ALYB
December 5, 2021, 6:19pm
1
I'm looking for a way to split tab-delimited term pairs where the source terms (at the left-hand side of the tab) are separated by a semicolon, in such a way that every source term gets the full bunch of corresponding target terms (from the right-hand side of the tab).
Example:
bauliche;baulicher;baulichen;baulichem\tstructurele
Bauteiloberflächen;Bauteil-Oberflächen\tcomponentoppervlakken
Befestigungsbolzen;Befestigungs-Bolzen\tbevestigingsbout;bevestigingspen;bevestigingsbouten;bevestigingspennen
Beispielberechnung;Beispiel-Berechnung\tvoorbeeldberekening
Beispielstückliste;Beispiel-Stückliste\tvoorbeeld-stuklijst
benannte;benannter;benannten;benanntem\taangewezen;aangestelde;benoemde
(Where \t represents a tab stop.)
Should become:
bauliche\tstructurele
baulicher\tstructurele
baulichen\tstructurele
baulichem\tstructurele
Bauteiloberflächen\tcomponentoppervlakken
Bauteil-Oberflächen\tcomponentoppervlakken
Befestigungsbolzen\tbevestigingsbout;bevestigingspen;bevestigingsbouten;bevestigingspennen
Befestigungs-Bolzen\tbevestigingsbout;bevestigingspen;bevestigingsbouten;bevestigingspennen
Beispielberechnung\tvoorbeeldberekening
Beispiel-Berechnung\tvoorbeeldberekening
Beispielstückliste\tvoorbeeld-stuklijst
Beispiel-Stückliste\tvoorbeeld-stuklijst
benannte\taangewezen;aangestelde;benoemde
benannter\taangewezen;aangestelde;benoemde
benannten\taangewezen;aangestelde;benoemde
benanntem\taangewezen;aangestelde;benoemde
Sleepy
December 5, 2021, 6:58pm
2
That seems to be a clear example. How much data are you dealing with? If it's a large quantity of data, you should be using a macOS utility like awk.
As @Sleepy says, awk would certainly work. Because I'm more familiar with Perl syntax, this is how I'd do it:
#!/usr/bin/perl
while (<>){
chomp;
($lhs, $rhs) = split /\t/;
foreach $s (split /;/, $lhs){
print "$s\t$rhs\n";
}
}
How you send the input to this script and what you do with its output is up to you.
1 Like
gglick
December 5, 2021, 7:24pm
4
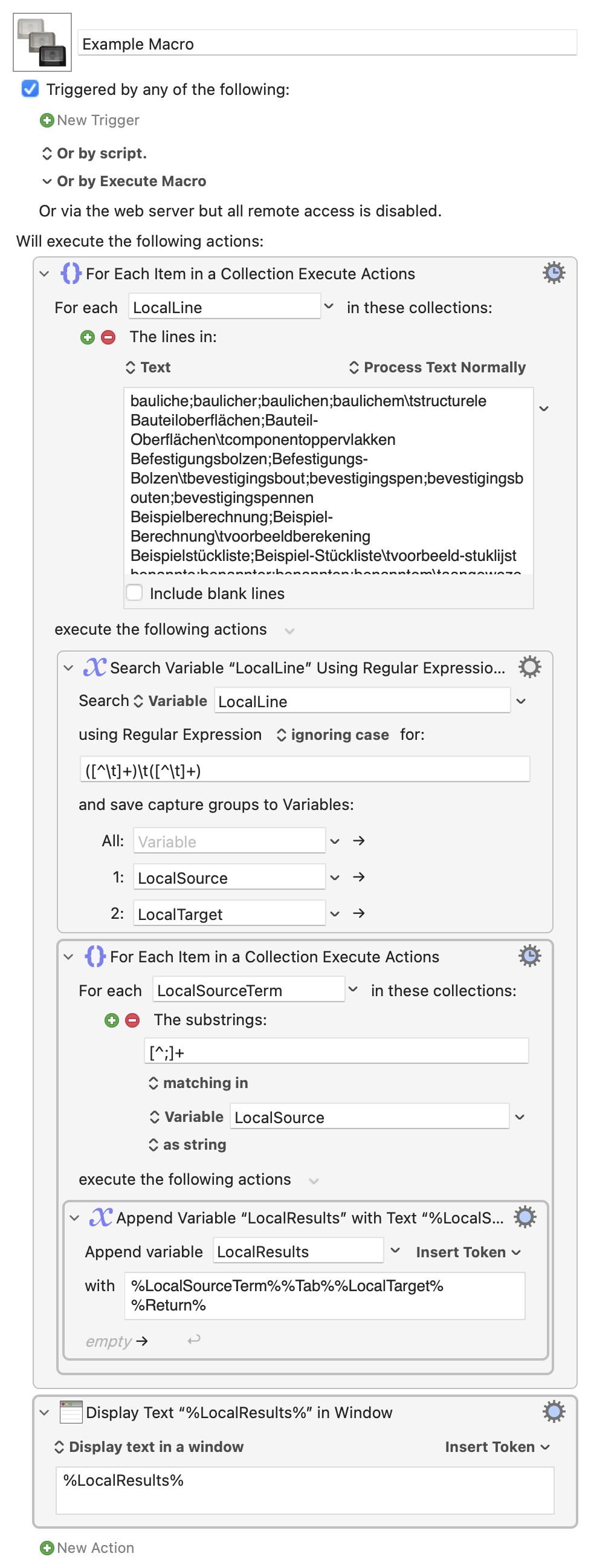
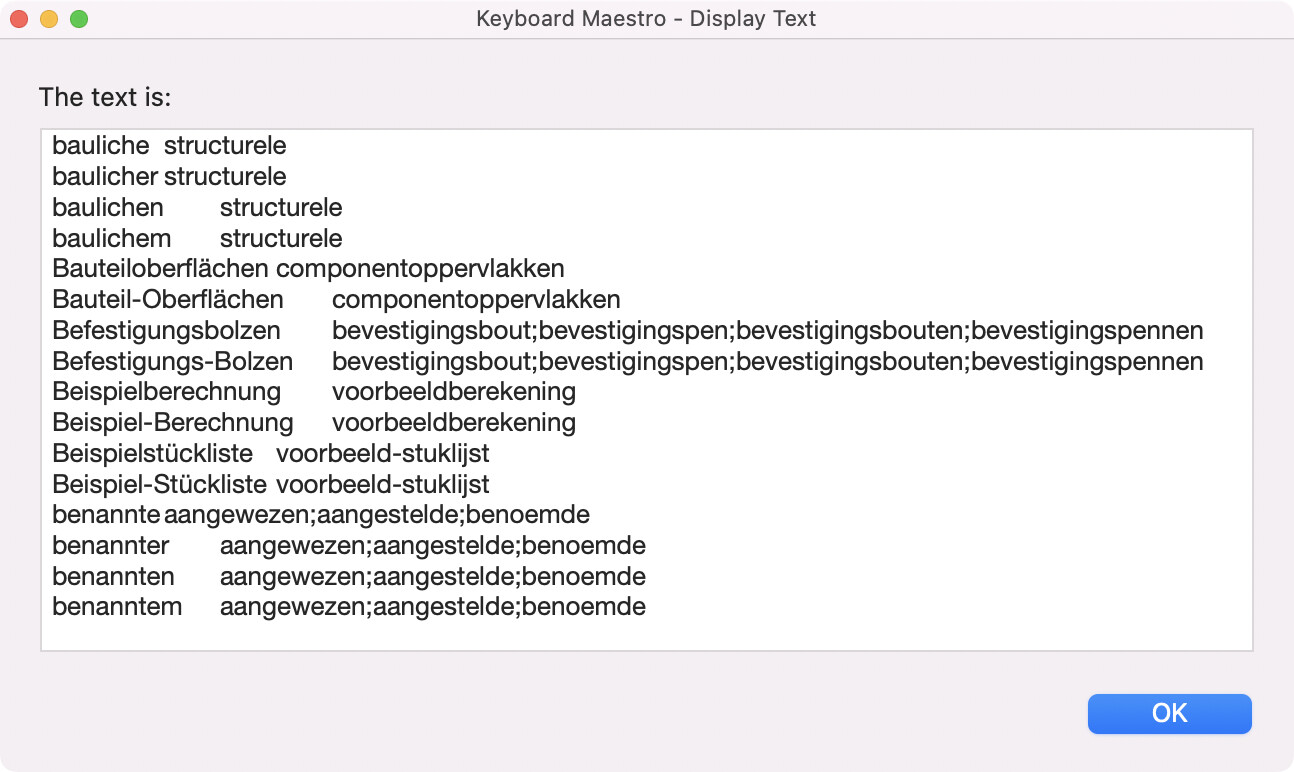
For good measure, an example with KM native actions:
Example Macro.kmmacros (5.0 KB)
Results
baulicher structurele
baulichen structurele
baulichem structurele
Bauteiloberflächen componentoppervlakken
Bauteil-Oberflächen componentoppervlakken
Befestigungsbolzen bevestigingsbout;bevestigingspen;bevestigingsbouten;bevestigingspennen
Befestigungs-Bolzen bevestigingsbout;bevestigingspen;bevestigingsbouten;bevestigingspennen
Beispielberechnung voorbeeldberekening
Beispiel-Berechnung voorbeeldberekening
Beispielstückliste voorbeeld-stuklijst
Beispiel-Stückliste voorbeeld-stuklijst
benannte aangewezen;aangestelde;benoemde
benannter aangewezen;aangestelde;benoemde
benannten aangewezen;aangestelde;benoemde
benanntem aangewezen;aangestelde;benoemde
1 Like
Sleepy
December 5, 2021, 7:25pm
5
Amazing work (both of you guys). I did ask the user how much data he had, and he didn't answer yet. Since KM works at 1.002 KHz, that may make Perl or awk better for large data amounts.
1 Like
ALYB
December 6, 2021, 4:54am
6
I have to split about 9000 lines to clean up my glossary. This is a one-time operation.
In the future, I’ll be dealing with smaller files of about 100 lines.
Sleepy
December 6, 2021, 4:56am
7
That seems like a small quantity. At least for the ongoing basis.
ALYB
December 6, 2021, 4:56am
8
Thank you. Could you please show me how I can send the content of glossary.txt (UTF-8, Unix LF) to the script in the Terminal?
ALYB
December 6, 2021, 4:58am
9
Thank you. I’ll add this KM solution to my cleaning macro for cleaning up on a regular basis. Much appreciated!
1 Like
ccstone
December 6, 2021, 5:51am
10
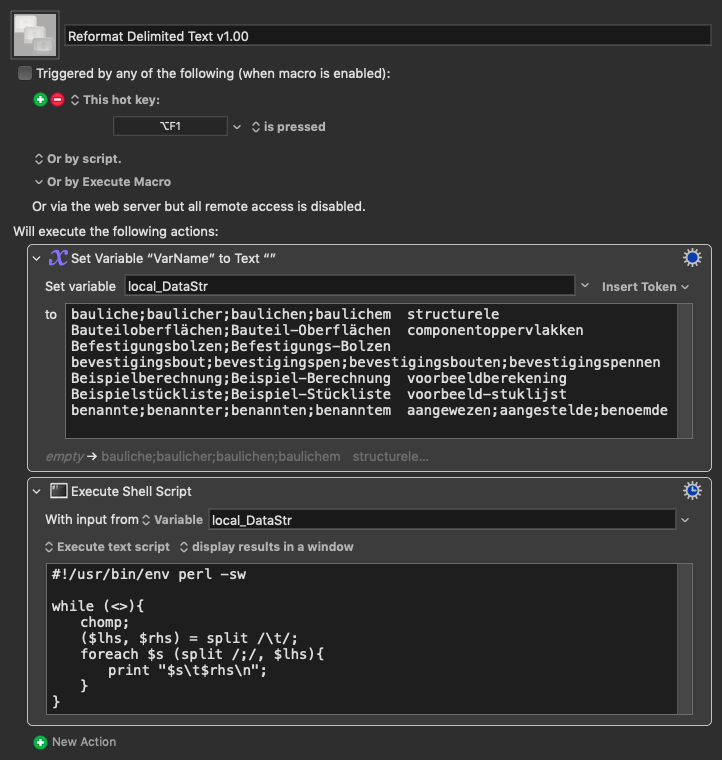
Hey Hans,
You don't need to use the Terminal.app; you can use an Execute a Shell Script action.
-Chris
Reformat Delimited Text v1.00.kmmacros (2.8 KB)
1 Like
drdrang
December 6, 2021, 12:40pm
11
Put a copy of the glossary.txt file on your Desktop.
Use a plain text editor to create a file called splitterms.pl. Copy the Perl script above into it and save it to your Desktop.
Open Terminal and execute the following two lines:cd ~/Desktop
perl splitterms.pl glossary.txt > newglossary.txt
The file newglossary.txt will appear on your Desktop in the format you want.
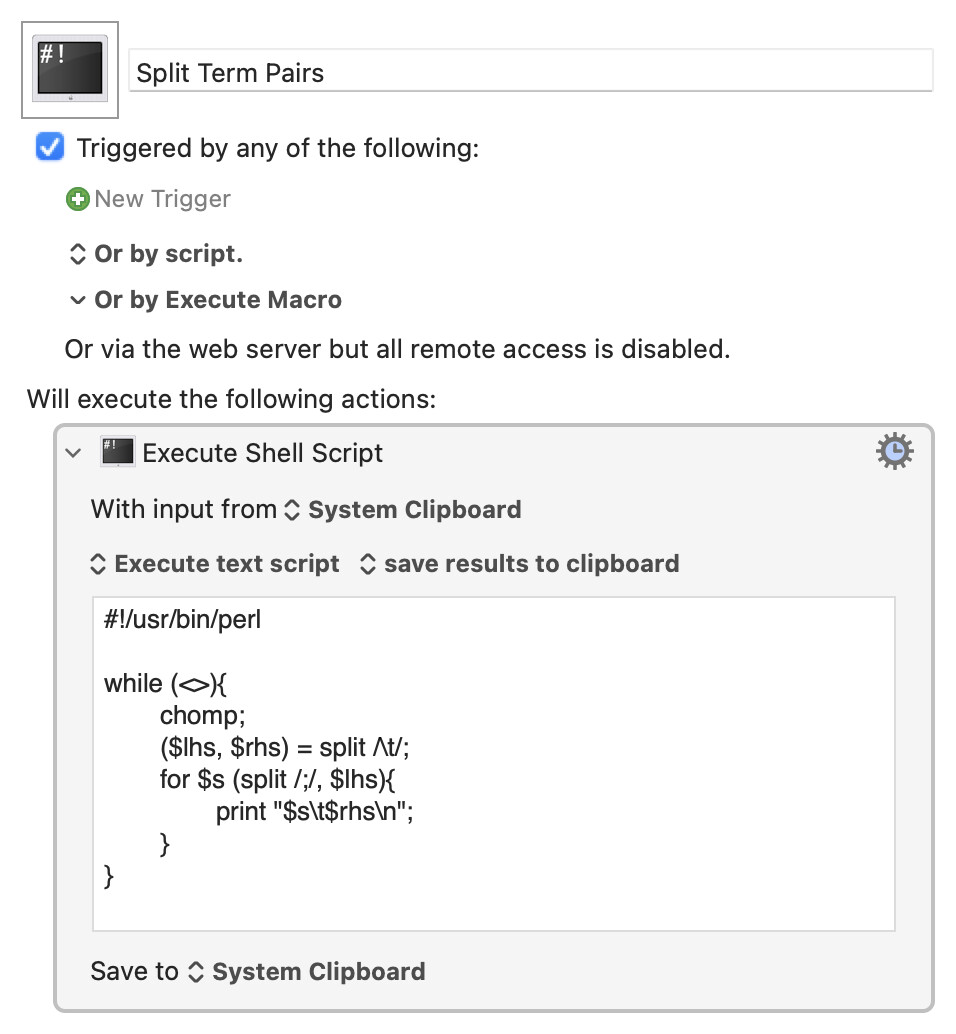
In the future, when you don't have so many lines to split, it might be easier to copy your glossary lines to the Clipboard and run this macro, which will do the conversion and put the results back on the Clipboard.
Split Term Pairs.kmmacros (1.7 KB)
1 Like
and in JavaScript for Automation:
// termPairs :: String -> String
const termPairs = s =>
lines(s).flatMap(x => {
const [l, r] = x.split("\t");
return l.split(";").map(
k => `${k}\t${r}`
);
})
.join("\n");
So, for example:
Tab-Delimited Term Pair Splits.kmmacros (3.1 KB)
Expand disclosure triangle to view JS Source
(() => {
"use strict";
// termPairs :: String -> String
const termPairs = s =>
lines(s).flatMap(x => {
const [l, r] = x.split("\t");
return l.split(";").map(
k => `${k}\t${r}`
);
})
.join("\n");
// ---------------------- TEST -----------------------
const main = () =>
termPairs(
Application("Keyboard Maestro Engine")
.getvariable("termSample")
);
// --------------------- GENERIC ---------------------
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single
// string delimited by newline and or CR.
0 < s.length ? (
s.split(/[\r\n]+/u)
) : [];
return main();
})();
1 Like
ALYB
December 28, 2021, 12:49pm
13
Wow, the Terminal solution is very fast.
Also thanks for the Clipboard variant!
ALYB
December 30, 2021, 11:58am
14
To split target-side variants of term pairs, I've amended your script like this:
#!/usr/bin/perl
while (<>){
chomp;
($lhs, $rhs) = split /\t/;
foreach $s (split /;/, $rhs){
print "$lhs\t$s\n";
}
}
It works fine.
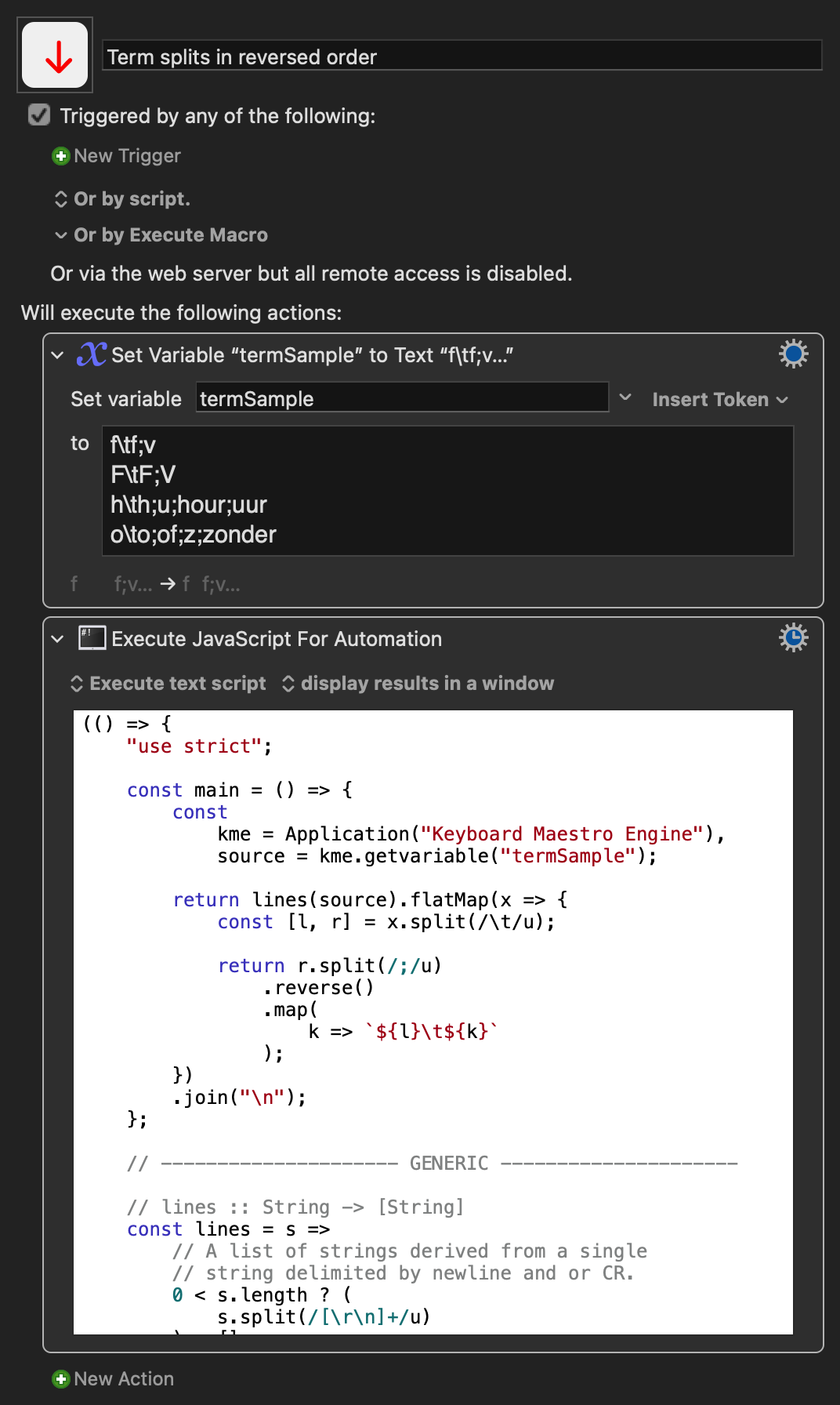
However, my CAT tool requires the order of the lines with extracted target terms reversed.
Test file:
f\tf;v
F\tF;V
h\th;u;hour;uur
o\to;of;z;zonder
Current order of the target terms:
f\tf
f\tv
F\tF
F\tV
h\th
h\tu
h\thour
h\tuur
o\to
o\tof
o\tz
o\tzonder
Required order of the extracted target terms (= reversed):
f\tv
f\tf
F\tV
F\tF
h\tuur
h\thour
h\tu
h\th
o\tzonder
o\tz
o\tof
o\to
Could you please help me once again with a modification of the script to get the order of the target terms reversed?test file.txt.zip (586 Bytes)
the target terms reversed
All of these languages have a list reverse function / operator, which you can apply to the output of the semicolon splitting.
@drdrang will show you where to apply the Perl reverse function
One approach to the JS equivalent would look like this:
return lines(source).flatMap(x => {
const [l, r] = x.split(/\t/u);
return r.split(/;/u)
.reverse()
.map(
k => `${l}\t${k}`
);
})
.join("\n");
Term splits in reversed order.kmmacros (2.7 KB)
Expand disclosure triangle to view a possible Perl variant
#!/usr/bin/perl
while (<>){
chomp;
($lhs, $rhs) = split /\t/;
foreach $s (reverse split /;/, $rhs){
print "$lhs\t$s\n";
}
}
drdrang
December 30, 2021, 2:48pm
16
We could slip a call to reverse into the for line, but I think things are getting complicated enough to be more explicit. Try this:
#!/usr/bin/perl
while (<>){
chomp;
($lhs, $rhs) = split /\t/;
@targets = split /;/, $rhs;
@targets = reverse @targets;
foreach $s (@targets){
print "$lhs\t$s\n";
}
}
It does the split and reversal of the right-hand side in two steps. If you ever decide you don't want the reversal, you can comment out that line.
1 Like