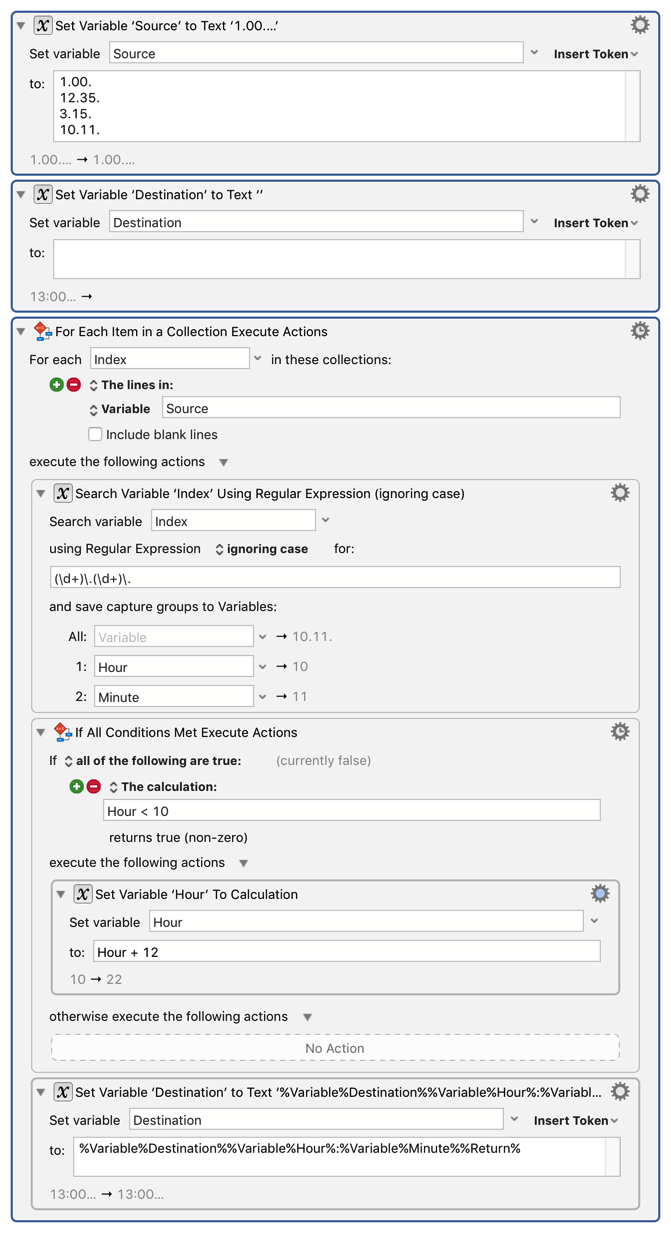
Start with the list of lines in a variable, say Source.
As always, if you have a list of things, start with a For Each action to process each item, in this case with the Lines In collection. That will give you each line in a variable, say Index.
Then use the Search Variable action to break the line up into its component parts.
Use the If Then Else action to check the Hour value and conditionally add 12 hours.
Then add the line to the end of a result variable, say Destination.