Keyboard Maestro users wanting to extract parts and strings from XML may struggle to find general Regular Expression solutions. XML consists of nested tags, and regular expressions can't model recursive patterns.
XQuery (a W3C query language built into macOS) can make things quite a lot easier.
XQuery Book 1st Edition (XQuery 1.0)
Apple's introduction: Querying an XML Document
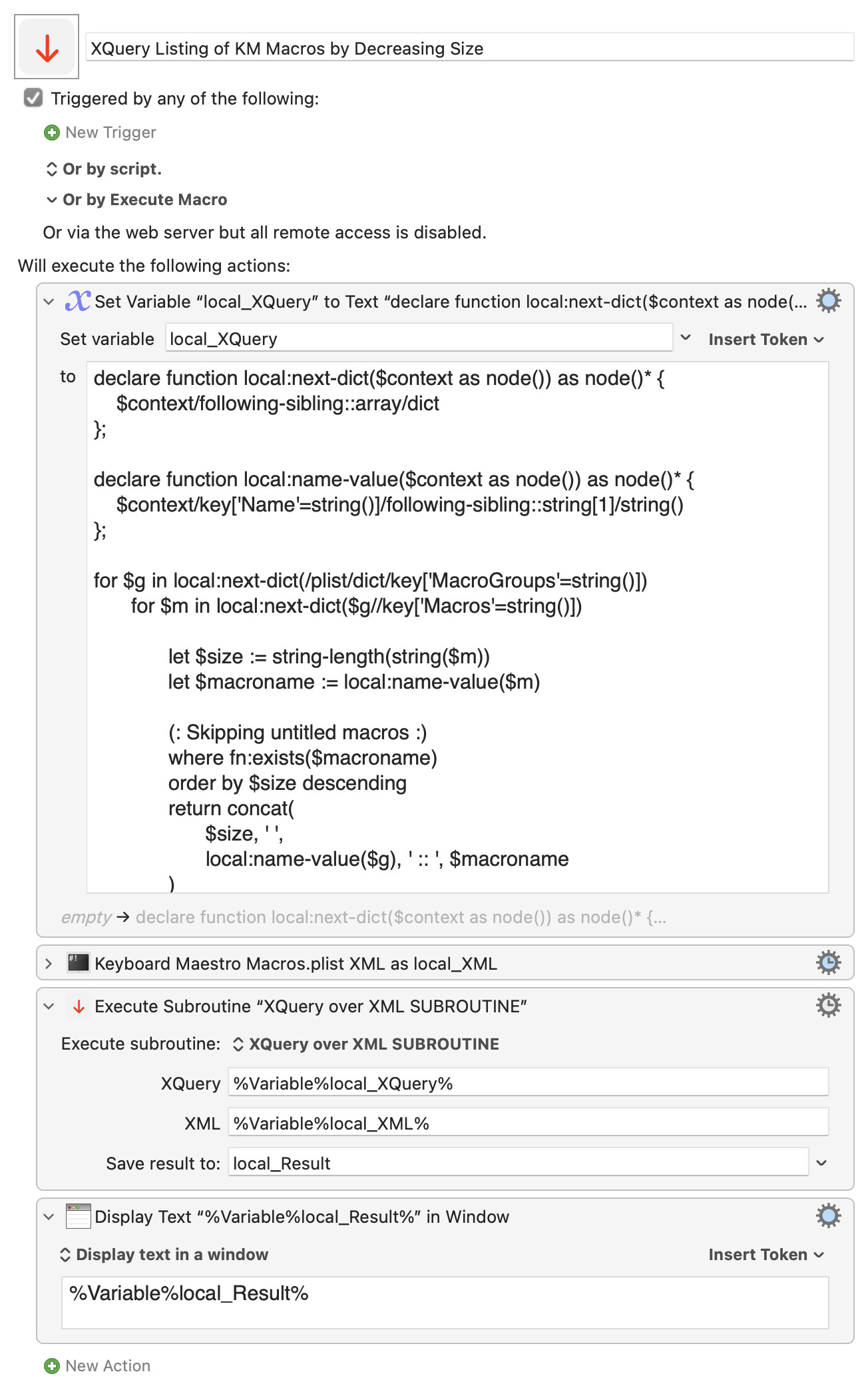
Here is a subroutine (with an example macro) which applies any XQuery 1.0 expression to a Keyboard Maestro variable containing an XML document, and returns the results.
- The XML sample is kindly provided by @ALYB.
- The version of XQuery built into macOS is 1.0
- To run the sample test macro, you also need to have the subroutine somewhere in an activated group
- Some basic examples of XQuery expressions are explained below
UPDATED to version 0.7
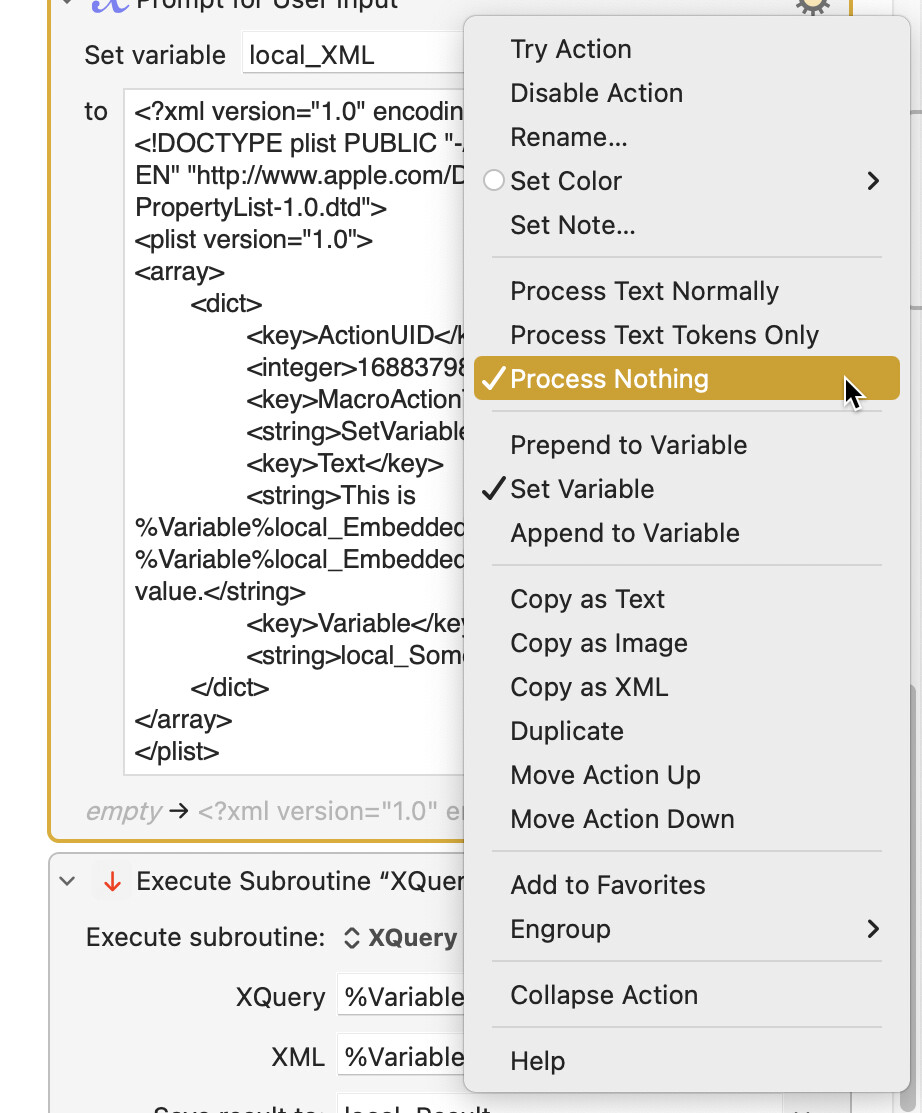
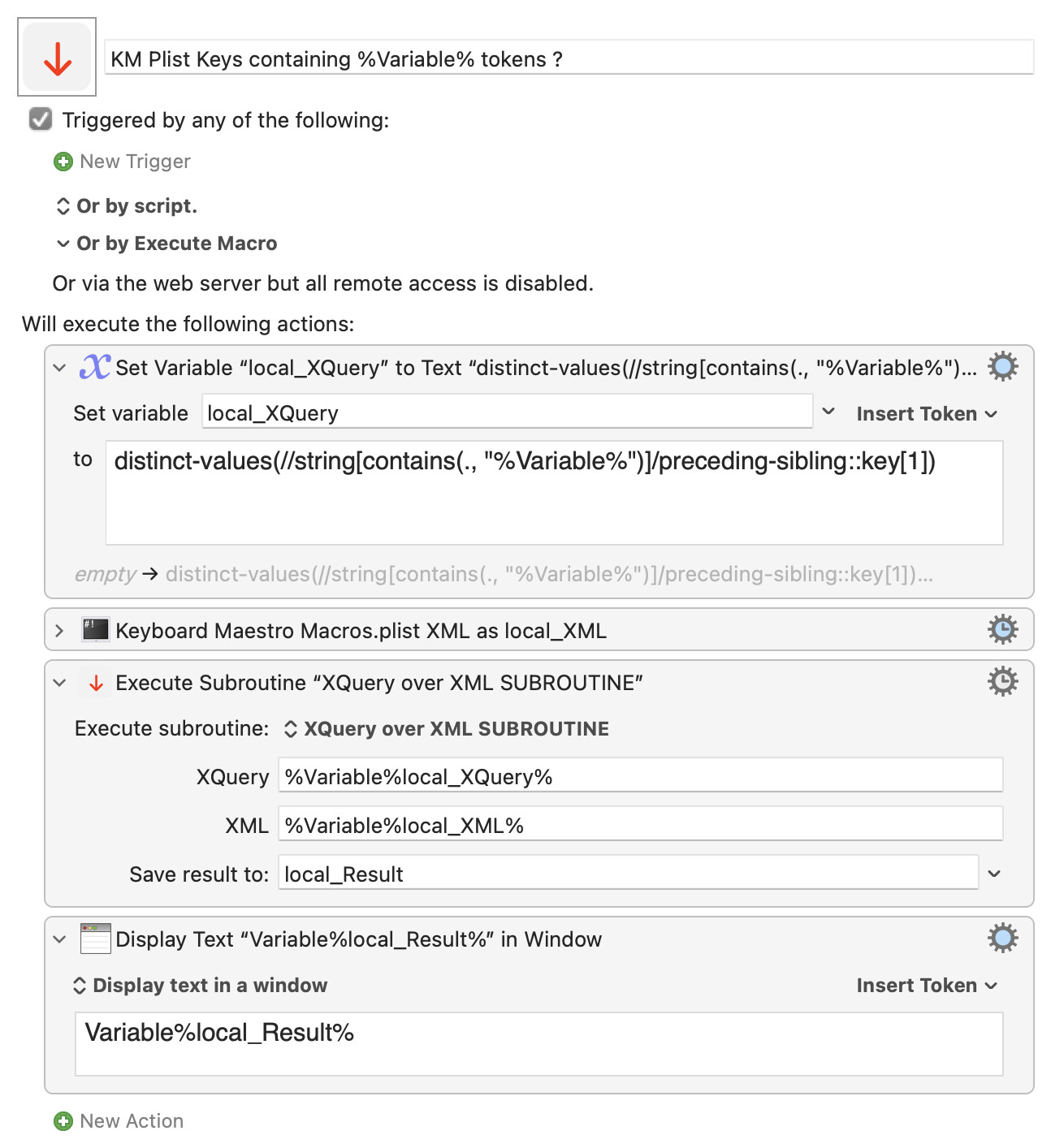
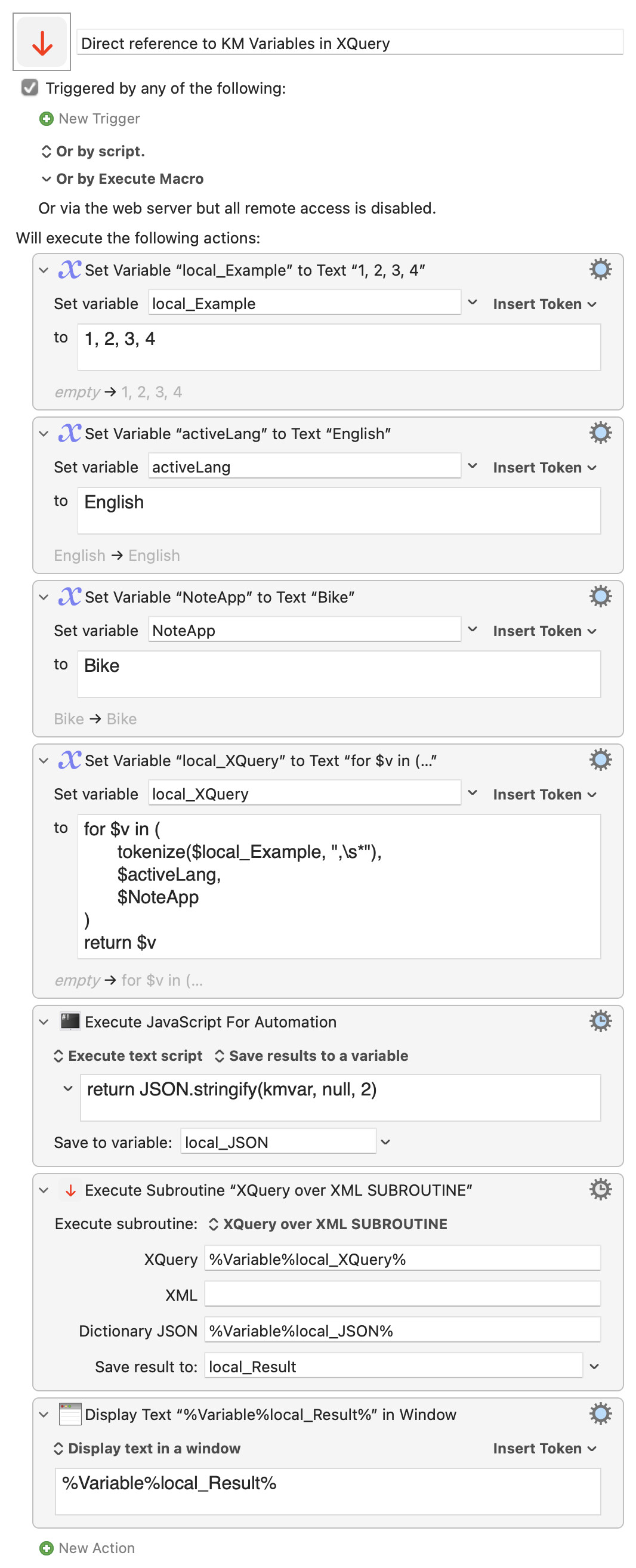
- Adding a field for an optional JSON dictionary, defining names and values of constants (String, Number, Boolean, or – possibly nested – Arrays of these) which can be referenced (prefixing the key name with
$) in the XQuery. - Enabling display of date values,
- allowing for missing xml or xquery,
- allowing processing of
XIncludecomposite XML documents, - and allowing interpretation of non-canonical (e.g. MS Word) HTML as XML
XQuery over XML SUBROUTINE.kmmacros.zip (3,2 Ko)
XQuery subroutine TEST.kmmacros (7.9 KB)
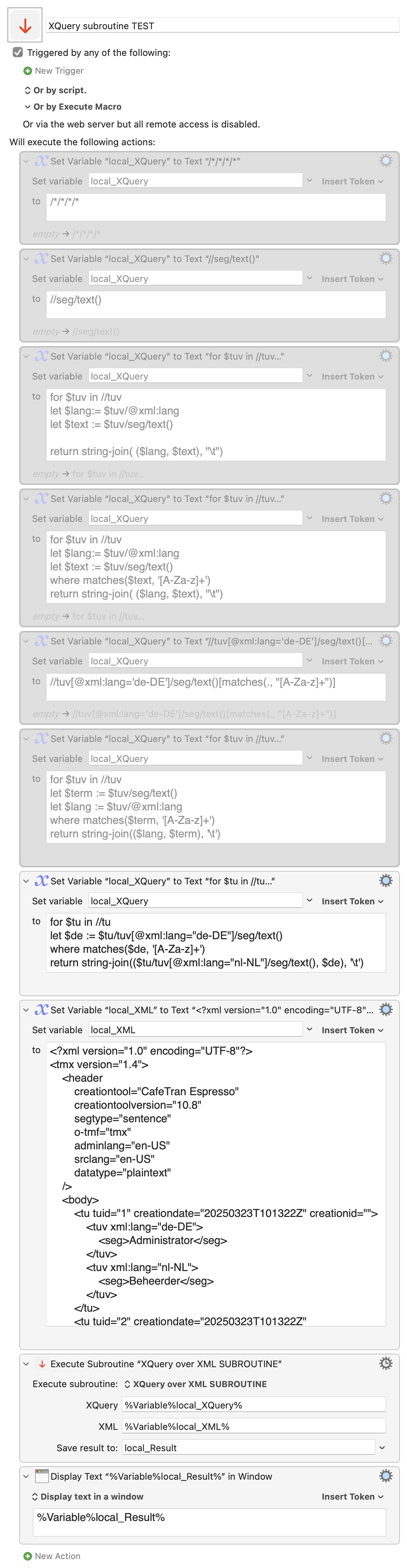
EXAMPLES
Given the CafeTran XML example provided by @ALYB:
Expand disclosure triangle to view XML source
<?xml version="1.0" encoding="UTF-8"?>
<tmx version="1.4">
<header
creationtool="CafeTran Espresso"
creationtoolversion="10.8"
segtype="sentence"
o-tmf="tmx"
adminlang="en-US"
srclang="en-US"
datatype="plaintext"
/>
<body>
<tu tuid="1" creationdate="20250323T101322Z" creationid="">
<tuv xml:lang="de-DE">
<seg>Administrator</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>Beheerder</seg>
</tuv>
</tu>
<tu tuid="2" creationdate="20250323T101322Z" creationid="HL">
<tuv xml:lang="de-DE">
<seg>3</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>3</seg>
</tuv>
</tu>
<tu tuid="3" creationdate="20250323T101322Z" creationid="HL">
<tuv xml:lang="de-DE">
<seg>2</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>2</seg>
</tuv>
</tu>
<tu tuid="4" creationdate="20250323T101322Z" creationid="HL">
<tuv xml:lang="de-DE">
<seg>1</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>1</seg>
</tuv>
</tu>
<tu tuid="5" creationdate="20250323T101322Z" creationid="HL">
<tuv xml:lang="de-DE">
<seg>1</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>1</seg>
</tuv>
</tu>
<tu tuid="6" creationdate="20250323T101322Z" creationid="HL">
<tuv xml:lang="de-DE">
<seg>Typenschild</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>Typeplaatje</seg>
</tuv>
</tu>
</body>
</tmx>
Plain XPaths
the first thing to be aware of is that the simplest XQuery searches are just plain XPath expressions:
- using
/(as in file paths) to separate levels, or //to mean 'at any level'
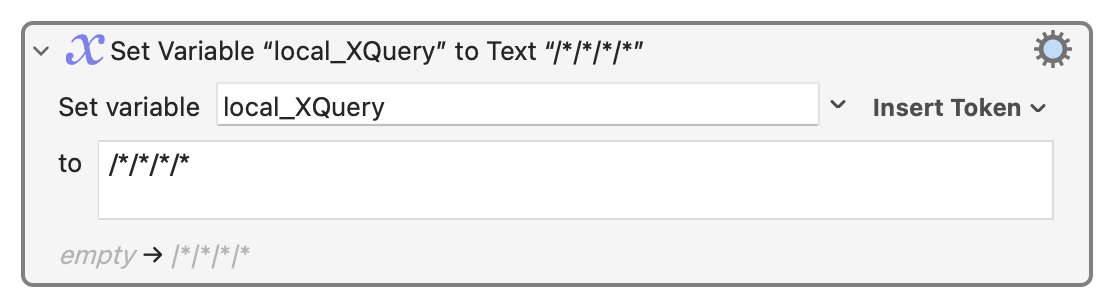
The XQuery:
/*/*/*/*
will find all XML tags, with any name, that are nested 4 levels deep.
From our example, with:
we get all the <tuv> elements in the document:
Expand disclosure triangle to view XQuery result for level 4
<tuv xml:lang="de-DE">
<seg>Administrator</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>Beheerder</seg>
</tuv>
<tuv xml:lang="de-DE">
<seg>3</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>3</seg>
</tuv>
<tuv xml:lang="de-DE">
<seg>2</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>2</seg>
</tuv>
<tuv xml:lang="de-DE">
<seg>1</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>1</seg>
</tuv>
<tuv xml:lang="de-DE">
<seg>1</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>1</seg>
</tuv>
<tuv xml:lang="de-DE">
<seg>Typenschild</seg>
</tuv>
<tuv xml:lang="nl-NL">
<seg>Typeplaatje</seg>
</tuv>
Searching by tag name, rather than level, we can get all the <seg> elements, at any level, with the XQuery:
//seg
obtaining:
<seg>Administrator</seg>
<seg>Beheerder</seg>
<seg>3</seg>
<seg>3</seg>
<seg>2</seg>
<seg>2</seg>
<seg>1</seg>
<seg>1</seg>
<seg>1</seg>
<seg>1</seg>
<seg>Typenschild</seg>
<seg>Typeplaatje</seg>
and if we only want the text they contain (without the tags) we can write:
//seg/text()
getting just:
Administrator
Beheerder
3
3
2
2
1
1
1
1
Typenschild
Typeplaatje
To exclude the lines that start with digits, we can add a regular expression condition between square brackets:
//seg/text()[ not( matches(., '^\d') ) ]
(where dot, as in file paths, refers to the current level)
Now we just get:
Administrator
Beheerder
Typenschild
Typeplaatje
XPaths inside "FLWOR" expressions
XQuery FLWORs are sequences of the pattern
- FOR (XPath)
- LET (optionally attaching a name to one or more values)
- WHERE (optionally filtering down by specifiying a condition)
- ORDER BY (optionally sorting)
- RETURN (some value)
With our sample file, and prefacing any XML attribute names inside tags with @, we can write something like:
for $tuv in //tuv
let $lang:= $tuv/@xml:lang
let $text := $tuv/seg/text()
return string-join( ($lang, $text), "\t")
to get:
de-DE Administrator
nl-NL Beheerder
de-DE 3
nl-NL 3
de-DE 2
nl-NL 2
de-DE 1
nl-NL 1
de-DE 1
nl-NL 1
de-DE Typenschild
nl-NL Typeplaatje
and we can add a WHERE clause to filter it down a bit, excluding the digit lines:
for $tuv in //tuv
let $lang:= $tuv/@xml:lang
let $text := $tuv/seg/text()
where not (matches($text, '^\d'))
return string-join( ($lang, $text), "\t")
getting:
de-DE Administrator
nl-NL Beheerder
de-DE Typenschild
nl-NL Typeplaatje
or perhaps adding an ORDER BY clause to separate out the languages:
for $tuv in //tuv
let $lang:= $tuv/@xml:lang
let $text := $tuv/seg/text()
where not (matches($text, '^\d'))
order by $lang
return string-join( ($lang, $text), "\t")
resulting in:
de-DE Administrator
de-DE Typenschild
nl-NL Beheerder
nl-NL Typeplaatje
Or if we prefer, we can put corresponding NL and DE terms next to each other, line by line:
for $tu in //tu
let $de := $tu/tuv[@xml:lang="de-DE"]/seg/text()
where not (matches($de, '^\d'))
return string-join(($tu/tuv[@xml:lang="nl-NL"]/seg/text(), $de), '\t')
→
| Beheerder | Administrator |
| Typeplaatje | Typenschild |