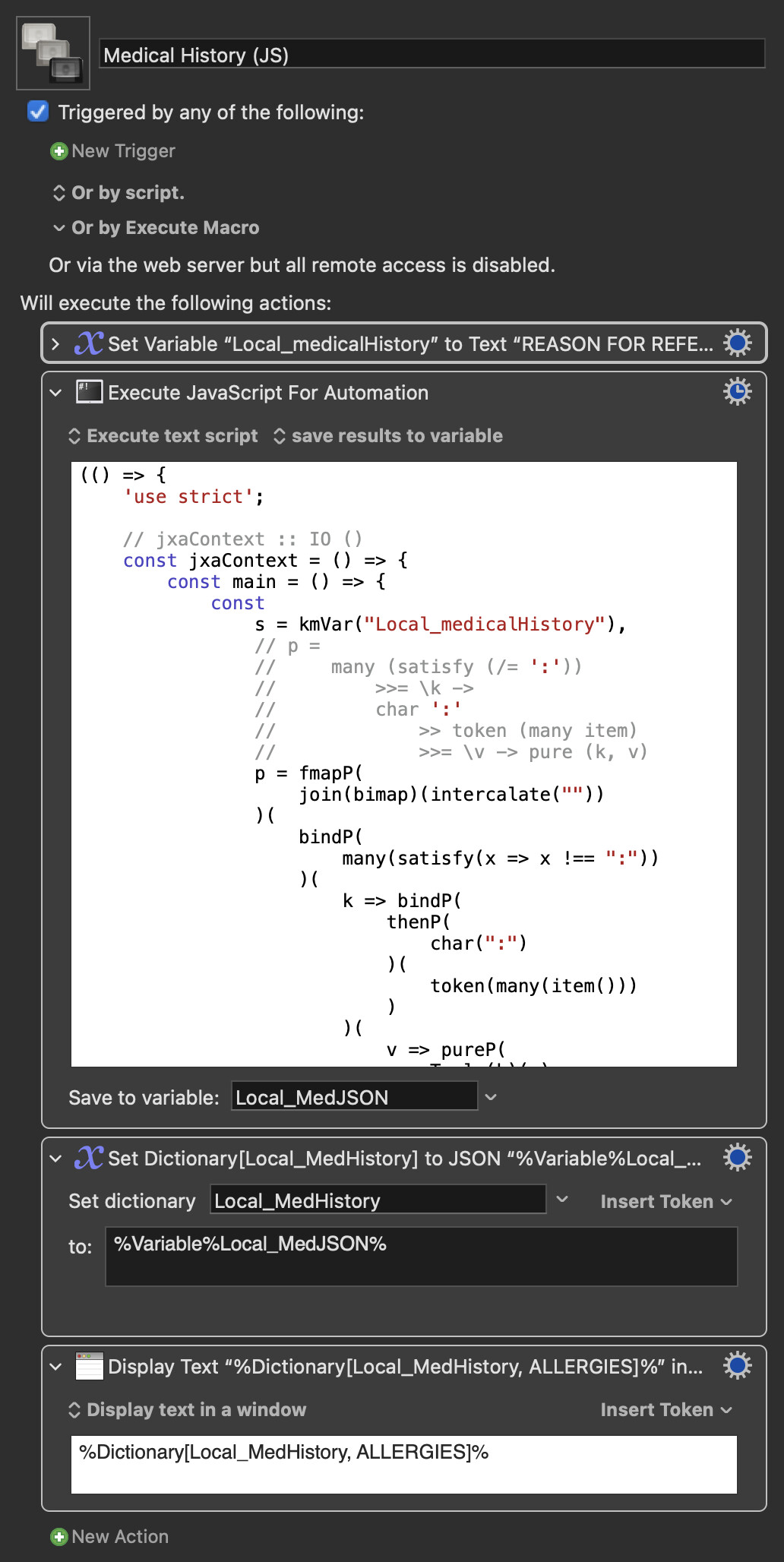
Adding to drdrang's perl script, here is a translation of my Haskell script using the excellent Rob Trew's library:
and Parser Combinators library (also by Rob Trew).
Expand disclosure triangle to view JS Source
(() => {
'use strict';
// jxaContext :: IO ()
const jxaContext = () => {
const main = () => {
const
s = kmVar("Local_medicalHistory"),
// p =
// many (satisfy (/= ':'))
// >>= \k ->
// char ':'
// >> token (many item)
// >>= \v -> pure (k, v)
p = fmapP(
join(bimap)(intercalate(""))
)(
bindP(
many(satisfy(x => x !== ":"))
)(
k => bindP(
thenP(
char(":")
)(
token(many(item()))
)
)(
v => pureP(
Tuple(k)(v)
)
)
)
)
return compose(
JSON.stringify,
dictFromList,
concatMap(compose(map(fst), parse(p))),
splitOn("\n\n")
)(s)
};
// GENERICS ----------------------------------------------------------------
// https://github.com/RobTrew/prelude-jxa
// JS For Automation -------------------------------------------
// kmVar :: String -> String
const kmVar = strVariable => {
const
kmInst = standardAdditions().systemAttribute("KMINSTANCE"),
kmeApp = Application("Keyboard Maestro Engine");
return kmeApp.getvariable(strVariable, {
instance: kmInst
});
};
// standardAdditions :: () -> Application
const standardAdditions = () =>
Object.assign(Application.currentApplication(), {
includeStandardAdditions: true
});
// JS Prelude --------------------------------------------------
// Just :: a -> Maybe a
const Just = x => ({
type: "Maybe",
Nothing: false,
Just: x
});
// Left :: a -> Either a b
const Left = x => ({
type: "Either",
Left: x
});
// Nothing :: Maybe a
const Nothing = () => ({
type: "Maybe",
Nothing: true
});
// Right :: b -> Either a b
const Right = x => ({
type: "Either",
Right: x
});
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
// A pair of values, possibly of
// different types.
b => ({
type: "Tuple",
"0": a,
"1": b,
length: 2,
*[Symbol.iterator]() {
for (const k in this) {
if (!isNaN(k)) {
yield this[k];
}
}
}
});
// all :: (a -> Bool) -> [a] -> Bool
const all = p =>
// True if p(x) holds for every x in xs.
xs => [...xs].every(p);
// and :: [Bool] -> Bool
const and = xs =>
// True unless any value in xs is false.
[...xs].every(Boolean);
// any :: (a -> Bool) -> [a] -> Bool
const any = p =>
// True if p(x) holds for at least
// one item in xs.
xs => [...xs].some(p);
// append (<>) :: [a] -> [a] -> [a]
const append = xs =>
// Two lists joined into one.
ys => xs.concat(ys);
// bimap :: (a -> b) -> (c -> d) -> (a, c) -> (b, d)
const bimap = f =>
// Tuple instance of bimap.
// A tuple of the application of f and g to the
// first and second values respectively.
g => tpl => Tuple(f(tpl[0]))(
g(tpl[1])
);
// bind (>>=) :: Monad m => m a -> (a -> m b) -> m b
const bind = m =>
// Two computations sequentially composed,
// with any value produced by the first
// passed as an argument to the second.
mf => Array.isArray(m) ? (
bindList(m)(mf)
) : (
({
"Either": () => bindLR,
"Maybe": () => bindMay,
"Tuple": () => bindTuple,
"function": () => bindFn
})[m.type || typeof m]()(m)(mf)
);
// bindFn (>>=) :: (a -> b) -> (b -> a -> c) -> a -> c
const bindFn = f =>
// Binary operator applied over f x and x.
op => x => op(f(x))(x);
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = lr =>
// Bind operator for the Either option type.
// If lr has a Left value then lr unchanged,
// otherwise the function mf applied to the
// Right value in lr.
mf => "Left" in lr ? (
lr
) : mf(lr.Right);
// bindList (>>=) :: [a] -> (a -> [b]) -> [b]
const bindList = xs =>
// The bind operator for Arrays.
mf => [...xs].flatMap(mf);
// bindMay (>>=) :: Maybe a -> (a -> Maybe b) -> Maybe b
const bindMay = mb =>
// Nothing if mb is Nothing, or the application of the
// (a -> Maybe b) function mf to the contents of mb.
mf => mb.Nothing ? (
mb
) : mf(mb.Just);
// bindTuple (>>=) :: Monoid a => (a, a) -> (a -> (a, b)) -> (a, b)
const bindTuple = ([a, b]) =>
// The bind operator for Tuples
f => first(mappend(a))(
f(b)
);
// both :: (a -> b) -> (a, a) -> (b, b)
const both = f =>
// A tuple obtained by applying f to both values
// in the given tuple.
([a, b]) => Tuple(
f(a)
)(
f(b)
);
// compose (<<<) :: (b -> c) -> (a -> b) -> a -> c
const compose = (...fs) =>
// A function defined by the right-to-left
// composition of all the functions in fs.
fs.reduce(
(f, g) => x => f(g(x)),
x => x
);
// concat :: [[a]] -> [a]
const concat = xs =>
xs.flat(1);
// concatMap :: (a -> [b]) -> [a] -> [b]
const concatMap = f =>
// Concatenated results of a map of f over xs.
// f is any function which returns a list value.
// Any empty lists returned are filtered out by
// the concatenation.
xs => xs.flatMap(f);
// dictFromList :: [(k, v)] -> Dict
const dictFromList = kvs =>
Object.fromEntries(kvs);
// findIndices :: (a -> Bool) -> [a] -> [Int]
// findIndices :: (String -> Bool) -> String -> [Int]
const findIndices = p =>
xs => {
const ys = [...xs];
return ys.flatMap(
(y, i) => p(y, i, ys) ? (
[i]
) : []
);
};
// first :: (a -> b) -> ((a, c) -> (b, c))
const first = f =>
// A simple function lifted to one which applies
// to a tuple, transforming only its first item.
([x, y]) => Tuple(f(x))(y);
// fst :: (a, b) -> a
const fst = tpl =>
// First member of a pair.
tpl[0];
// identity :: a -> a
const identity = x =>
// The identity function.
x;
// intercalate :: [a] -> [[a]] -> [a]
// intercalate :: String -> [String] -> String
const intercalate = sep => xs =>
0 < xs.length && "string" === typeof sep &&
"string" === typeof xs[0] ? (
xs.join(sep)
) : concat(intersperse(sep)(xs));
// intersperse :: a -> [a] -> [a]
// intersperse :: Char -> String -> String
const intersperse = sep => xs => {
// intersperse(0, [1,2,3]) -> [1, 0, 2, 0, 3]
const bln = "string" === typeof xs;
return xs.length > 1 ? (
(bln ? concat : x => x)(
(bln ? (
xs.split("")
) : xs)
.slice(1)
.reduce((a, x) => a.concat([sep, x]), [xs[0]])
)) : xs;
};
// isDigit :: Char -> Bool
const isDigit = c => {
const n = c.codePointAt(0);
return 48 <= n && 57 >= n;
};
// join :: Monad m => m (m a) -> m a
const join = x =>
bind(x)(identity);
// length :: [a] -> Int
const length = xs =>
// Returns Infinity over objects without finite
// length. This enables zip and zipWith to choose
// the shorter argument when one is non-finite,
// like cycle, repeat etc
"GeneratorFunction" !== xs.constructor
.constructor.name ? (
xs.length
) : Infinity;
// list :: StringOrArrayLike b => b -> [a]
const list = xs =>
// xs itself, if it is an Array,
// or an Array derived from xs.
Array.isArray(xs) ? (
xs
) : Array.from(xs || []);
// map :: (a -> b) -> [a] -> [b]
const map = f =>
// The list obtained by applying f
// to each element of xs.
// (The image of xs under f).
xs => [...xs].map(f);
// mappEndo (<>) :: Endo a -> Endo a -> Endo a
const mappEndo = a =>
// mappend is defined as composition
// for the Endo type.
b => Endo(x => a.appEndo(b.appEndo(x)));
// mappend (<>) :: Monoid a => a -> a -> a
const mappend = a =>
// Associative operation
// defined for various monoids.
({
"(a -> b)": () => mappendFn,
"Endo": () => mappEndo,
"List": () => append,
"Maybe": () => mappendMaybe,
"Num": () => mappendOrd,
"String": () => append,
"Tuple": () => mappendTupleN,
"TupleN": () => mappendTupleN
})[typeName(a)]()(a);
// mappendFn (<>) :: Monoid b => (a -> b) -> (a -> b) -> (a -> b)
const mappendFn = f =>
g => x => mappend(f(x))(
g(x)
);
// mappendMaybe (<>) :: Maybe a -> Maybe a -> Maybe a
const mappendMaybe = a =>
b => a.Nothing ? (
b
) : b.Nothing ? (
a
) : Just(
mappend(a.Just)(
b.Just
)
);
// mappendOrd (<>) :: Ordering -> Ordering -> Ordering
const mappendOrd = x =>
y => 0 !== x ? (
x
) : y;
// mappendTupleN (<>) ::
// (a, b, ...) -> (a, b, ...) -> (a, b, ...)
const mappendTupleN = t => t1 => {
const lng = t.length;
return lng === t1.length ? (
TupleN(
[...t].map(
(x, i) => mappend(x)(t1[i])
)
)
) : undefined;
};
// member :: Key -> Dict -> Bool
const member = k =>
// True if dict contains the key k.
dict => k in dict;
// negate :: Num -> Num
const negate = n =>
-n;
// or :: [Bool] -> Bool
const or = xs =>
xs.some(Boolean);
// read :: Read a => String -> a
const read = JSON.parse;
// repeat :: a -> Generator [a]
const repeat = function* (x) {
while (true) {
yield x;
}
};
// second :: (a -> b) -> ((c, a) -> (c, b))
const second = f =>
// A function over a simple value lifted
// to a function over a tuple.
// f (a, b) -> (a, f(b))
([x, y]) => Tuple(x)(f(y));
// splitOn :: [a] -> [a] -> [[a]]
// splitOn :: String -> String -> [String]
const splitOn = pat => src =>
// A list of the strings delimited by
// instances of a given pattern in s.
("string" === typeof src) ? (
src.split(pat)
) : (() => {
const
lng = pat.length,
[a, b] = findIndices(matching(pat))(src).reduce(
([x, y], i) => Tuple(
x.concat([src.slice(y, i)])
)(lng + i),
Tuple([])(0)
);
return a.concat([src.slice(b)]);
})();
// ParserCombinatorsJS -----------------------------------------
// Parser :: String -> [(a, String)] -> Parser a
const Parser = f =>
// A function lifted into a Parser object.
({
type: "Parser",
parser: f
});
// altP (<|>) :: Parser a -> Parser a -> Parser a
const altP = p =>
// p, or q if p doesn't match.
q => Parser(s => {
const xs = parse(p)(s);
return 0 < xs.length ? (
xs
) : parse(q)(s);
});
// apP <*> :: Parser (a -> b) -> Parser a -> Parser b
const apP = pf =>
// A new parser obtained by the application
// of a Parser-wrapped function,
// to a Parser-wrapped value.
p => Parser(
s => parse(pf)(s).flatMap(
([v, r]) => parse(
fmapP(v)(p)
)(r)
)
);
// between :: Parser open -> Parser close ->
// Parser a -> Parser a
const between = pOpen =>
// A version of p which matches between
// pOpen and pClose (both discarded).
pClose => p => thenBindP(pOpen)(
p
)(
compose(thenP(pClose), pureP)
);
// bindP (>>=) :: Parser a ->
// (a -> Parser b) -> Parser b
const bindP = p =>
// A new parser obtained by the application of
// a function to a Parser-wrapped value.
// The function must enrich its output, lifting it
// into a new Parser.
// Allows for the nesting of parsers.
f => Parser(
s => parse(p)(s).flatMap(
([x, r]) => parse(f(x))(r)
)
);
// char :: Char -> Parser Char
const char = x =>
// A particular single character.
satisfy(c => x === c);
// decimal :: () -> Parser Number
const decimal = () => {
// The value of a decimal number string.
const
digitsOrZero = altP(
fmapP(concat)(some(digit()))
)(pureP("0"));
return bindP(
token(sign())
)(f => bindP(
digitsOrZero
)(ns => thenBindP(char("."))(
digitsOrZero
)(ds => pureP(f(read(`${ns}.${ds}`))))));
};
// digit :: Parser Char
const digit = () =>
// A single digit.
satisfy(isDigit);
// fmapP :: (a -> b) -> Parser a -> Parser b
const fmapP = f =>
// A new parser derived by the structure-preserving
// application of f to the value in p.
p => Parser(
s => parse(p)(s).flatMap(
first(f)
)
);
// integer :: () -> Parser Integer
const integer = () =>
// Signed integer value.
bindP(
token(sign())
)(f => bindP(
naturalNumber()
)(x => pureP(f(x))));
// item :: () -> Parser Char
const item = () =>
// A single character.
Parser(s => {
const [h, ...t] = s;
return Boolean(h) ? [
Tuple(h)(t)
] : [];
});
// liftA2P :: (a -> b -> c) ->
// Parser a -> Parser b -> Parser c
const liftA2P = op =>
// The binary function op, lifted
// to a function over two parsers.
p => apP(fmapP(op)(p));
// many :: Parser a -> Parser [a]
const many = p => {
// Zero or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const someP = q =>
liftA2P(
x => xs => [x].concat(xs)
)(q)(many(q));
return Parser(
s => parse(
0 < s.length ? (
altP(someP(p))(pureP([]))
) : pureP([])
)(s)
);
};
// naturalNumber :: () -> Parser Natural Number
const naturalNumber = () =>
// The value of an unsigned integer.
fmapP(
x => read(concat(x))
)(
some(digit())
);
// number :: Parser Number
const number = () =>
// The value of a signed number, with or
// without a floating point component.
altP(
decimal()
)(
integer()
);
// oneOf :: [Char] -> Parser Char
const oneOf = s =>
// One instance of any character found
// the given string.
satisfy(c => s.includes(c));
// option :: a -> Parser a -> Parser a
const option = x =>
// Either p or the default value x.
p => altP(p)(pureP(x));
// parse :: Parser a -> String -> [(a, String)]
const parse = p =>
// The result of parsing s with p.
s => p.parser([...s]);
// pureP :: a -> Parser a
const pureP = x =>
// The value x lifted, unchanged,
// into the Parser monad.
Parser(s => [Tuple(x)(s)]);
// satisfy :: (Char -> Bool) -> Parser Char
const satisfy = test =>
// Any character for which the
// given predicate returns true.
Parser(s => {
const [h, ...t] = s;
return Boolean(h) ? (
test(h) ? [
Tuple(h)(t)
] : []
) : [];
});
// sequenceP :: [Parser a] -> Parser [a]
const sequenceP = ps =>
// A single parser for a list of values, derived
// from a list of parsers for single values.
Parser(
s => ps.reduce(
(a, q) => a.flatMap(
([v, r]) => parse(q)(r).flatMap(
first(xs => v.concat(xs))
)
),
[Tuple([])(s)]
)
);
// sign :: () -> Parser Function
const sign = () =>
// The negate function as a parse of
// any '-', or the identity function.
altP(
bindP(
oneOf("+-")
)(c => pureP(
("-" !== c) ? identity : negate
))
)(pureP(identity));
// some :: Parser a -> Parser [a]
const some = p => {
// One or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const manyP = q =>
altP(some(q))(pureP([]));
return Parser(
s => parse(
liftA2P(
x => xs => [x].concat(xs)
)(p)(manyP(p))
)(s)
);
};
// string :: String -> Parser String
const string = s =>
// A particular string.
fmapP(cs => cs.join(""))(
sequenceP([...s].map(char))
);
// thenBindP :: Parser a -> Parser b ->
// (b -> Parser c) Parser c
const thenBindP = o =>
// A combination of thenP and bindP in which a
// preliminary parser consumes text and discards
// its output, before any output of a subsequent
// parser is bound.
p => f => Parser(
s => parse(o)(s).flatMap(
([, r]) => parse(p)(r).flatMap(
([a, b]) => parse(f(a))(b)
)
)
);
// thenP (>>) :: Parser a -> Parser b -> Parser b
const thenP = o =>
// A composite parser in which o just consumes text
// and then p consumes more and returns a value.
p => Parser(
s => parse(o)(s).flatMap(
([, r]) => parse(p)(r)
)
);
// token :: Parser a -> Parser a
const token = p => {
// A new parser for a space-wrapped
// instance of p. Any flanking
// white space is discarded.
const space = whiteSpace();
return between(space)(space)(p);
};
// whiteSpace :: Parser String
const whiteSpace = () =>
// Zero or more non-printing characters.
many(oneOf(" \t\n\r"));
// MAIN --
return main();
};
return jxaContext();
})();