Visualisation with Graphviz3.kmmacros (14.5 KB) Hi!
I'm using a Software similar to nvALT for note-taking and have been busy building a KM macro to visualise links between my notes with Graphviz. The title of one of my notes (=basename of its file) always consists of a unique ID (12 digits) and a name after that, e.g. "201008192344 On Breadbaking". When I link to a note from within another note, the link always looks like this: "[[123456789012]]" – the number in brackets is the unique ID of the note I want to link to.
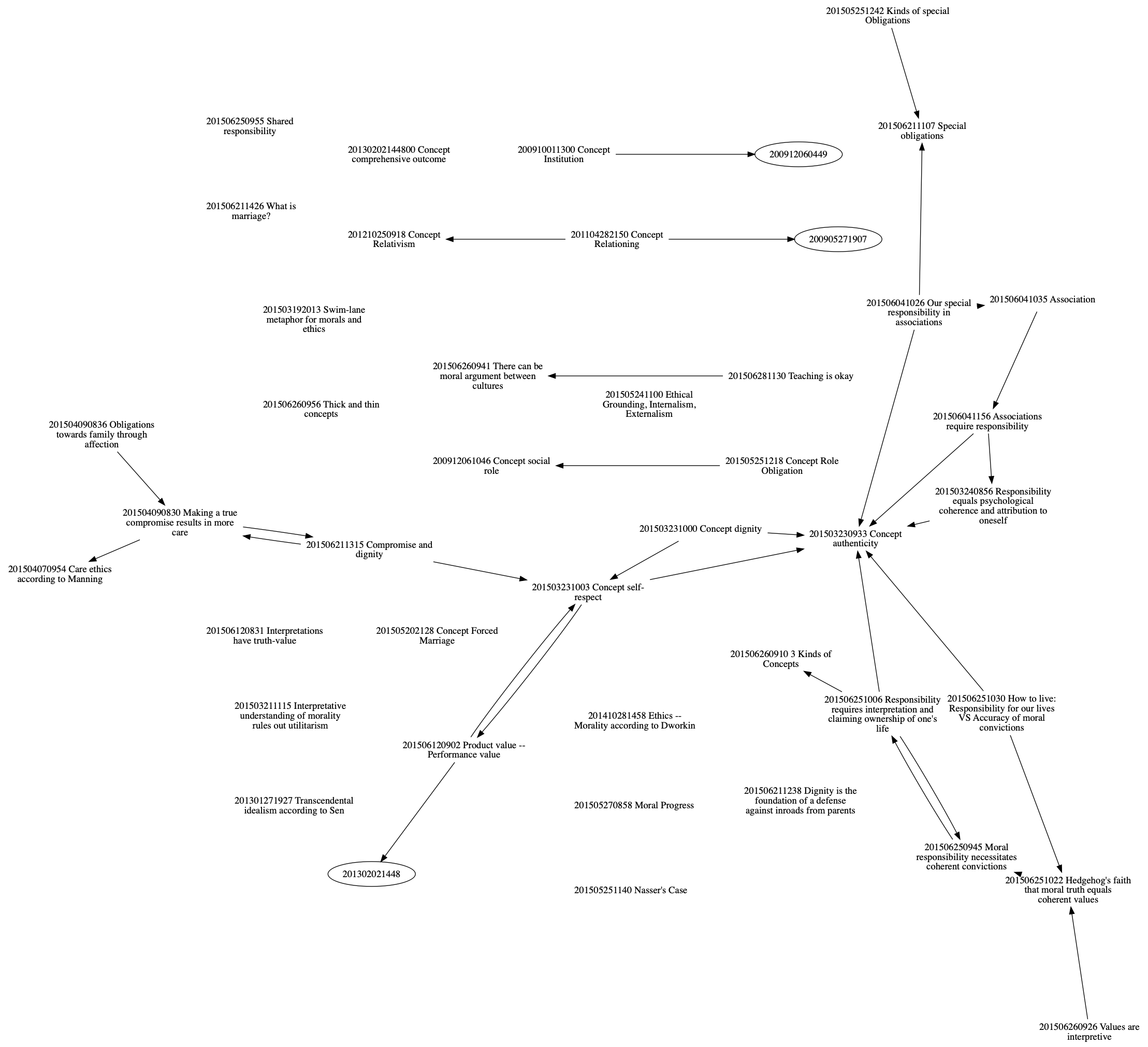
The macro I wrote is fed with a list of note-titles I select in my note-taking software and then uses these to build a .dot-file that can then be made into a graph showing individual note-titles as nodes with arrows that point to all the notes they link to. This is an example of a possible outcome:
The KM macro roughly does the following if I select a number of notes in the note list of my software and trigger it:
- It copies the note titles selected (each note title in a new line)
- It uses the list of selected notes, their unique IDs (UIDs) and their verbal descriptions to make a list of all the nodes and a list of all the relations between them (links) for the .dot-file
- It creates the .dot-file and makes a .svg-file out of it.
- It opens the .svg-file in the browser.
Step 2 is the most complicated step. The macro will go through each of the selected note titles and amongst other things search the associated file for links to other notes – it searches for the RegEx (?<=\[\[)[0-9]{12}(?=\]\]). For each of the search results, it then determines whether the found UID belongs to
a) the note it was found in (then it is ignored),
b) the list of selected notes (then the associated note will be displayed with its verbal description in the final graph)
c) or other non-selected notes (the user can choose whether to show these in the final graph at all and if they are shown their nodes will only show their UID).
In the case of b), the macro performs the RegEx search (?<=^%linkID%\ ).+ in the list of selected note titles to associate each note with its verbal description rather than its UID. This step causes a problem I can't explain at all – the macro will often be cancelled and show the error "Search Regular Expression failed to match (?<=^%linkID%\ ).+". Strangely, this error isn't tied to particular notes (sometimes they work, sometimes they don't), but it seems to depend on the note list I select. Does anyone have an idea of what's going wrong here?
To provide more information: This is a list of notes that works:
201903201647 SHYoung [HWT] Improving Critical Thinking
201903201645 [HWT] Improving Critical Thinking
201903090914 [DEF] Life
201903020926 [EXPL] Climate Change
201902231419 [DEF] Spirituality
201901102147 [DEF] Sustainability
201901071530 Basic Income Discussion
201811251200 [DEF] Wisdom
This list of notes (just one more at the beginning) doesn't work. The macro runs through the first two notes just fine and is cancelled when doing the RegEx search (?<=^%linkID%\ ).+ for the UID 201903201647 found in the third note – something that worked without problems in the first list above. The new (first) note in this list doesn't contain any links to other notes:
201904101954 [DEF] Essential nutrients for an organism
201903201647 SHYoung [HWT] Improving Critical Thinking
201903201645 [HWT] Improving Critical Thinking
201903090914 [DEF] Life
201903020926 [EXPL] Climate Change
201902231419 [DEF] Spirituality
201901102147 [DEF] Sustainability
201901071530 Basic Income Discussion
201811251200 [DEF] Wisdom
I've also attached an image of the macro (the problematic step is red).


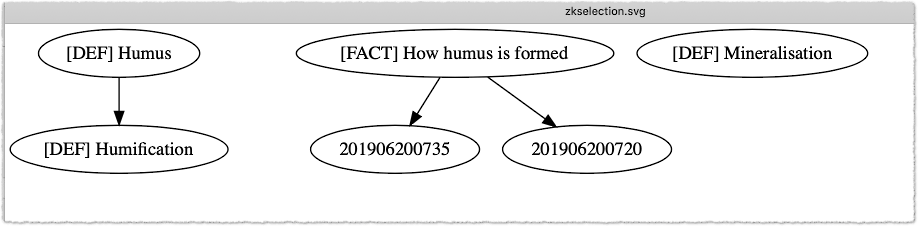
 The two arrows from the note “[DEF] Humification” are missing...
The two arrows from the note “[DEF] Humification” are missing...