Need some suggestions from the group. I ran pdftotext using the -layout option and the resulting file output is text in three columns of:
Last Name, First Name
Address
Notes
Email Address
In some cases there are missing lines. For example some don’t have an address but have childrens names under the notes. Or some have an email address and no phone. Basically the common inconsistency you’d see with a contact info sheet.
I want to get the data into a format that can be imported into a database. What’s my best option to move these around and get them into either csv, tab, or paragraph blocks (1 column only)?
If we can understand the real-world format of the data, then most likely a RegEx will get you what you want.
But you state "three columns", then show 4 lines.
Please post some real-world examples that will cover the range of possible data. If the data is sensitive, you can change parts of the content (name, phone#, etc), but be sure to keep the format/layout EXACTLY the same as the source data you will need to process.
JM I know your a stickler for details. The only thing that I didn't mention and should have is that each person's entry is not consistent at being 4 lines. They range from one line (name), and up to five lines. The usual format, but not always is: three columns wide and for each name up to five lines which is usually in this order:
NameLast, NameFirst
Spouse:
Street
City, ST, ZIP
Email:
I think @JMichaelTX asked for a real-world example of the output of pdftotext. That is, the plain-text data that will go into the KM macro.
Ideally you would also post a valid example PDF. Because pdftotext is not the only way to get text out of a PDF. Maybesome other solution works better here.
I have some dummy data I could mold into a resonable text file example. The problem I see with it is that the spacing is inconsistent where the list is not laid out in a symetrical spacing like say address labels would be.
I have some dummy data I could mold into a resonable text file example. The problem I see with it is that the spacing is inconsistent where the list is not laid out in a symetrical spacing like say address labels would be.
No, please do NOT "mold" or change the text file format/layout in any way.
To craft an effective, flexible RegEx, I need to see the data as you will get it from the pdftotext tool.
It needs to include an example of every possible format that you might encounter in the real data.
I completely understand Chris. I really do. The other work I do has similar parallels and in addtion I am also doing Filemaker Dev. So I know that solutions must be built in place to meet up with existing architectures.
I have a list of 600 high school alumni names and addresses. I am sure none of the people I have spoken to would care if I posted it here but it’s the 500 on the list I have never spoken to to ask if that would be OK. The list is 20 years old and not likely even accurate. Most of the emails would likely bounce but it’s where I have to start from to attempt to track down classmates for an upcoming reunion.
I suppose what I really need to do is stop working on learning JavaScript right now and chew on this thick steak I’ve been given with RegEx. I have been fiddling with it and am starting to understand the short hand so maybe this is the project for me to finally just give in and finally learn it. RegEx is so necessary and useful it would be stupid for me not to.
Actually, the JavaScript RegEx engine is very powerful and easy to use.
So a JXA solution might be the best method.
Regardless, whether it is for a project you want to do yourself, or one that you want help with, having a good set of requirements/specs is essential. Time spent getting a good example of source data will repay you in saved time many times over.
You need this good example of source data to use at RegEx101.com.
A way of anonymizing the data would be to change all the digits to 3 and all the letters to c. If there are fixed strings you want to preserve (eg “Spouse”), change them to something else, then change them back later.
For example, say the data is like this:
Temple, Shirley
Spouse: Bill Mayer
Street: Main Street
City, ST, ZIP: Washington, 947564
Email: bla@bla.com
Stick it in BBEdit, and then do the sequence:
Search and Replace regex [0-9] with 3
Search and Replace Spouse (case sensitive) with 1
Search and Replace Email (case sensitive) with 2
Search and Replace Name (case sensitive) with 4
Search and Replace regex [a-zA-Z] with c
Search and Replace ccc+ with ccc
Search and Replace 1 with Spouse
Search and Replace 2 with Email
Search and Replace 4 with Name
OK, I'm new to BBEdit.
Is this ("do the sequence") a BBEdit feature?
I don't see how to use it.
In particular I don't understand statements like this one: Search and Replace Spouse (case sensitive) with 1
I know how to use the BBEdit Find/Replace with RegEx (grep), but I'm not following this sequence of instructions.
You'd have to do it manually or build it with one of the following methods:
AppleScript
Text Filter
Text Factory
It's easy enough to build a sequence of replace commands with AppleScript:
tell application "BBEdit"
tell front text window's text
replace "\\d" using "9" options {search mode:grep, case sensitive:false, starting at top:true}
end tell
end tell
** JXA would give even more processing options.
Or you can use a simple text filter using sed:
#!/usr/bin/env bash
sed -E 's![[:digit:]]!9!g'
** It's very easy to build up multiple find/replace statements with sed.
Filtering with real intelligence could be done with AppleScript but would be slow.
Real intelligence - meaning to retain the exact number of characters and capitalization in spousal names for instance.
To do this level of processing I'd use Perl, because I know it well enough – and it would be very fast.
If Peter's method (corrected) will work in general, it would be cool if we could build a KM Macro that does this automatically. Then, when any user asks for help with stuff like this, we can give them the Macro they can use before posting the sample data.
I only really intended the sequence to be done manually, one after the other, though BBEdit does have Text Factories that do exactly this (and Keyboard Maestro has an action to run a Text Factory).
You could probably build a macro that asked for a list of keywords, and then applied the transformations. Generalising the preserving of the keywords would not be too hard (assuming the keywords did not have numbers in them, and even then with a bit more thought as to how to represent them).
I was going to do this with Perl, but I had some trouble I couldn't solve with my regex pattern. The pattern works fine in BBEdit and ICU regex but not in Perl, and I don't know why yet.
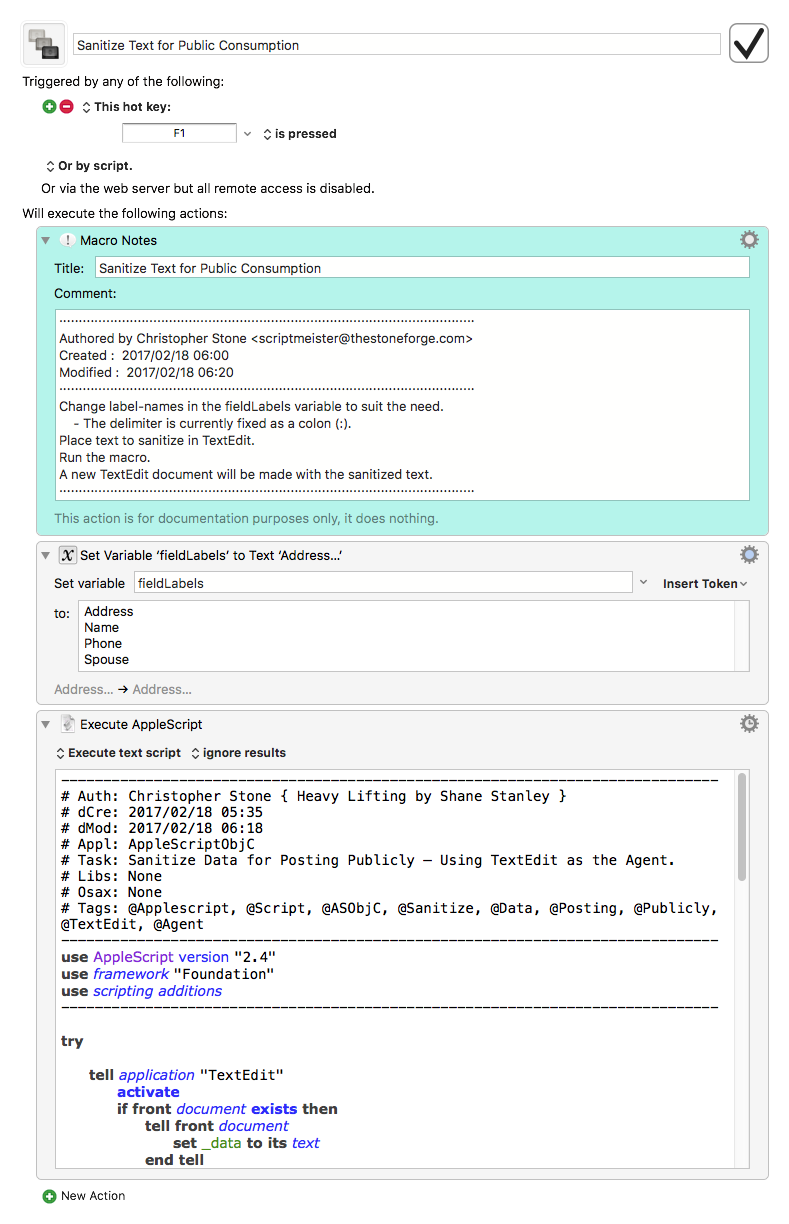
So – with help from Shane Stanley I assembled something in AppleScriptObjC I'm reasonably happy with.
The goal was:
To replace all lowercase letters with an x and uppercase letters with an X
Thus preserving the exact layout.
Replace all digits with a 9.
Leave punctuation intact.
Leave designated label names intact.
TextEdit is currently the input and output agent.
The label delimiter is currently fixed as a colon, although if it gets used any the macro is bound to gain some flexibility.
---
###Instructions
Place the text you want to sanitize in the front TextEdit document.
Run the macro.
A new document with the sanitized text will appear.
---
###Sample Text
Name: Robert A. Heinlein
Phone: (666) 666-6666
Spouse: Virginia Gerstenfeld Heinlein
Address: 2019 E. Tycho Ave.
Name: George Stephanopoulos
Spouse: Alexandra Wentworth
Extra text 01
Extra text 02
Extra text 03
Text factories are relatively slow – even when run directly from BBEdit. Their main advantage is they require little expertise to assemble.
AppleScripting BBEdit directly is much faster.
Parsing text directly is faster still.
I would have preferred to use BBEdit (or TextWrangler) as the input/output agent for my macro, but since everyone who has a Mac has TextEdit it got the nod.
True.
My macro currently relies on the user to provide keywords they want to leave in the clear, but it shouldn't be too hard to automate that to a fair degree.