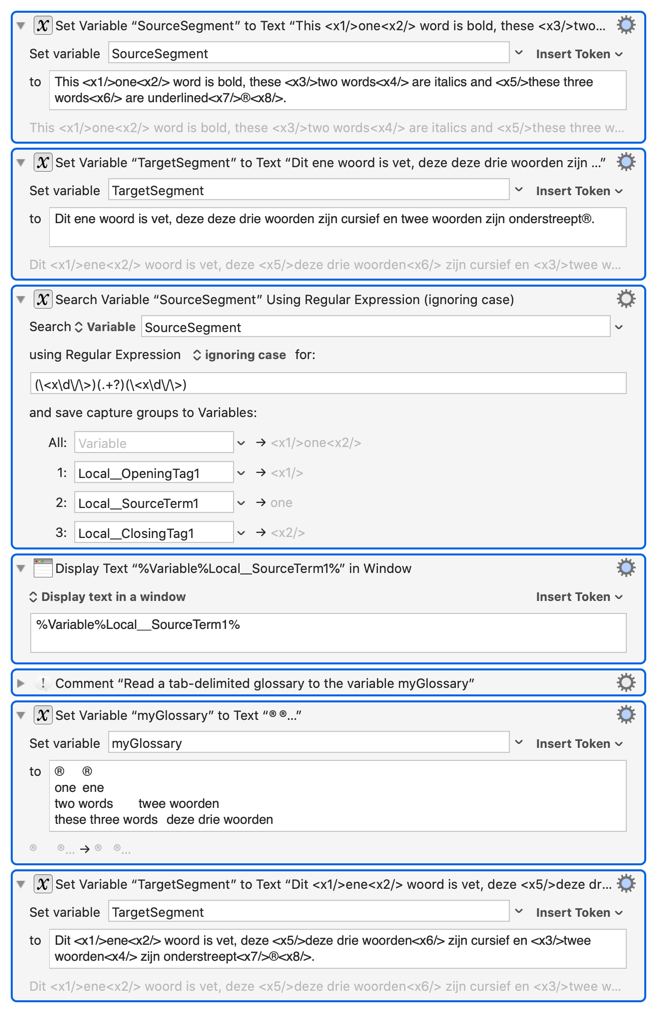
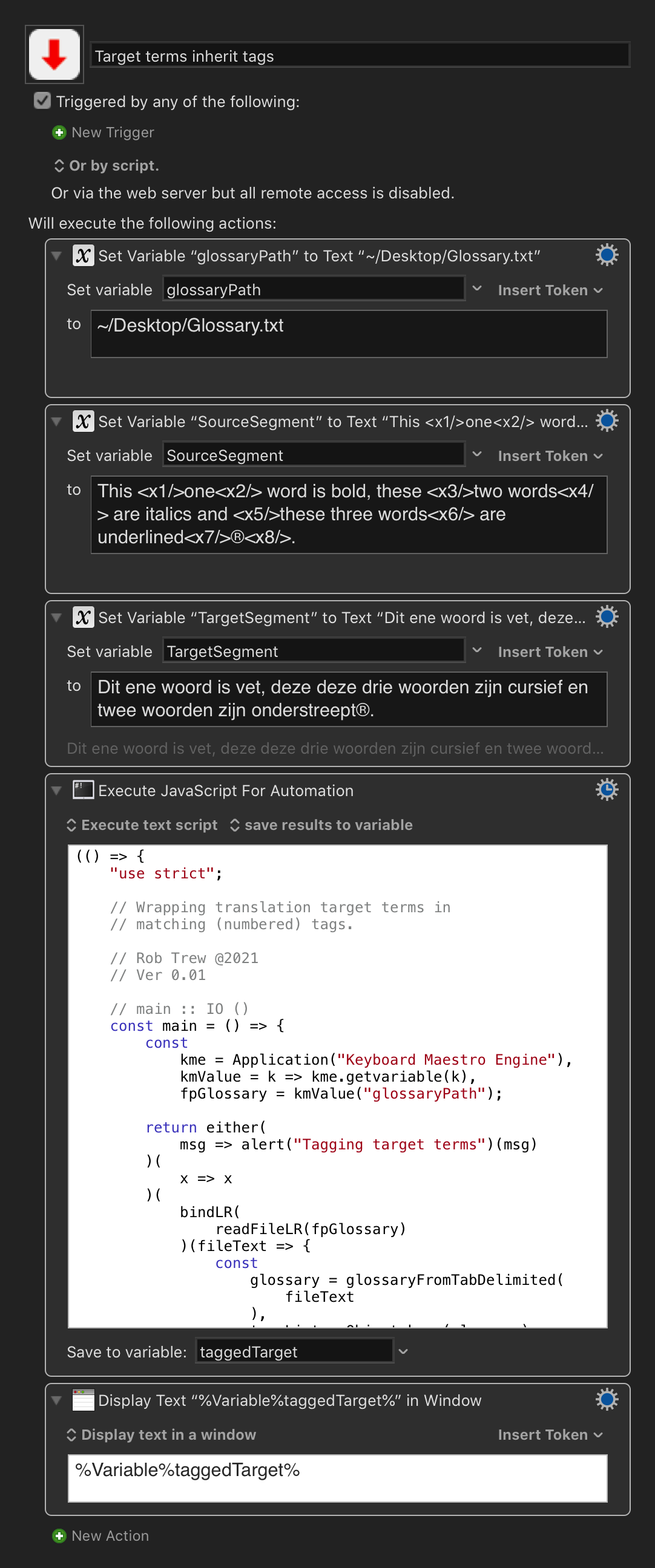
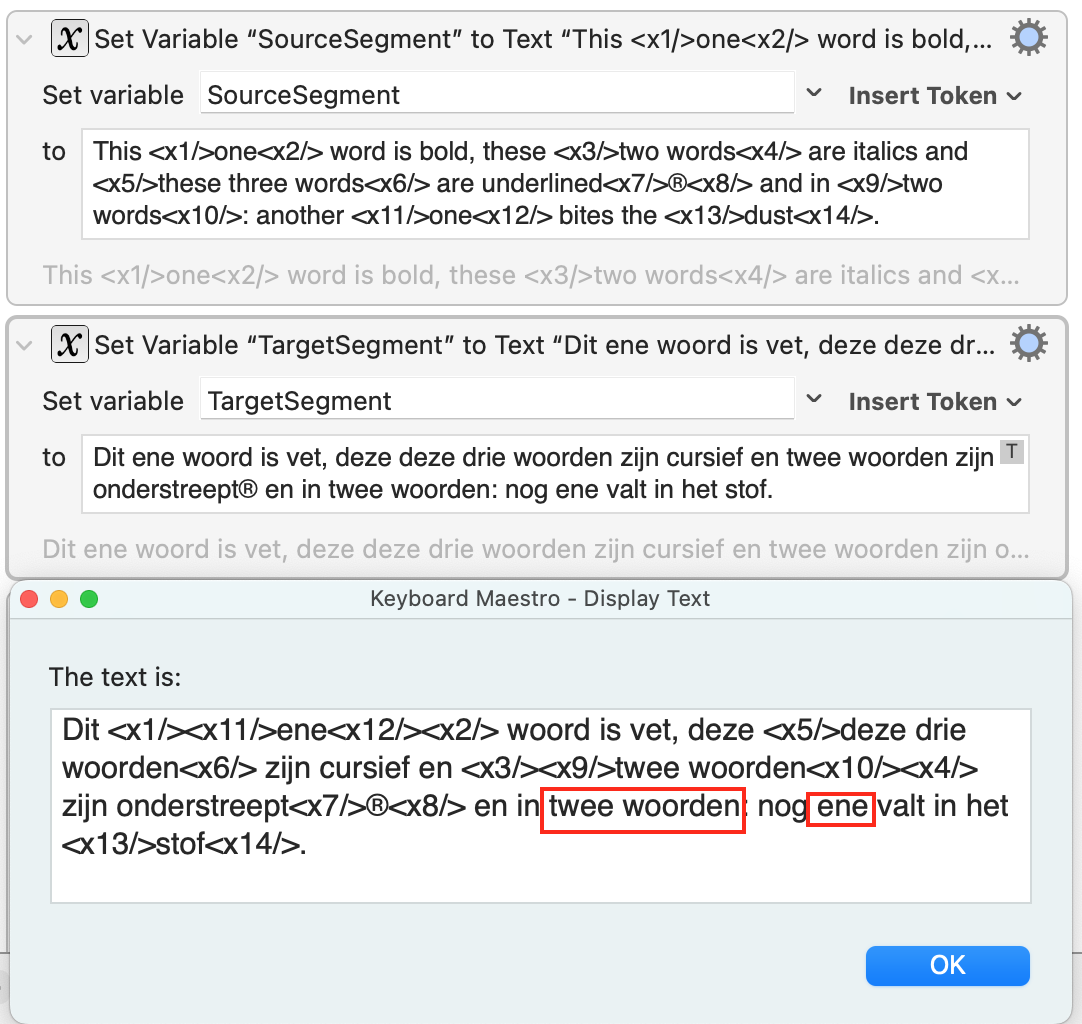
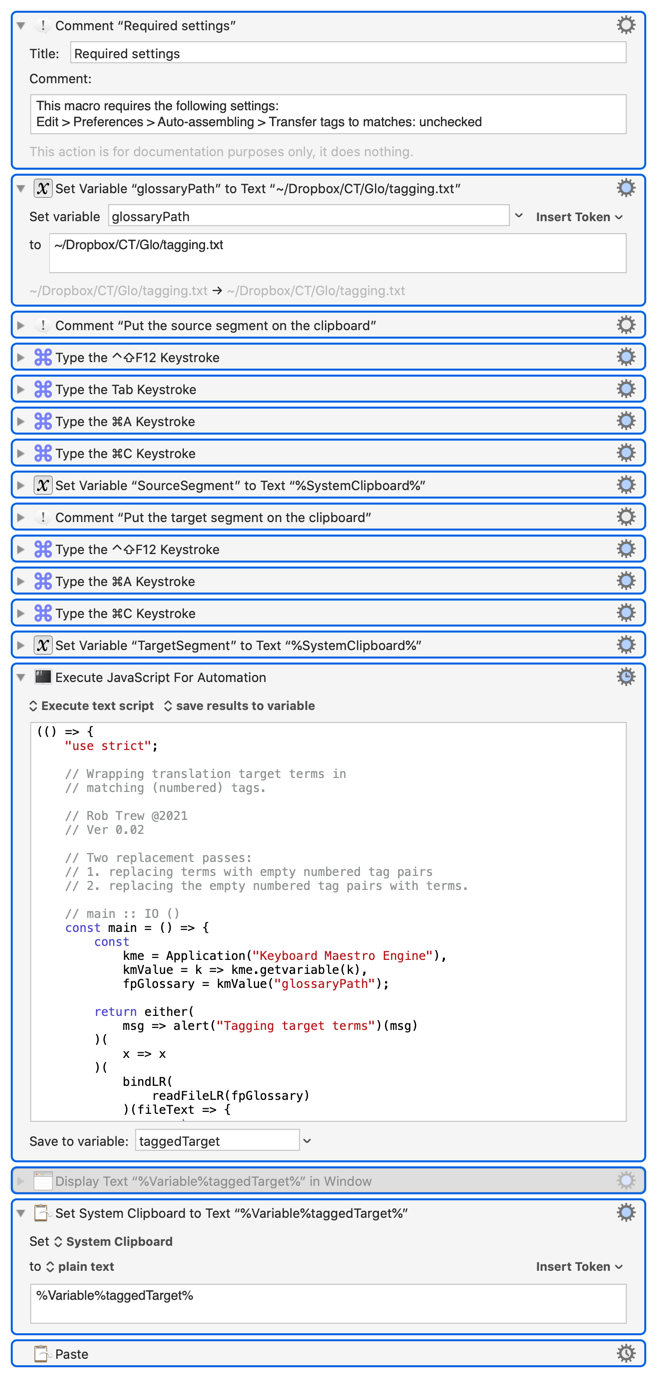
JS Source
(() => {
"use strict";
// Wrapping translation target terms in
// matching (numbered) tags.
// Rob Trew @2021
// Ver 0.01
// main :: IO ()
const main = () => {
const
kme = Application("Keyboard Maestro Engine"),
kmValue = k => kme.getvariable(k),
fpGlossary = kmValue("glossaryPath");
return either(
msg => alert("Tagging target terms")(msg)
)(
x => x
)(
bindLR(
readFileLR(fpGlossary)
)(fileText => {
const
glossary = glossaryFromTabDelimited(
fileText
),
termList = Object.keys(glossary),
[sourceText, targetText] = [
"SourceSegment",
"TargetSegment"
].map(kmValue);
return 0 < termList.length ? (() => {
const
parseList = parse(
glossaryTerms()
)(sourceText);
return 0 < parseList.length ? (
Right(
targetTaggedFromGlossary(
glossary
)(
parseList
)(
targetText
)
)
) : Left(
"No tagged terms seen in source text."
);
})() : Left(
`No terms found in ${fpGlossary}`
);
})
);
};
// targetTaggedFromGlossary :: Dict ->
// [((String, Int, Int), String)] ->
// String -> String
const targetTaggedFromGlossary = glossary =>
parseList => targetText => {
const
termTags = parseList[0][0],
translationPairs = sortBy(
flip(comparing(
tpl => tpl[1].length
))
)(
termTags.map(
tagContent => [
tagContent,
glossary[
fst(tagContent)
]
]
)
);
return taggedTarget(translationPairs)(
targetText
);
};
// taggedTarget :: () ->
// ((String, Int, Int), String) ->
// String -> String
const taggedTarget = translationPairs =>
targetText => translationPairs.reduce(
(a, tpl) => {
const
gloss = snd(tpl),
tags = fst(tpl),
n1 = tags[1],
n2 = tags[2];
return a.replace(
gloss,
`<x${n1}/>${gloss}<x${n2}/>`
);
},
targetText
);
// glossaryFromTabDelimited :: String ->
// { Source::String, Target::String }
const glossaryFromTabDelimited = text =>
lines(text).reduce((a, s) => {
const parts = s.split("\t");
return 1 < parts.length ? (
Object.assign(a, {
[parts[0]]: parts[1]
})
) : a;
}, {});
// --------------- TAGGED LINE PARSER ----------------
// glossaryTerms = () ->
// Parser [(String, String, String, Int, Int)]
const glossaryTerms = () =>
many(
bindP(
tagLess()
)(
taggedTerm
)
);
// taggedTerm = () ->
// Parser (String, String, String, Int, Int)
const taggedTerm = () => {
const tag = numberedEndTag();
return bindP(
tag
)(
([k, n]) => bindP(
tagLess()
)(
term => bindP(
tag
)(
([k2, n2]) => pureP([
term, n, n2, k, k2
])
)
)
);
};
// numberedEndTag :: () -> Parser (String, Int)
const numberedEndTag = () =>
bindP(
char("<")
)(() => bindP(
fmapP(concat)(
some(
satisfy(c => !isDigit(c))
)
)
)(k => bindP(
fmapP(
ds => parseInt(
ds.join(""), 10
)
)(
some(satisfy(isDigit))
)
)(n => bindP(
string("/>")
)(
() => pureP([k, n])
))));
// tagLess :: () -> Parser String
const tagLess = () =>
fmapP(concat)(
some(satisfy(c => "<" !== c))
);
// --------- GENERIC PARSERS AND COMBINATORS ---------
// Parser :: String -> [(a, String)] -> Parser a
const Parser = f =>
// A function lifted into a Parser object.
({
type: "Parser",
parser: f
});
// altP (<|>) :: Parser a -> Parser a -> Parser a
const altP = p =>
// p, or q if p doesn't match.
q => Parser(s => {
const xs = parse(p)(s);
return 0 < xs.length ? (
xs
) : parse(q)(s);
});
// apP <*> :: Parser (a -> b) -> Parser a -> Parser b
const apP = pf =>
// A new parser obtained by the application
// of a Parser-wrapped function,
// to a Parser-wrapped value.
p => Parser(
s => parse(pf)(s).flatMap(
vr => parse(
fmapP(vr[0])(p)
)(vr[1])
)
);
// bindP (>>=) :: Parser a ->
// (a -> Parser b) -> Parser b
const bindP = p =>
// A new parser obtained by the application
// of a function to a Parser-wrapped value.
// The function must enrich its output,
// lifting it into a new Parser.
// Allows for the nesting of parsers.
f => Parser(
s => parse(p)(s).flatMap(
tpl => parse(f(tpl[0]))(tpl[1])
)
);
// char :: Char -> Parser Char
const char = x =>
// A particular single character.
satisfy(c => x === c);
// fmapP :: (a -> b) -> Parser a -> Parser b
const fmapP = f =>
// A new parser derived by the structure-preserving
// application of f to the value in p.
p => Parser(
s => parse(p)(s).flatMap(
first(f)
)
);
// isDigit :: Char -> Bool
const isDigit = c => {
const n = c.codePointAt(0);
return 48 <= n && 57 >= n;
};
// liftA2P :: (a -> b -> c) ->
// Parser a -> Parser b -> Parser c
const liftA2P = op =>
// The binary function op, lifted
// to a function over two parsers.
p => apP(fmapP(op)(p));
// many :: Parser a -> Parser [a]
const many = p => {
// Zero or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const someP = q =>
liftA2P(
x => xs => [x].concat(xs)
)(q)(many(q));
return Parser(
s => parse(
0 < s.length ? (
altP(someP(p))(pureP([]))
) : pureP([])
)(s)
);
};
// parse :: Parser a -> String -> [(a, String)]
const parse = p =>
// The result of parsing a string with p.
p.parser;
// pureP :: a -> Parser a
const pureP = x =>
// The value x lifted, unchanged,
// into the Parser monad.
Parser(s => [Tuple(x)(s)]);
// satisfy :: (Char -> Bool) -> Parser Char
const satisfy = test =>
// Any character for which the
// given predicate returns true.
Parser(
s => 0 < s.length ? (
test(s[0]) ? [
Tuple(s[0])(s.slice(1))
] : []
) : []
);
// sequenceP :: [Parser a] -> Parser [a]
const sequenceP = ps =>
// A single parser for a list of values, derived
// from a list of parsers for single values.
Parser(
s => ps.reduce(
(a, q) => a.flatMap(
vr => parse(q)(vr[1]).flatMap(
first(xs => vr[0].concat(xs))
)
),
[Tuple([])(s)]
)
);
// some :: Parser a -> Parser [a]
const some = p => {
// One or more instances of p.
// Lifts a parser for a simple type of value
// to a parser for a list of such values.
const manyP = q =>
altP(some(q))(pureP([]));
return Parser(
s => parse(
liftA2P(
x => xs => [x].concat(xs)
)(p)(manyP(p))
)(s)
);
};
// string :: String -> Parser String
const string = s =>
// A particular string.
fmapP(cs => cs.join(""))(
sequenceP([...s].map(char))
);
// ----------------------- JXA -----------------------
// alert :: String => String -> IO String
const alert = title =>
s => {
const sa = Object.assign(
Application("System Events"), {
includeStandardAdditions: true
});
return (
sa.activate(),
sa.displayDialog(s, {
withTitle: title,
buttons: ["OK"],
defaultButton: "OK"
}),
s
);
};
// readFileLR :: FilePath -> Either String IO String
const readFileLR = fp => {
// Either a message or the contents of any
// text file at the given filepath.
const
e = $(),
ns = $.NSString
.stringWithContentsOfFileEncodingError(
$(fp).stringByStandardizingPath,
$.NSUTF8StringEncoding,
e
);
return ns.isNil() ? (
Left(ObjC.unwrap(e.localizedDescription))
) : Right(ObjC.unwrap(ns));
};
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: "Either",
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: "Either",
Right: x
});
// Tuple (,) :: a -> b -> (a, b)
const Tuple = a =>
b => ({
type: "Tuple",
"0": a,
"1": b,
length: 2
});
// bindLR (>>=) :: Either a ->
// (a -> Either b) -> Either b
const bindLR = m =>
mf => m.Left ? (
m
) : mf(m.Right);
// comparing :: (a -> b) -> (a -> a -> Ordering)
const comparing = f =>
x => y => {
const
a = f(x),
b = f(y);
return a < b ? -1 : (a > b ? 1 : 0);
};
// concat :: [[a]] -> [a]
// concat :: [String] -> String
const concat = xs =>
0 < xs.length ? (
(
xs.every(x => "string" === typeof x) ? (
""
) : []
).concat(...xs)
) : xs;
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => e.Left ? (
fl(e.Left)
) : fr(e.Right);
// flip :: (a -> b -> c) -> b -> a -> c
const flip = op =>
// The binary function op with
// its arguments reversed.
1 < op.length ? (
(a, b) => op(b, a)
) : (x => y => op(y)(x));
// fst :: (a, b) -> a
const fst = tpl =>
// First member of a pair.
tpl[0];
// first :: (a -> b) -> ((a, c) -> (b, c))
const first = f =>
// A simple function lifted to one which applies
// to a tuple, transforming only its first item.
xy => {
const tpl = Tuple(f(xy[0]))(xy[1]);
return Array.isArray(xy) ? (
Array.from(tpl)
) : tpl;
};
// lines :: String -> [String]
const lines = s =>
// A list of strings derived from a single
// string delimited by newline and or CR.
0 < s.length ? (
s.split(/[\r\n]+/u)
) : [];
// list :: StringOrArrayLike b => b -> [a]
const list = xs =>
// xs itself, if it is an Array,
// or an Array derived from xs.
Array.isArray(xs) ? (
xs
) : Array.from(xs || []);
// snd :: (a, b) -> b
const snd = tpl =>
// Second member of a pair.
tpl[1];
// sortBy :: (a -> a -> Ordering) -> [a] -> [a]
const sortBy = f =>
xs => list(xs).slice()
.sort((a, b) => f(a)(b));
// MAIN --
return main();
})();