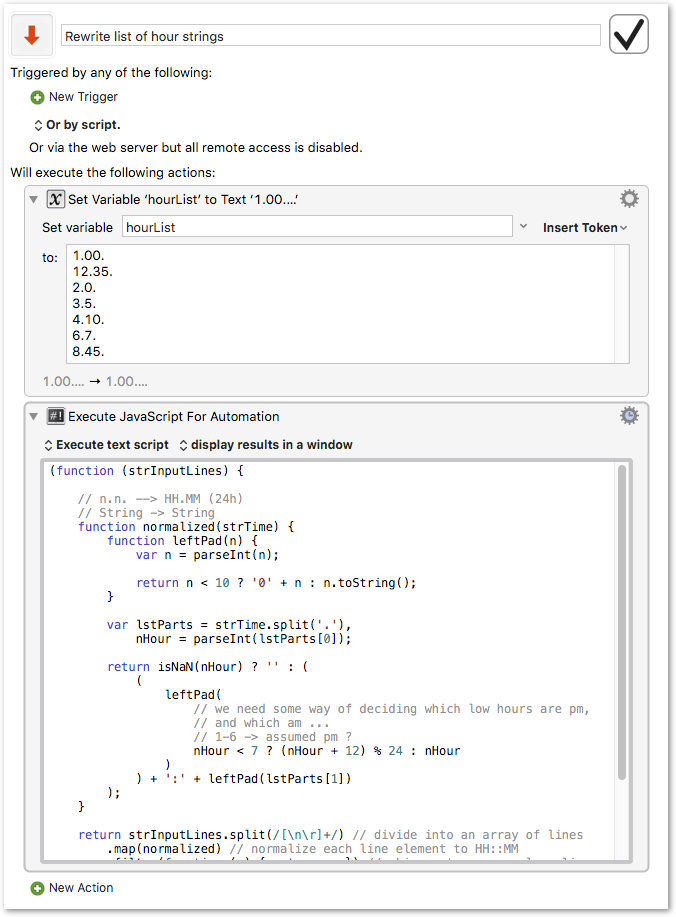
One approach will be to build a search replace regex, and there are a number of regex specialists here,
another would be to put the input column into a variable, and process it with an JavaScript for Automation action.
Draft here - not sure whether this covers your 6am to 9am cases yet, though ...
(function (strInputLines) {
// n.n. --> HH.MM (24h)
// String -> String
function normalized(strTime) {
function leftPad(n) {
var n = parseInt(n);
return n < 10 ? '0' + n : n.toString();
}
var lstParts = strTime.split('.'),
nHour = parseInt(lstParts[0]);
return isNaN(nHour) ? '' : (
(
leftPad(
// we need some way of deciding which low hours are pm,
// and which am ...
// 1-6 -> assumed pm ?
nHour < 7 ? (nHour + 12) % 24 : nHour
)
) + ':' + leftPad(lstParts[1])
);
}
return strInputLines.split(/[\n\r]+/) // divide into an array of lines
.map(normalized) // normalize each line element to HH::MM
.filter(function (x) { return x; }) // skip empty or anomalous lines
.join('\n'); // join array elements as sequence of lines
})(
Application("Keyboard Maestro Engine")
.variables.byName('hourList').value()
);
To be honest this is a bit beyond me. I thought I could just do a delete trailing period.
Substitute colon for middle period.
Test if digits in front of remaining period were greater than 11 or 12, 12 would probably be fine.
If less then add 12 otherwise do nothing.
Then spit the result out as text.
Once pasted into an Excel column already formatted as Time I thought that would do the trick.
I thought I just needed guidance primarily on filtering.
Or am I over simplifying this.
Also, still using version 6 of Keyboard Maestro.
Really appreciate feedback so do not want to sound ungrateful :).
Been messing about with Excel so may sort in that but:
Opening daily csv file that has date column as “n.nn.” or “nn.nn”, for example 1.00. Which I want to change to 13:00 or 12.45 which can obviously stay the same.
These times are race times in UK and earliest I have ever seen is 11:45 AM but usually 12:30 AM would be earliest in winter months. Latest is before 10 PM.
Just swatting up on regex and thought I could just copy and reformat in KM and paste back into same column and format as Time.
Keyboard Maestro made me nuts initially. Things that were no-brainers in QuicKeys were hard in Keyboard Maestro, so so I thought.
( I'd been using QuicKeys since about 1985 though. :)
Once you get used to the way KM does things it becomes easier to use, and the KM community has become very strong – so you can rely on it for help when you need it.
------------------------------------------------------------
tell application "Finder"
set finderSelectionList to selection as alias list
if length of finderSelectionList = 1 then
set cvsFile to item 1 of finderSelectionList
if name of cvsFile does not end with ".csv" then
set continueFlag to false
error "Selected file is NOT a CSV file!"
else
set continueFlag to true
end if
end if
end tell
if continueFlag then
set fileData to readtext cvsFile
set fileData to change "\\b1(?=\\.\\d+)" into "13" in fileData with regexp without case sensitive
set fileData to change "\\b2(?=\\.\\d+)" into "14" in fileData with regexp without case sensitive
set fileData to change "\\b3(?=\\.\\d+)" into "15" in fileData with regexp without case sensitive
set fileData to change "\\b4(?=\\.\\d+)" into "16" in fileData with regexp without case sensitive
set fileData to change "\\b5(?=\\.\\d+)" into "17" in fileData with regexp without case sensitive
set fileData to change "\\b6(?=\\.\\d+)" into "18" in fileData with regexp without case sensitive
set fileData to change "\\b7(?=\\.\\d+)" into "19" in fileData with regexp without case sensitive
set fileData to change "\\b8(?=\\.\\d+)" into "20" in fileData with regexp without case sensitive
set fileData to change "\\b9(?=\\.\\d+)" into "21" in fileData with regexp without case sensitive
end if
(*
NOT IMPLEMENTED:
* Write changed text back to CSV file.
* Open CSV file in Microsoft Excel.
*)
------------------------------------------------------------
You can run it from Script Editor.app.
Select the CSV file you want to process in the Finder, and run the script.
This script ONLY reads the file, processes the data, and provides output in the Script Editor. Other features are on hold until I know more about the desired workflow.
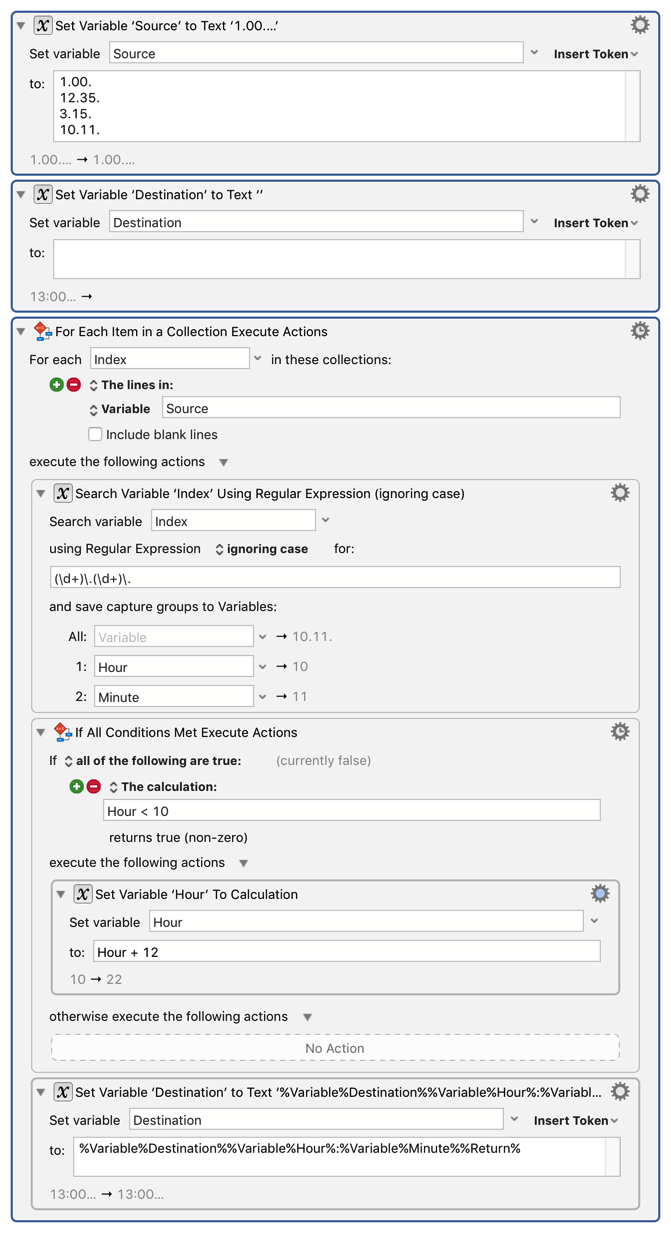
Start with the list of lines in a variable, say Source.
As always, if you have a list of things, start with a For Each action to process each item, in this case with the Lines In collection. That will give you each line in a variable, say Index.