I would like to rename hundreds of thousands of files (images). These files all carry an identifier string (a name) but many files that should have the same name used a different name or variant. (I’m aggregating collections of photos. Some collections use one name, some collections another name, etc.) Would anyone be so kind as to suggest an approach for this?
What I have are the files themselves, and (awkwardly) an outline listing each to-be-unique identifier (name or alphanumeric code) as a top-level outline item having all of the aliases (not using “alias” here as a computer term) listed as child items. (I think I can turn this into a table; I’m not sure a table is a good way to store the data. There is more data in the outline than this.) The important structure here is "Single unique identifier with one or more alias identifiers. My task is to, for each file name, find the text string (the alias) in the name, look it up in an outline/table, get the unique ID associated with the text string, and prepend that to the file name.
In the past, which much less data, I did this with a long list of regular expression find & replace actions. I had one expression for each unique-ID/alias pair. (I built the long list of regex’s using, iirc. some kind of mail-merge.)
Currently I have about 600 unique ID’s, and between them about 3,000 aliases. Building and running a 3,000 line search-&-replace macro seems inelegant, possible unworkable, and certainly awkward to maintain.
Can you please provide several examples of your workflow, showing original file name and revised filename, so it is clear what your objective is.
Maybe you could attach a zip file of your search/replace list.
If I understand your objective correctly, I think you might be able to do this with a KM dictionary acting as the table. First, you'd want to create a dictionary with each alias as a key, and the associated unique ID as that key's value. If you can share a sample of how your aliases and IDs are currently organized we should be able to suggest a more precise way of creating the dictionary, but as an example, if the aliases and IDs were separated by commas a la CSV, you could automate the dictionary's creation like this:
Once the dictionary is created, you could then use one For Each for all of the files in question, and a second, nested For Each that iterates through each key/alias in the dictionary, then prepends that key's value, i.e. the unique ID, to the current file's name when it finds a match:
Thanks so much! This looks to be what I was looking for (and more): not just a suggested approach but a template I can adapt. I suspected I’d end up using a dictionary, and have been reading about them. The concept is new to me, so it will take me a few days to work my way through your example.
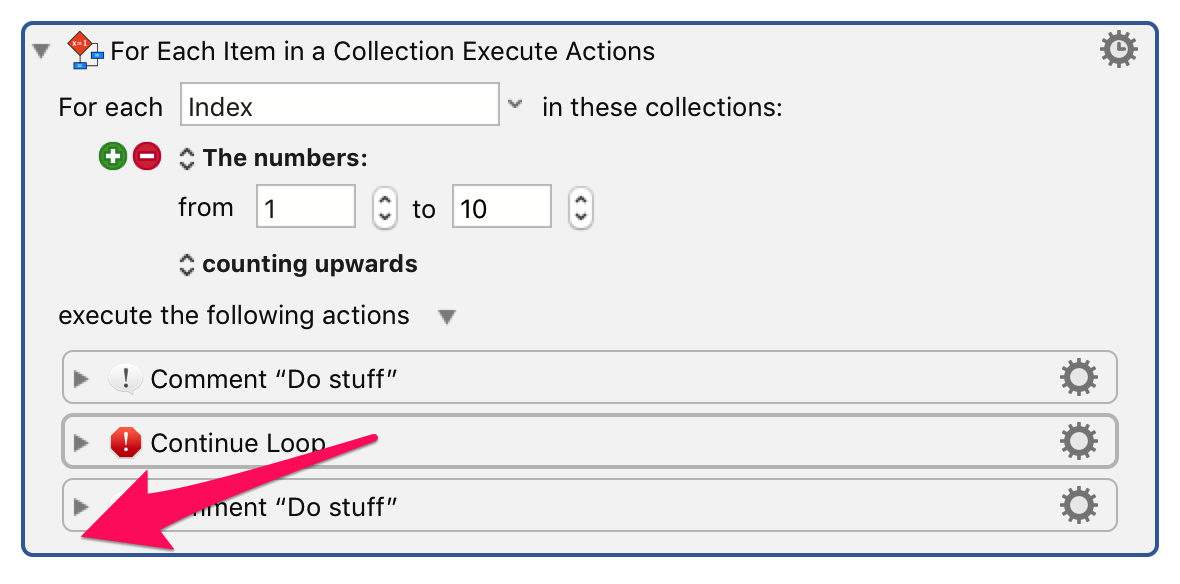
I have one ancillary question already. What does the “Continue Loop” Action do that wouldn’t be done if it weren’t there? I ask out of pure ignorance — I had to look up the Action to find out what it does.
No problem! Dictionaries are fairly new to me too, but the more I’ve learned about them and figured out how to incorporate, the more their worth has become apparent.
I haven’t actually used the “Continue Loop” action in a macro before, so I can’t be fully confident in this answer, but my intent in including it was to have the nested For Each loop stop checking every possible alias in the dictionary against the current file once it found a match and start checking the next file.
Basically, Continue Loop skips execution to the end of the current loop, and then lets the next iteration of the loop run.
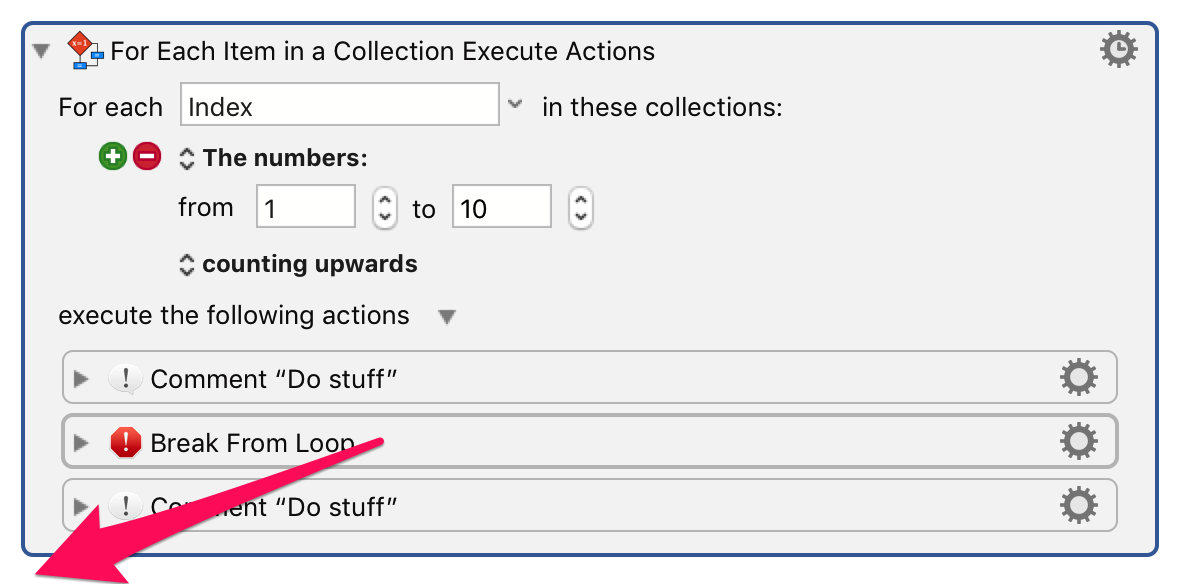
This is as opposed to Retry This Loop, which skips execution back to the beginning of the loop, and performs the same iteration again, and Break From Loop, which skips execution until immediately after the loop.
Thanks for the clarification, Peter! I guess I should have stuck with my initial instinct to use Break From Loop then. @Kirby_Krieger, make sure to change “Continue Loop” to “Break From Loop” when trying this out, as it looks like that’s the action that’s needed to make sure a file with a matched alias doesn’t keep getting checked against every other alias.
Actually, I think having a simple list, one line per unique ID, and using RegEx would work quite well, and be very easy to maintain.
File Format
<id>; <alias1>, <alias2>, <alias3> . . .
One ID per line. For Example:
Example File
image; jpg, png
text; txt, rtd
RegEx to Find ID for a Given Alias
(?mi)^(\w+).* %Variable%Local__Alias%(?:,|$)
Here's an example Macro. You need to change the Actions are in magenta.
Example Results
MACRO: Get ID for Alias RegEx [Example]
#### DOWNLOAD:
<a class="attachment" href="/uploads/default/original/3X/1/d/1dc8106e5ba4663641ca658892ac416eb782eda4.kmmacros">Get ID for Alias RegEx [Example].kmmacros</a> (4.9 KB)
**Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.**
---

This looks fantastic! I’m excited to try it out this weekend. I have not set it up as “one line per unique ID”, but rather as one line per alias. Between that and my simple regex skills I ended up with a something that took minutes to run.
If you run into any snags converting your data to my format of one line per ID, let me know, and I'll try to help.
With only ~600 lines, I think this should run very fast. I've done lots of RegEx on 1,000+ lines, and they all were fast. But then it greatly depends on the RegEx. For this use case, I think it should be very fast.