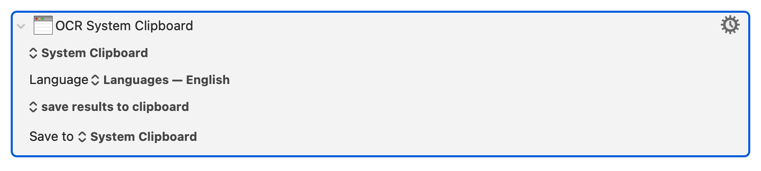
i try to do OCR in python to this image (the number inside can change)
i try everything
tesseract
EasyOCR
but every method doing a lot of mistake
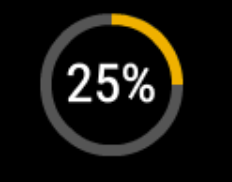
i try to do OCR in python to this image (the number inside can change)
i try everything
tesseract
EasyOCR
but every method doing a lot of mistake
imge = cv2.imread('2233.png', 0)
imge = cv2.resize(imge, None, fx=0.5, fy=0.5)
config = "--psm 7"
imge = pytesseract.image_to_string(imge, config=config)
print(imge)
Hi @Daniel2344,
Keyboard Maestro has a native action for OCR.
However, when I tried the image you uploaded, I got an error:
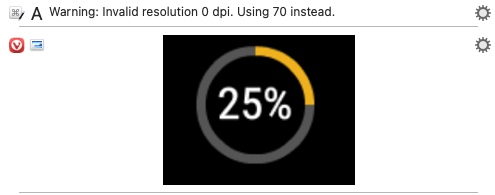
Hi @peternlewis, what does this warning mean and how to pre-process the image file to get OCR to work?
You might find this discussion illuminating. Which would lead you to invert the image for OCR so it's black on white.
The Tesseract library often produces that warning. Keyboard Maestro ignores it if anything else is produced - however if nothing else is produced it allows it through since it might be the case.
In this case, its just not finding anything.
Even inverting it is insufficient, the circle around the outside needs to be removed and it needs to be inverted to get the text to work.
Removing the circle is easily done with cropping.
Keyboard Maestro does not currently have any action to invert an image I'm afraid.
No, but if the color scheme is caused by Dark Mode, that's easily addressed.
I can confirm that both inverting colors and cropping are needed.
Here are my tests (see screenshot of my clipboard history. Order: from bottom to top):
25%.hey, not 25%.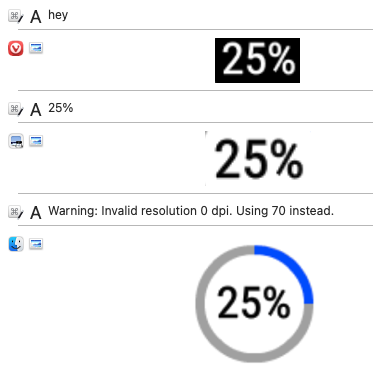
This shows that both color-inverting and cropping are needed.