HI griffman
I will paste them in NeoOffice on mac which has the same functionality as Excel
There will not necessarily be an x-number on every line.
No line will have just numbers.
Thanks for your help
Thanks for the clarification, but this part confuses me a bit. If there won't necessarily be x-numbers on every line, but no line will have just numbers ... what will be on those other lines, and does that also need to be pasted?
Sorry for all the questions, but it's best to have a good understanding of the data's structure and your objectives before trying to provide a solution.
I'm copying it from an email and it will always be effectively in one column (although it's just text with return after each line of text rather than in a table at that point)
Looking at the table I posted at the start of the thread the words should end up in column 1 and the x numbers go in column 3.
Macros are always disabled when imported into the Keyboard Maestro Editor.
The user must ensure the macro is enabled.
The user must also ensure the macro's parent macro-group is enabled.
System information
macOS 14.4.1
Keyboard Maestro v11.0.2
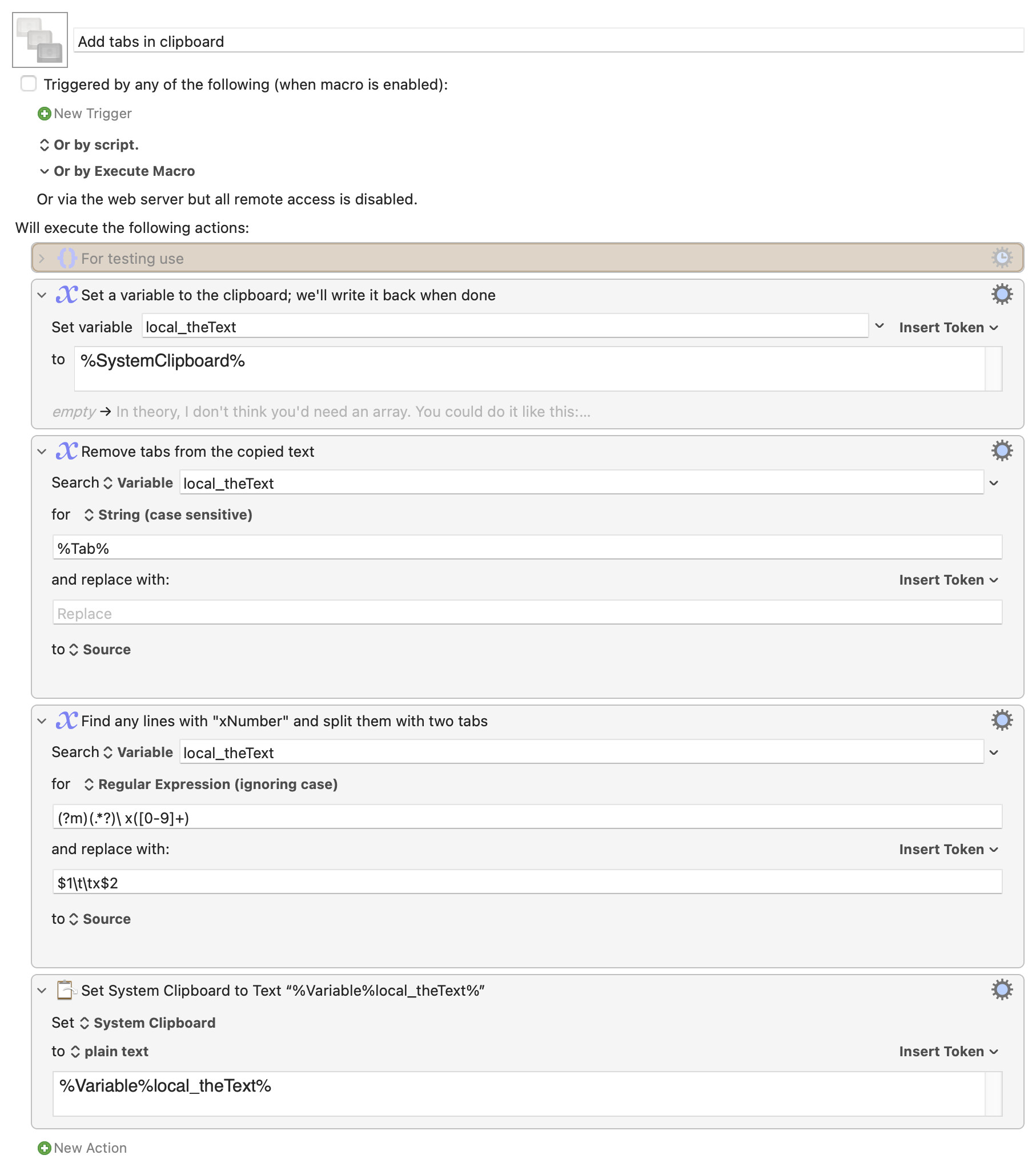
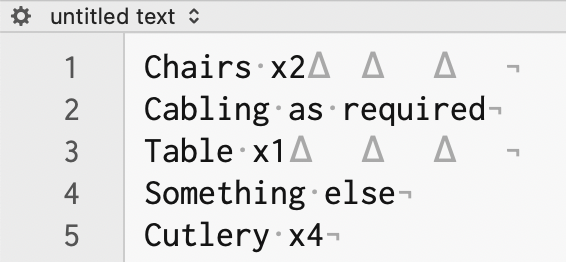
I copied your data above, and added a couple "non x" rows for testing:
The triangles are tabs, so you can see there were some in the copied text. The macro first removes those, then uses a regular expression to find and add tabs before any rows with "x and numbers" in it. Here's how the data looks after the run:
Two tabs before any "x" numbers, and the non-x rows were left alone. In theory, this should then paste right into NeoOffice.
Sorry, I didn't read that you wanted the macro to do the actual pasting, so it doesn't—I just thought you wanted it ready to paste. You should be able to just add a keystroke action to send Command-V as the last step in the macro.
I'm trying to understand how it works.
The action that you called "Find any lines with "xNumber" and split them with two tabs"
using the expressions:
(?m)(.*?)\ x([0-9]+)
and replace with
$1\t\tx$2
How does that work?
If you have time to describe I'd be grateful to learn!
The only characters I understand are literally just "x[0-9] "
Thank you again!
Edit: I understand \t\tx is two tabs followed by x
That's a regular expression, and they are powerful, complicated, obtuse, and finicky :). Often there are better ways to do things, but they can solve many unique text problems. They're complex enough that there are literally books about them, and countless sites where you can read and learn about them. (I wrote a beginner's guide to regular expressions, which works through an example and has links to some sources.)
This particular one breaks down like this:
(?m): This enables multiple line mode, so that the expression works on each line of the text, instead of treating it as one blob.
(.*?): The parentheses create something called a capture group, which you can think of as a variable. The first set are assigned to $1, the next to $2, etc. Within those parentheses, the dot-star-question mark means "capture any characters up to whatever is specified next" (after the "?" and outside the parentheses).
.
The capture is done in a non-greedy manner, which is a subject in its own right. The question mark probably wasn't needed here, but I tend to prefer non-greedy captures to make sure only what I want to capture is captured.
\[space]x: The first two bits are just a space character, which needs to be escaped with a backslash in some dialects of regular expressions. I probably didn't need it in Keyboard Maestro, but put it in by force of habit :). Then the 'x' is listed.
.
This defines the pattern where the first capture group will end: It stops capturing when it finds the space followed by an 'x'. So what we wind up with is $1 holding all the text before the space-x.
([0-9]+): This is our second set of parentheses (to create $2). Within those parentheses, we have a character class, which is set here to "find any character between 0 and 9, occurring after the 'x'." (You can also use [A-Z] or [a-z] and some others.) The plus sign means "at least one, but up to however many there are."
.
This puts the number into the second capture group.
The replacement is then just the first capture group ($1, the text), two tabs, the 'x' character (because I didn't capture that, though I could have), and then the number (the second capture group, $2).