Yes it is.
Here is the next iteration:
Target terms inherit tags (iteration 3).kmmacros (35.8 KB)
Two things which I'm not sure about, show up where given this pair:
Anfangsbuchstabe<x1/> und ein <x2/>Kleinbuchstabe<x3/> und ein <x4/>Großbuchstabe<x5/> und ein <x6/>EndbuchstabeBeginletter und ein kleine letter und ein hoofdletter und ein eindletter
it produces:
<x1/>beginletter<x1/> und ein <x2/>kleine letter<x3/> und ein <x4/>hoofdletter<x5/> und ein <x6/>eindletter<x6/>
i.e.
- supplying:
- any missing opening tag to a term at the start
- any missing closing tag to a term at the end
- ignoring the upper case starting letter of a term at the beginning of a sentence, and just pulling its match, unchanged, straight out of the glossary.
Should those both be fixed ?
Anything else ?
JS Source
(() => {
"use strict";
// Wrapping translation target terms in
// matching (numbered) tags.
// Rob Trew @2021
// Ver 0.05
// Two replacement passes:
// 1. replacing terms with empty numbered tag pairs
// 2. replacing the empty numbered tag pairs with terms.
// main :: IO ()
const main = () => {
const
kme = Application("Keyboard Maestro Engine"),
kmValue = k => kme.getvariable(k),
fpGlossary = kmValue("glossaryPath");
return either(
msg => alert("Tagging target terms")(msg)
)(
x => x
)(
bindLR(
readFileLR(fpGlossary)
)(fileText => {
const
glossary = glossaryFromTabDelimited(
fileText
),
termList = Object.keys(glossary),
[sourceText, targetText] = [
"SourceSegment",
"TargetSegment"
].map(kmValue);
return 0 < termList.length ? (() => {
const
parseList = parse(
listOfTagsAndTexts()
)(sourceText);
return 0 < parseList.length ? (
Right(
targetTaggedFromGlossary(
glossary
)(
parseList
)(
targetText
)
)
) : Left(
"No tagged terms seen in source text."
);
})() : Left(
`No terms found in ${fpGlossary}`
);
})
);
};
// targetTaggedFromGlossary :: Dict ->
// [((String, Int, Int), String)] ->
// String -> String
const targetTaggedFromGlossary = glossary =>
parseList => targetText => {
const
termTags = parseList[0][0],
translationPairs = sortBy(
flip(comparing(
tpl => tpl[1].length
))
)(
termTags.map(
tagContent => [
tagContent,
glossary[
fst(tagContent)
]
]
)
);
return taggedTarget(translationPairs)(
targetText
);
};
// taggedTarget :: () ->
// ((String, Int, Int), String) ->
// String -> String
const taggedTarget = translationPairs =>
targetText => {
const
withEmptyTags = translationPairs.reduce(
(a, tpl) => {
const
gloss = snd(tpl),
tags = fst(tpl),
n1 = tags[1],
n2 = tags[2];
return a.replace(
new RegExp(gloss, "iu"),
`<x${n1}/><x${n2}/>`
);
},
targetText
);
return translationPairs.reduce(
(a, tpl) => {
const
gloss = snd(tpl),
tags = fst(tpl),
n1 = tags[1],
n2 = tags[2];
return a.replace(
new RegExp(
`<x${n1}/><x${n2}/>`,
"iu"
),
`<x${n1}/>${gloss}<x${n2}/>`
);
},
withEmptyTags
);
};
// glossaryFromTabDelimited :: String ->
// { Source::String, Target::String }
const glossaryFromTabDelimited = text =>
lines(text).reduce((a, s) => {
const parts = s.split("\t");
return 1 < parts.length ? (
Object.assign(a, {
[parts[0]]: parts[1]
})
) : a;
}, {});
// --------------- TAGGED LINE PARSER ----------------
// listOfTagsAndTexts :: Parser [(String, Int, Int)]
const listOfTagsAndTexts = () =>
// A list of tag-wrapped terms,
// each with the number of that start tag,
// and the number of the end tag.
fmapP(
dicts => {
const iLast = dicts.length - 1;
return dicts.flatMap(
(x, i, rest) => x.isTerm ? [
[
x.text,
rest[
0 < i ? i - 1 : i + 1
].number,
rest[
iLast > i ? i + 1 : i - 1
].number
]
] : []
);
}
)(
many(
altP(numberedTag())(tagLess())
)
);
// numberedTag :: Parser
// {type::String, name::String, number::String}
const numberedTag = () =>
bindP(
char("<")
)(() => bindP(
fmapP(concat)(
some(
satisfy(c => !isDigit(c))
)
)
)(k => bindP(
fmapP(
ds => parseInt(
ds.join(""), 10
)
)(
some(satisfy(isDigit))
)
)(n => bindP(
string("/>")
)(
() => pureP({
type: "Tag",
name: k,
number: n
})
))));
// tagLess :: () -> Parser String
const tagLess = () =>
fmapP(cs => ({
type: "Text",
text: cs.join(""),
isTerm: 0 < cs.length && !" \t".includes(cs[0])
}))(
some(satisfy(c => "<" !== c))
);
// --------- GENERIC PARSERS AND COMBINATORS ---------
// Parser :: String -> [(a, String)] -> Parser a
const Parser = f =>
// A function lifted into a Parser object.
({
type: "Parser",
parser: f
});
// altP (<|>) :: Parser a -> Parser a -> Parser a
const altP = p =>
// p, or q if p doesn't match.
q => Parser(s => {
const xs = parse(p)(s);
return 0 < xs.length ? (
xs
) : parse(q)(s);
});
// apP <*> :: Parser (a -> b) -> Parser a -> Parser b
const apP = pf =>
// A new parser obtained by the application
// of a Parser-wrapped function,
// to a Parser-wrapped value.
p => Parser(
s => parse(pf)(s).flatMap(
vr => parse(
fmapP(vr[0])(p)
)(vr[1])
)
);
// bindP (>>=) :: Parser a ->
// (a -> Parser b) -> Parser b
const bindP = p =>
// A new parser obtained by the application
// of a function to a Parser-wrapped value.
// The function must enrich its output,
// lifting it into a new Parser.
// Allows for the nesting of parsers.
f => Parser(
s => parse(p)(s).flatMap(
tpl => parse(f(tpl[0]))(tpl[1])
)
);
// char :: Char -> Parser Char
const char = x =>
// A particular single character.
satisfy(c => x === c);
// fmapP :: (a -> b) -> Parser a -> Parser b
const fmapP = f =>
// A new parser derived by the structure-preserving
// application of f to the value in p.
p => Parser(
s => parse(p)(s).flatMap(
first(f)
)
);
// isDigit :: Char -> Bool
const isDigit = c => {
const n = c.codePointAt(0);
return 48 <= n && 57 >= n;
};
// liftA2P :: (a -> b -> c) ->
// Parser a -> Parser b -> Parser c
const liftA2P = op =>
// The binary function op, lifted
// to a function over two parsers.
p => apP(fmapP(op)(p));
// many :: Parser a -> Parser [a]
const many = p => {
// Zero or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const someP = q =>
liftA2P(
x => xs => [x].concat(xs)
)(q)(many(q));
return Parser(
s => parse(
0 < s.length ? (
altP(someP(p))(pureP([]))
) : pureP([])
)(s)
);
};
// parse :: Parser a -> String -> [(a, String)]
const parse = p =>
// The result of parsing a string with p.
p.parser;
// pureP :: a -> Parser a
const pureP = x =>
// The value x lifted, unchanged,
// into the Parser monad.
Parser(s => [Tuple(x)(s)]);
// satisfy :: (Char -> Bool) -> Parser Char
const satisfy = test =>
// Any character for which the
// given predicate returns true.
Parser(
s => 0 < s.length ? (
test(s[0]) ? [
Tuple(s[0])(s.slice(1))
] : []
) : []
);
// sequenceP :: [Parser a] -> Parser [a]
const sequenceP = ps =>
// A single parser for a list of values, derived
// from a list of parsers for single values.
Parser(
s => ps.reduce(
(a, q) => a.flatMap(
vr => parse(q)(vr[1]).flatMap(
first(xs => vr[0].concat(xs))
)
),
[Tuple([])(s)]
)
);
// some :: Parser a -> Parser [a]
const some = p => {
// One or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const manyP = q =>
altP(some(q))(pureP([]));
return Parser(
s => parse(
liftA2P(
x => xs => [x].concat(xs)
)(p)(manyP(p))
)(s)
);
};
// string :: String -> Parser String
const string = s =>
// A particular string.
fmapP(cs => cs.join(""))(
sequenceP([...s].map(char))
);
// ----------------------- JXA -----------------------
// alert :: String => String -> IO String
const alert = title =>
s => {
const sa = Object.assign(
Application("System Events"), {
includeStandardAdditions: true
});
return (
sa.activate(),
sa.displayDialog(s, {
withTitle: title,
buttons: ["OK"],
defaultButton: "OK"
}),
s
);
};
// readFileLR :: FilePath -> Either String IO String
const readFileLR = fp => {
// Either a message or the contents of any
// text file at the given filepath.
const
e = $(),
ns = $.NSString
.stringWithContentsOfFileEncodingError(
$(fp).stringByStandardizingPath,
$.NSUTF8StringEncoding,
e
);
return ns.isNil() ? (
Left(ObjC.unwrap(e.localizedDescription))
) : Right(ObjC.unwrap(ns));
};
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: "Either",
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: "Either",
Right: x
});
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
b => ({
type: "Tuple",
"0": a,
"1": b,
length: 2
});
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = m =>
mf => m.Left ? (
m
) : mf(m.Right);
// comparing :: (a -> b) -> (a -> a -> Ordering)
const comparing = f =>
x => y => {
const
a = f(x),
b = f(y);
return a < b ? -1 : (a > b ? 1 : 0);
};
// concat :: [[a]] -> [a]
// concat :: [String] -> String
const concat = xs =>
0 < xs.length ? (
(
xs.every(x => "string" === typeof x) ? (
""
) : []
).concat(...xs)
) : xs;
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => e.Left ? (
fl(e.Left)
) : fr(e.Right);
// flip :: (a -> b -> c) -> b -> a -> c
const flip = op =>
// The binary function op with
// its arguments reversed.
1 < op.length ? (
(a, b) => op(b, a)
) : (x => y => op(y)(x));
// fst :: (a, b) -> a
const fst = tpl =>
// First member of a pair.
tpl[0];
// first :: (a -> b) -> ((a, c) -> (b, c))
const first = f =>
// A simple function lifted to one which applies
// to a tuple, transforming only its first item.
xy => {
const tpl = Tuple(f(xy[0]))(xy[1]);
return Array.isArray(xy) ? (
Array.from(tpl)
) : tpl;
};
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single
// string delimited by newline and or CR.
0 < s.length ? (
s.split(/[\r\n]+/u)
) : [];
// list :: StringOrArrayLike b => b -> [a]
const list = xs =>
// xs itself, if it is an Array,
// or an Array derived from xs.
Array.isArray(xs) ? (
xs
) : Array.from(xs || []);
// snd :: (a, b) -> b
const snd = tpl =>
// Second member of a pair.
tpl[1];
// sortBy :: (a -> a -> Ordering) -> [a] -> [a]
const sortBy = f =>
xs => list(xs).slice()
.sort((a, b) => f(a)(b));
// MAIN --
return main();
})();
- should be fixed
- is handled by my editor
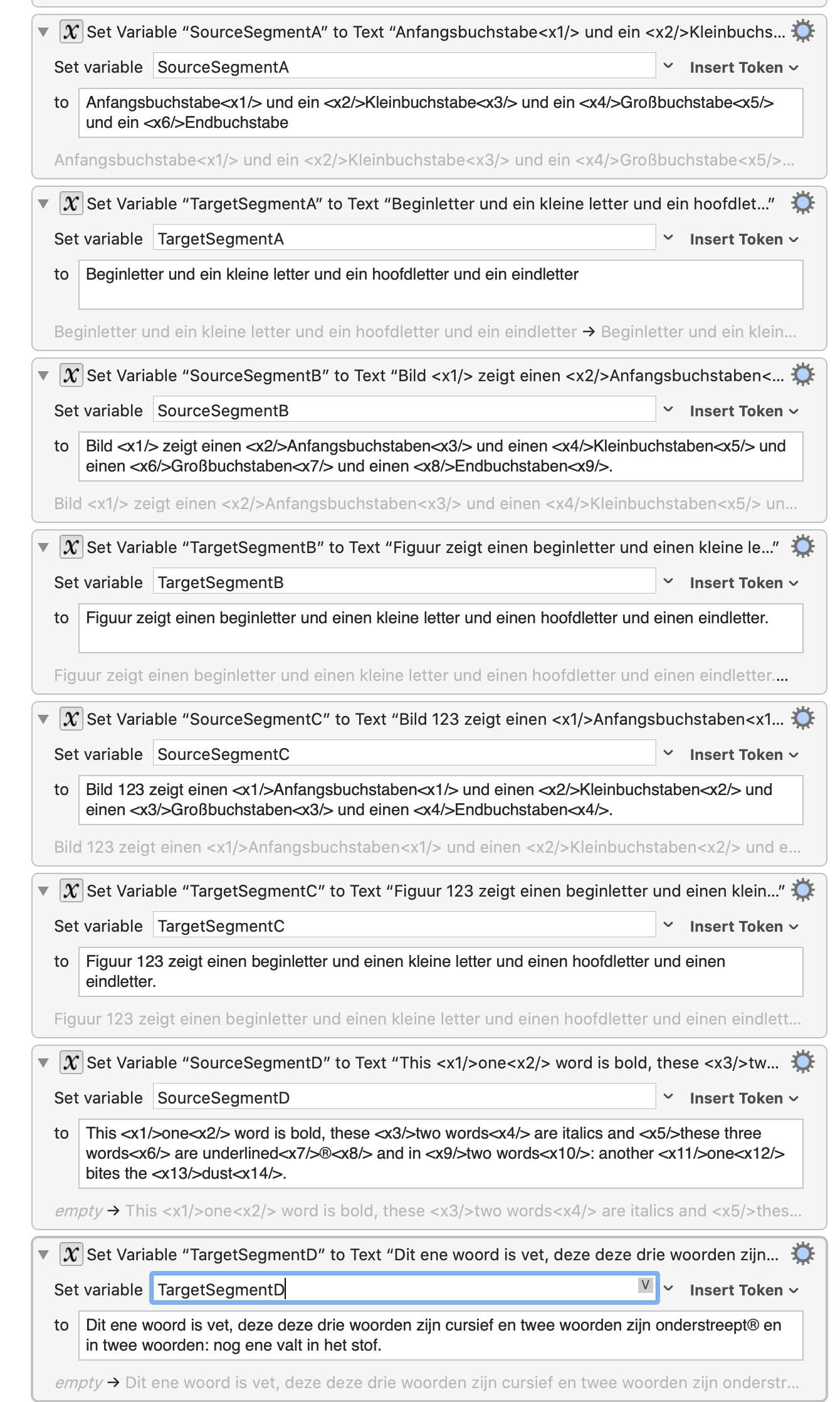
BTW: I had to revert to Ver 0.02 of your JS in order to have terms tagged left and right.
Ver 005 only tags variant A of the the source and target segment combination correctly. Variant B should be tagged correctly, except from the insertion of the first, isolated tag.
1 Like
Thanks for the examples !
I think we're probably getting close now, and I'll try to sort it out over the weekend.
Great!
Just tidying up here, and puzzled by behaviour with sampleD, but then I noticed that the NL doesn't quite match the EN (perhaps a few typos ?)
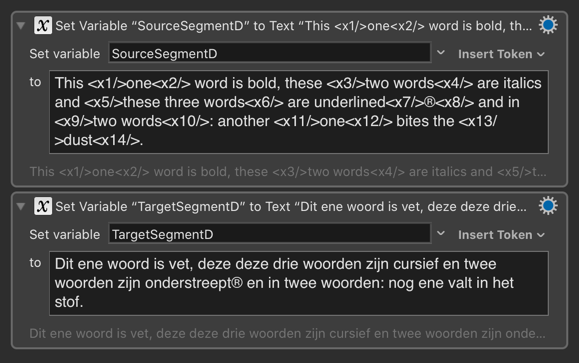
(I'll post another iteration later this evening.)
Hahaha, no this was my sneaky way to make sure that non-linear translations were covered too.
I did wonder if it was a trick question : -)
I think we may be pushing at the limits of the formally indeterminate here, but let's see what's possible.
In the meanwhile if you have those eight variables defined in KM:
SourceSegment[A-C]
TargetSegment[A-C]
and you have a tab delimited ~/Desktop/glossary.txt including some variants of these tab-delimited lines:
® ®
© ©
™ ™
Anfangsbuchstabe beginletter
Anfangsbuchstaben beginletter
Kleinbuchstabe kleine letter
Kleinbuchstaben kleine letter
Großbuchstabe hoofdletter
Großbuchstaben hoofdletter
Endbuchstabe eindletter
Endbuchstaben eindletter
one ene
two words twee woorden
these three words deze drie woorden
dust stof
then you should be able to paste the following test code into Script Editor, with the language selector at top left set to JavaScript
and hit Run to see the current outcomes with each of the four variable pairs:
Expand triangle for JS Source
(() => {
"use strict";
// TEST FRAME FOR for pairs of KM variables
// SourceSegment[A-C]
// TargetSegment[A-C]
// Wrapping translation target terms in
// matching (numbered) tags.
// Rob Trew @2021
// Ver 0.06
// Two replacement passes:
// 1. replacing terms with empty numbered tag pairs
// 2. replacing the empty numbered tag pairs with terms.
// main :: IO ()
const main = () => {
const
kme = Application("Keyboard Maestro Engine"),
kmValue = k => kme.getvariable(k),
fpGlossary = kmValue("glossaryPath");
return either(
msg => alert("Tagging target terms")(msg)
)(
x => x
)(
bindLR(
readFileLR(fpGlossary)
)(fileText => {
const
glossary = glossaryFromTabDelimited(
// Make two-way entries ?
true
)(
fileText
),
termList = Object.keys(glossary);
return 0 < termList.length ? (
// We have a glossary,
// Inner process here.
Right(
rights(
"ABCD".split("")
.map(c => {
const [source, target] = [
"SourceSegment",
"TargetSegment"
].map(k => kmValue(`${k}${c}`));
return parsedAndTaggedLR(
glossary
)(source)(target);
})
).join("\n\n")
)
) : Left(
`No terms found in ${fpGlossary}`
);
})
);
};
// parsedAndTaggedLR :: Dict -> String ->
// String -> String
const parsedAndTaggedLR = glossary =>
source => target => {
const
parseList = parse(
listOfTagsAndTexts()
)(source);
return 0 < parseList.length ? (
Right(
targetTaggedFromGlossary(
glossary
)(
parseList
)(
target
)
)
) : Left(
"No tagged terms seen in source text."
);
};
// targetTaggedFromGlossary :: Dict ->
// [((String, Int, Int), String)] ->
// String -> String
const targetTaggedFromGlossary = glossary =>
parseList => targetText => {
const
termTags = parseList[0][0].filter(
tripleIsTerm
),
translationPairs = sortBy(
flip(comparing(
tpl => tpl[1].length
))
)(
termTags.map(tagContent => {
const term = fst(tagContent);
return [
tagContent,
glossary[term] || (
`No gloss for: '${term}'`
)
];
})
);
return taggedTarget(translationPairs)(
targetText
);
};
// tripleIsTerm :: (String, Int, Int) -> Bool
const tripleIsTerm = tpl => {
const
noise = " \t.,:;()[]{}",
s = tpl[0],
lng = s.length;
return 0 < lng && (
!noise.includes(s[0])
) && !noise.includes(s[lng - 1]);
};
// taggedTarget :: () ->
// ((String, Int, Int), String) ->
// String -> String
const taggedTarget = translationPairs =>
targetText => {
const
withEmptyTags = translationPairs.reduce(
(a, tpl) => {
const
gloss = snd(tpl),
tags = fst(tpl),
n1 = tags[1],
n2 = tags[2];
return a.replace(
new RegExp(gloss, "iu"),
`<x${n1}/><x${n2}/>`
);
},
targetText
);
return translationPairs.reduce(
(a, tpl) => {
const
gloss = snd(tpl),
tags = fst(tpl),
n1 = tags[1],
n2 = tags[2];
return a.replace(
new RegExp(
`<x${n1}/><x${n2}/>`,
"iu"
),
`<x${n1}/>${gloss}<x${n2}/>`
);
},
withEmptyTags
);
};
// glossaryFromTabDelimited :: String ->
// { Source::String, Target::String }
const glossaryFromTabDelimited = isTwoWay =>
text => lines(text).reduce((a, s) => {
const parts = s.split("\t");
return 1 < parts.length ? (
Object.assign(a, isTwoWay ? {
[parts[0]]: parts[1],
[parts[1]]: parts[0]
} : {
[parts[0]]: parts[1]
})
) : a;
}, {});
// --------------- TAGGED LINE PARSER ----------------
// listOfTagsAndTexts :: Parser [(String, Int, Int)]
const listOfTagsAndTexts = () =>
// A list of tag-wrapped terms,
// each with the number of that start tag,
// and the number of the end tag.
fmapP(
dicts => {
const iLast = dicts.length - 1;
return dicts.flatMap(
(x, i, rest) => x.isTerm ? [
[
x.text,
rest[
0 < i ? i - 1 : i + 1
].number,
rest[
iLast > i ? i + 1 : i - 1
].number
]
] : []
);
}
)(
many(
altP(numberedTag())(tagLess())
)
);
// numberedTag :: Parser
// {type::String, name::String, number::String}
const numberedTag = () =>
bindP(
char("<")
)(() => bindP(
fmapP(concat)(
some(
satisfy(c => !isDigit(c))
)
)
)(k => bindP(
fmapP(
ds => parseInt(
ds.join(""), 10
)
)(
some(satisfy(isDigit))
)
)(n => bindP(
string("/>")
)(
() => pureP({
type: "Tag",
name: k,
number: n
})
))));
// tagLess :: () -> Parser String
const tagLess = () =>
fmapP(cs => ({
type: "Text",
text: cs.join(""),
isTerm: 0 < cs.length && !cs[0].includes(
" \t\n\r.,:;'\""
)
}))(
some(satisfy(c => "<" !== c))
);
// --------- GENERIC PARSERS AND COMBINATORS ---------
// Parser :: String -> [(a, String)] -> Parser a
const Parser = f =>
// A function lifted into a Parser object.
({
type: "Parser",
parser: f
});
// altP (<|>) :: Parser a -> Parser a -> Parser a
const altP = p =>
// p, or q if p doesn't match.
q => Parser(s => {
const xs = parse(p)(s);
return 0 < xs.length ? (
xs
) : parse(q)(s);
});
// apP <*> :: Parser (a -> b) -> Parser a -> Parser b
const apP = pf =>
// A new parser obtained by the application
// of a Parser-wrapped function,
// to a Parser-wrapped value.
p => Parser(
s => parse(pf)(s).flatMap(
vr => parse(
fmapP(vr[0])(p)
)(vr[1])
)
);
// bindP (>>=) :: Parser a ->
// (a -> Parser b) -> Parser b
const bindP = p =>
// A new parser obtained by the application
// of a function to a Parser-wrapped value.
// The function must enrich its output,
// lifting it into a new Parser.
// Allows for the nesting of parsers.
f => Parser(
s => parse(p)(s).flatMap(
tpl => parse(f(tpl[0]))(tpl[1])
)
);
// char :: Char -> Parser Char
const char = x =>
// A particular single character.
satisfy(c => x === c);
// fmapP :: (a -> b) -> Parser a -> Parser b
const fmapP = f =>
// A new parser derived by the structure-preserving
// application of f to the value in p.
p => Parser(
s => parse(p)(s).flatMap(
first(f)
)
);
// isDigit :: Char -> Bool
const isDigit = c => {
const n = c.codePointAt(0);
return 48 <= n && 57 >= n;
};
// liftA2P :: (a -> b -> c) ->
// Parser a -> Parser b -> Parser c
const liftA2P = op =>
// The binary function op, lifted
// to a function over two parsers.
p => apP(fmapP(op)(p));
// many :: Parser a -> Parser [a]
const many = p => {
// Zero or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const someP = q =>
liftA2P(
x => xs => [x].concat(xs)
)(q)(many(q));
return Parser(
s => parse(
0 < s.length ? (
altP(someP(p))(pureP([]))
) : pureP([])
)(s)
);
};
// parse :: Parser a -> String -> [(a, String)]
const parse = p =>
// The result of parsing a string with p.
p.parser;
// pureP :: a -> Parser a
const pureP = x =>
// The value x lifted, unchanged,
// into the Parser monad.
Parser(s => [Tuple(x)(s)]);
// satisfy :: (Char -> Bool) -> Parser Char
const satisfy = test =>
// Any character for which the
// given predicate returns true.
Parser(
s => 0 < s.length ? (
test(s[0]) ? [
Tuple(s[0])(s.slice(1))
] : []
) : []
);
// sequenceP :: [Parser a] -> Parser [a]
const sequenceP = ps =>
// A single parser for a list of values, derived
// from a list of parsers for single values.
Parser(
s => ps.reduce(
(a, q) => a.flatMap(
vr => parse(q)(vr[1]).flatMap(
first(xs => vr[0].concat(xs))
)
),
[Tuple([])(s)]
)
);
// some :: Parser a -> Parser [a]
const some = p => {
// One or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const manyP = q =>
altP(some(q))(pureP([]));
return Parser(
s => parse(
liftA2P(
x => xs => [x].concat(xs)
)(p)(manyP(p))
)(s)
);
};
// string :: String -> Parser String
const string = s =>
// A particular string.
fmapP(cs => cs.join(""))(
sequenceP([...s].map(char))
);
// ----------------------- JXA -----------------------
// alert :: String => String -> IO String
const alert = title =>
s => {
const sa = Object.assign(
Application("System Events"), {
includeStandardAdditions: true
});
return (
sa.activate(),
sa.displayDialog(s, {
withTitle: title,
buttons: ["OK"],
defaultButton: "OK"
}),
s
);
};
// readFileLR :: FilePath -> Either String IO String
const readFileLR = fp => {
// Either a message or the contents of any
// text file at the given filepath.
const
e = $(),
ns = $.NSString
.stringWithContentsOfFileEncodingError(
$(fp).stringByStandardizingPath,
$.NSUTF8StringEncoding,
e
);
return ns.isNil() ? (
Left(ObjC.unwrap(e.localizedDescription))
) : Right(ObjC.unwrap(ns));
};
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: "Either",
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: "Either",
Right: x
});
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
b => ({
type: "Tuple",
"0": a,
"1": b,
length: 2
});
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = m =>
mf => m.Left ? (
m
) : mf(m.Right);
// comparing :: (a -> b) -> (a -> a -> Ordering)
const comparing = f =>
x => y => {
const
a = f(x),
b = f(y);
return a < b ? -1 : (a > b ? 1 : 0);
};
// concat :: [[a]] -> [a]
// concat :: [String] -> String
const concat = xs =>
0 < xs.length ? (
(
xs.every(x => "string" === typeof x) ? (
""
) : []
).concat(...xs)
) : xs;
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => e.Left ? (
fl(e.Left)
) : fr(e.Right);
// flip :: (a -> b -> c) -> b -> a -> c
const flip = op =>
// The binary function op with
// its arguments reversed.
1 < op.length ? (
(a, b) => op(b, a)
) : (x => y => op(y)(x));
// fst :: (a, b) -> a
const fst = tpl =>
// First member of a pair.
tpl[0];
// first :: (a -> b) -> ((a, c) -> (b, c))
const first = f =>
// A simple function lifted to one which applies
// to a tuple, transforming only its first item.
xy => {
const tpl = Tuple(f(xy[0]))(xy[1]);
return Array.isArray(xy) ? (
Array.from(tpl)
) : tpl;
};
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single
// string delimited by newline and or CR.
0 < s.length ? (
s.split(/[\r\n]+/u)
) : [];
// list :: StringOrArrayLike b => b -> [a]
const list = xs =>
// xs itself, if it is an Array,
// or an Array derived from xs.
Array.isArray(xs) ? (
xs
) : Array.from(xs || []);
// rights :: [Either a b] -> [b]
const rights = xs =>
xs.flatMap(
x => ("Either" === x.type) && (
undefined !== x.Right
) ? [x.Right] : []
);
// snd :: (a, b) -> b
const snd = tpl =>
// Second member of a pair.
tpl[1];
// sortBy :: (a -> a -> Ordering) -> [a] -> [a]
const sortBy = f =>
xs => list(xs).slice()
.sort((a, b) => f(a)(b));
// // showLog :: a -> IO ()
// const showLog = (...args) =>
// // eslint-disable-next-line no-console
// console.log(
// args
// .map(JSON.stringify)
// .join(" -> ")
// );
// sj :: a -> String
const sj = (...args) =>
// Abbreviation of showJSON for quick testing.
// Default indent size is two, which can be
// overriden by any integer supplied as the
// first argument of more than one.
JSON.stringify.apply(
null,
1 < args.length && !isNaN(args[0]) ? [
args[1], null, args[0]
] : [args[0], null, 2]
);
// MAIN --
return main();
})();
Here, for example, with my local settings of those variables, and the local state of the glossary, I'm seeing:
<x1/>beginletter<x1/> und ein <x2/>kleine letter<x3/> und ein <x4/>hoofdletter<x5/> und ein <x6/>eindletter<x6/>
Figuur zeigt einen <x2/>beginletter<x3/> und einen <x4/>kleine letter<x5/> und einen <x6/>hoofdletter<x7/> und einen <x8/>eindletter<x9/>.
Figuur 123 zeigt einen <x1/>beginletter<x1/> und einen <x2/>kleine letter<x2/> und einen <x3/>hoofdletter<x3/> und einen <x4/>eindletter<x4/>.
Dit <x1/>ene<x2/> woord is vet, deze <x5/>deze drie woorden<x6/> zijn cursief en <x3/>twee woorden<x4/> zijn onderstreept<x7/>®<x8/> en in <x9/>twee woorden<x10/>: nog <x11/>ene<x12/> valt in het <x13/>stof<x14/>.
Very nice!
I get the same results. There's only one thing to fix in this pair:
Anfangsbuchstabe<x1/> und ein <x2/>Kleinbuchstabe<x3/> und ein <x4/>Großbuchstabe<x5/> und ein <x6/>Endbuchstabe
<x1/>beginletter<x1/> und ein <x2/>kleine letter<x3/> und ein <x4/>hoofdletter<x5/> und ein <x6/>eindletter<x6/>
Could you implement a fix so that if the first and last five characters of the source segment don't represent a tag, these tags are omitted (or deleted) from the target segment too?
As a last step I need to know how to use this script for only one SourceSegment and one TargetSegment (like in the first iterations), or is this already possible? I need that for inclusion in my KM macro.
Iteration 5:
- reverts to considering a single pair of variables
(SourceSegment, TargetSegment) - adds a third pass which prunes out any
<xnull/>tags from start and end (where one of the source term tags is clipped off by the segmentation border)
I don't know how to thank you. This is awesome.
1 Like
Let us know if any more subtleties emerge : -)
(Nature is full of surprises)
How foreseeing, @ComplexPoint, I've indeed found situations where paired tags, with the same number, aren't handled at all:
Target terms inherit tags (testing iteration 5).kmmacros (40.7 KB)
Glossary.txt.zip (856 Bytes)
1 Like
Thanks – I'll take a look at the weekend : -)
1 Like
Hello @ComplexPoint Maybe this weekend?
ons sal probeer
After reading a post about capture groups, I've tried to use these to solve my task:
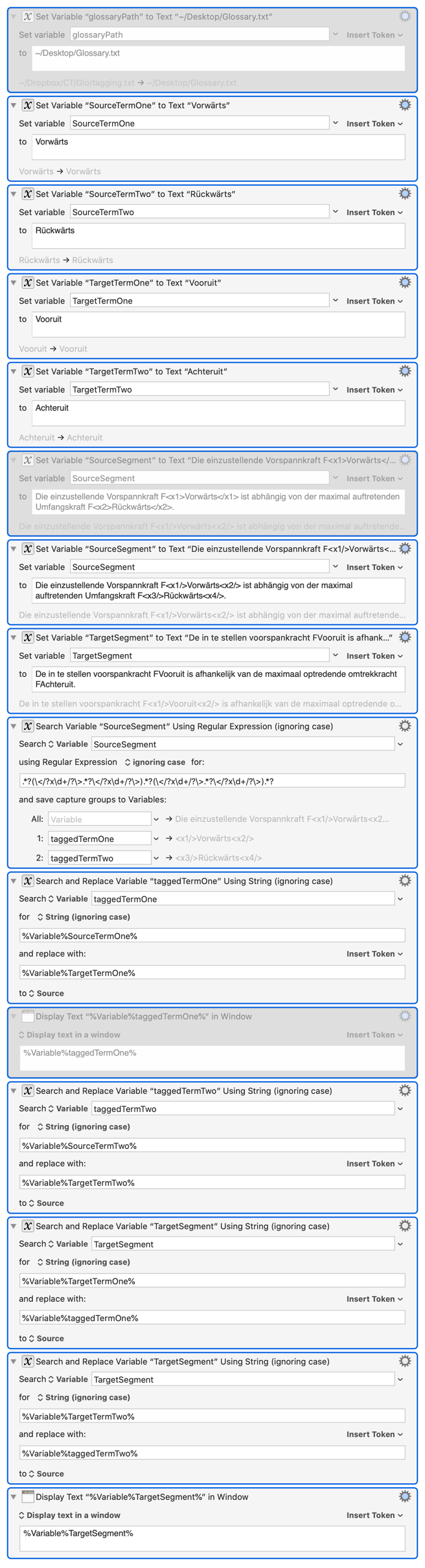
This is astonishing simple, though limited to two term pairs only (at the moment).
The next step will be to get the variables SourceTermOne, TargetTermOne etc. from a tab-delimited text file. For reasons of simplicity, I'll start a new question about that:
https://forum.keyboardmaestro.com/t/how-to-repeat-actions-without-getting-endless-macros/22060
(I've made an attempt to solve the task entirely with KM's actions.)
1 Like