Hi.
I have read other forum posts on this, in particular:
Pulling in Variables from a .CSV File to Use in Mail Merges
Which is how I got as far as I have below.
I have numerous issues, but the first is, I have two very similar files below. One works with the regex formula, one doesn't. I can't work out for the life of me why.
This example has arisen because of the difficulty of trying to parse .csv files that have been generated from an online form. Because it is comma separated, anyone entering a comma into the form, ruins the automation. So fine, I can manually change the important ones to semicolons - but this example shows that doesn't always work. These are text files, but I've also tried this with .csv and tab separated .csv files. I could also save to XML or any other, I'm open to suggestions! I've spent a lot of time on this but not being a coder, my skills are limited.
The long term project here is to parse the information and then reenter it to other webforms.
Thanks in advance.
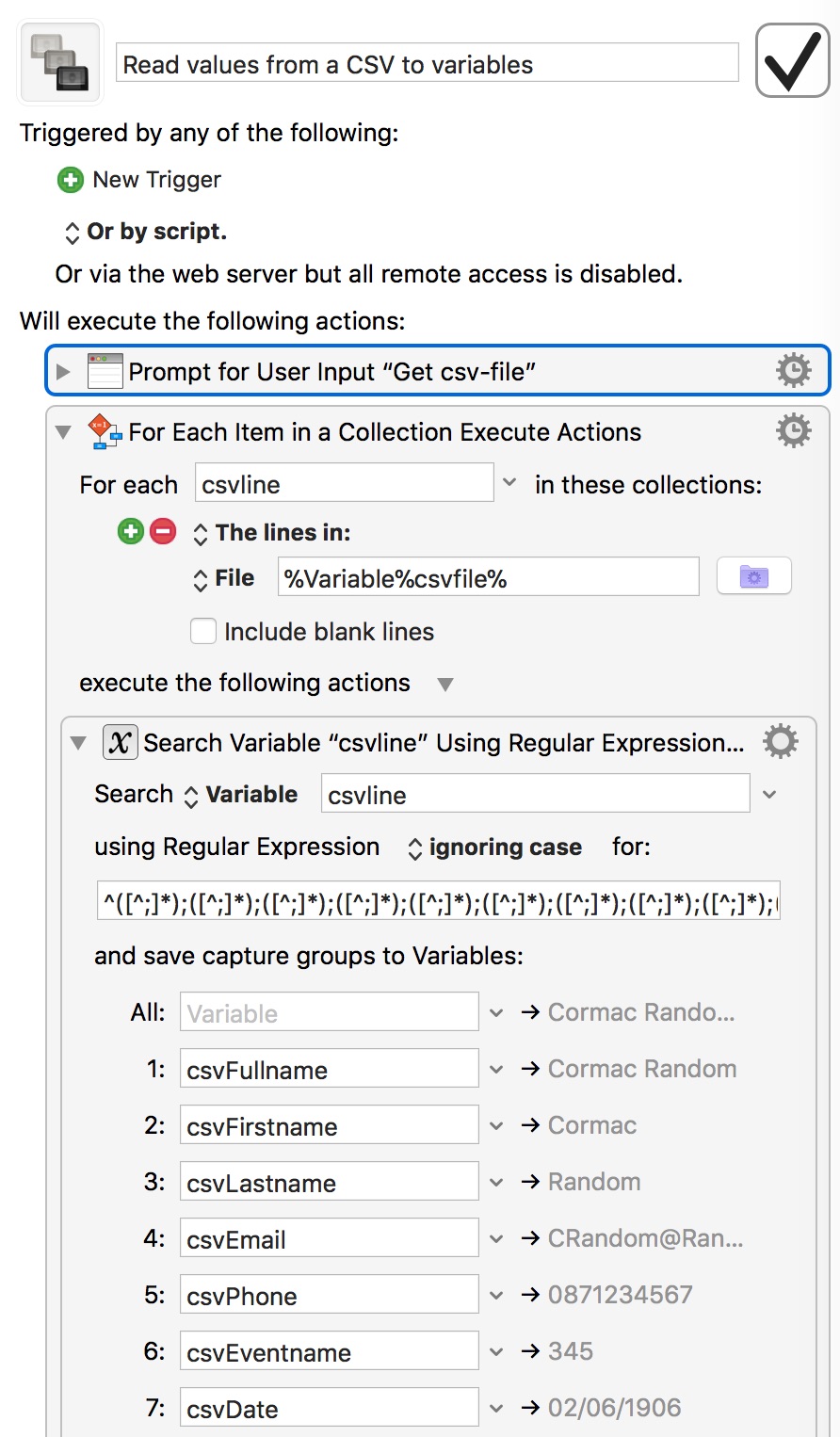
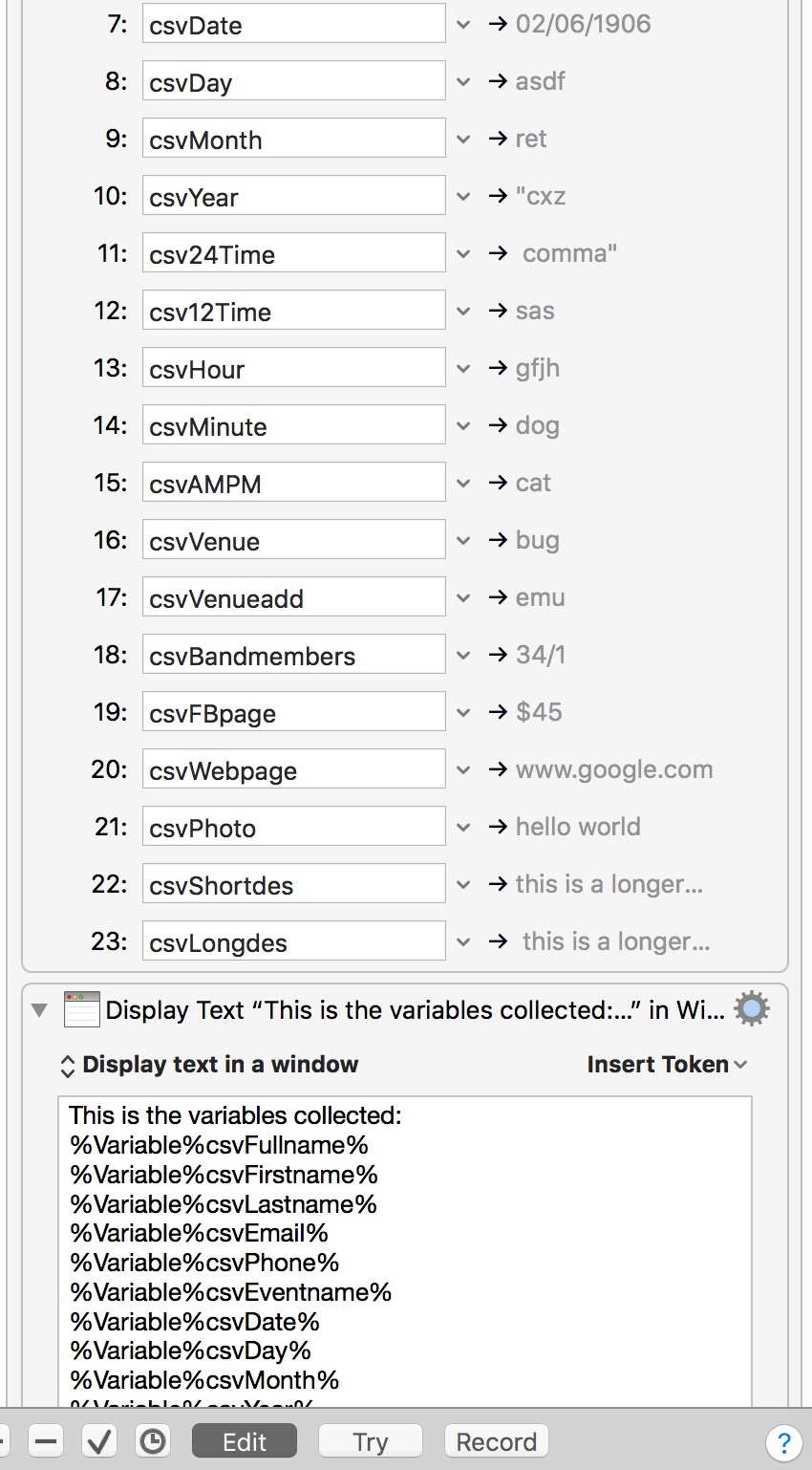
Read values from a CSV to variables modified.kmmacros (7.0 KB)
Read values.zip (4.5 KB)
I rarely reach for Python, but CSV is such a varied and stiff-necked family of unpredictable and indisciplined dialects that this is indispensable:
https://docs.python.org/2/library/csv.html
Contrary to popular belief, CSV actually stands for ‘Come and scatter values’
Oh boy. That is a pretty scary page if you’re new to coding. But if I can cut and paste that first example and have KM execute a python script, I just might be able to get it to work. I’m willing to listen to any suggestions that don’t involve python!
The only plus here is I am in control of the webform, that I am receiving the data from, even though other people are inputting it, so it should stay fairly stable. Thanks @ComplexPoint
If you CSV if very limited in content, then you can parse it with simple regex.
However if your CSV can contain any complex data, or come from any unknown sources, or anything like that, then you really want to use a proper tool for parsing it. CSV may stand for “Comma-separated values”, but it is far far more complicated than that in real world usage. Just look at the wikipedia page for some idea of how complicated it is.
I’ll see if I can sketch a custom action that wraps the Python CSV module.
Can you give us a small sample of the kind of CSV material that you are working with, particularly any lines which seem to be points at which other methods are choking ?
Note, incidentally that for Unicode support in the CSV module, you need Python 3 (the default Python in current macOS distributions is still 2.7, which is scheduled for retirement at some some point in the next year or two).
For instructions on installing Python3, see, for example:
http://docs.python-guide.org/en/latest/starting/install3/osx/
oh boy again. OK, I may end up just postponing this part of the automation process until I have extra time because it’s a fairly simple process to load the csv file into text editor, replace the commas with semicolons using find and replace (keeping an eye out for stray comma’s in the data), and then KM seems to be able to handle it pretty well.
I’ve just realised a mistake I made earlier. Those two files working.txt and notworking.txt were both originally .csv files. I just renamed them because they were opening in excel all the time, and they were easier to edit in plaintext. So those are examples of the types of csv files I’m dealing with.
What I’m actually doing is getting an export from a Contact Form 7 plug in for wordpress, which gives me a csv file. I then copy one line out of that and paste it into another excel sheet which has formula’s etc which does a little parsing of the information, like separates the date into day month year etc, same with time, so I can submit it to multiple websites how they need it. Then I cut and paste that into a final .csv document, which I then need KM to read. It may be possible to automate some of the above steps as well but that’s in the future.
So short answer, @ComplexPoint, the sample of the kind of csv material is in the archive that I managed to stick between to screen shots in the original post.
I’m getting a real life example today of someone filling in the form, so I’ll see how easy I can make the process.
Thanks!
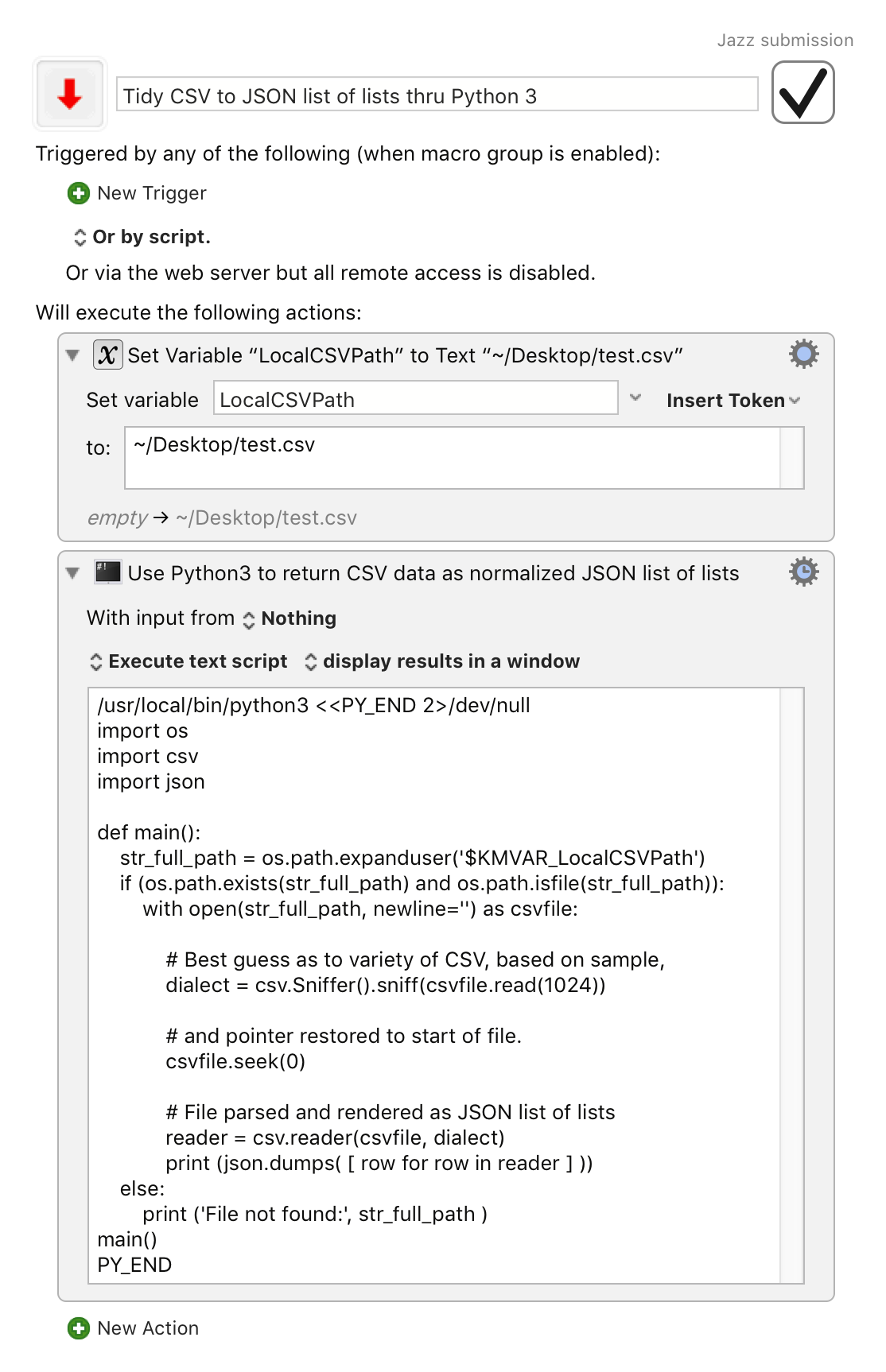
Mileage will vary, but I find it useful to first normalize the data to a predictably formatted JSON list of lists, by letting the Python CSV module analyse a sample of of the CSV to detect its dialect, parse the CSV accordingly, and return it as JSON.
Here is a working sketch. Note, however, that to handle Unicode (you almost always will need to) you need to install and use Python 3, rather than the default Python 2 which is still preinstalled on macOS systems, but which has a rapidly approaching horizon.
An advantage of the JSON format is that you can read it directly to live data using JSON.parse(string) in an execute JavaScript for Automation action in Keyboard Maestro.
(Another approach would, of course, be to use Python 3 to detect and read the wild variety of CSV, and then write the data out again in something more tightly defined, like Excel CSV)
Tidy CSV to JSON list of lists thru Python 3.kmmacros (19.0 KB)
Python 3 source for a KM Execute a Shell Script action
#!/bin/bash
/usr/local/bin/python3 <<PY_END 2>/dev/null
import os
import csv
import json
def main():
str_full_path = os.path.expanduser('$KMVAR_LocalCSVPath')
if (os.path.exists(str_full_path) and os.path.isfile(str_full_path)):
with open(str_full_path, newline='') as csvfile:
# Best guess as to variety of CSV, based on sample,
dialect = csv.Sniffer().sniff(csvfile.read(1024))
# and pointer restored to start of file.
csvfile.seek(0)
# File parsed and rendered as JSON list of lists
reader = csv.reader(csvfile, dialect)
print (json.dumps( [ row for row in reader ] ))
else:
print ('File not found:', str_full_path )
main()
PY_END
oh boy oh boy.
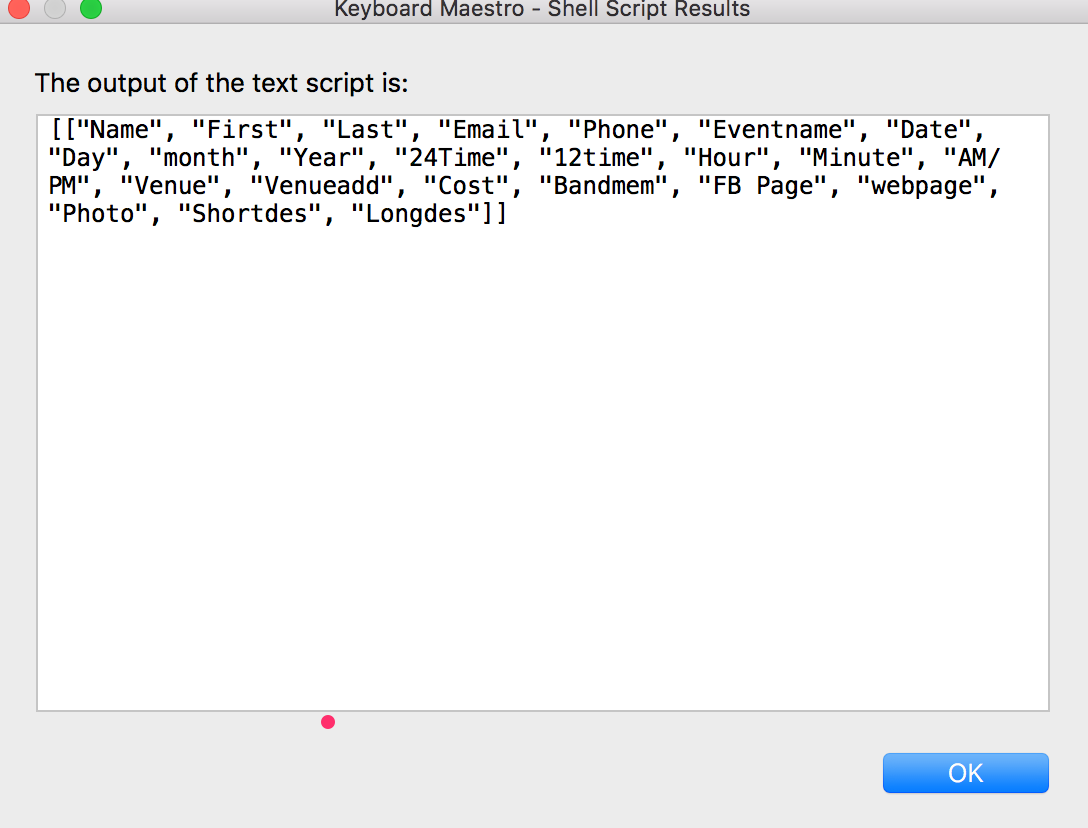
I managed to install python3. And I ran your macro against a test file. It gives me (using the a .csv file)
Is that the expected result? Looks fine to me, but I don't know what a JSON list of lists looks like.
So if what I have in my window is a JSON list of lists, I now need to use JSON.parse(string) to convert that to variables in KM? I'll start looking for how to do that! 
Thanks again.
You’re making good progress – that certainly is JSON.
It looks like a single header line – is that all there was in the file ? No following lines of data ?
Now that it’s in JSON format, you could either use JSON.parse, or take advantage of the fact that it should now me a more regular and predictable target for regular expressions
If the header is followed by one or more data lines, then we should be able to write a short piece of JavaScript to bind each piece of data to a matching KM variable.
Well it starts out a bit messier, but I do some manipulation to reduce it to the single line - those examples end up being the actual data without the header. I used a header version to avoid sharing real life details. I’ve looked into using JSON.parse It basically requires me to learn javascript I believe. I think that’s beyond me right now!
I’ll see how I get on over the next week or so, but it might be easiest to just fix it up manually. Thanks for your help!
I’ve just had a look at your working.txt and notworking.txt
The difference is line/record delimiters: in the version which is not working, the fields are broken into two lines between Piano and Joe Bass (an \n or \r must have sneaked in somehow)
That means that when any process walks through them, it thinks it is looking at two records, one with a shortened number of fields, followed by another another (also short) which doesn’t match the field columns.
Hi @ComplexPoint,
I’ve just been sitting here going through all this. That makes sense. It doesn’t like the carriage returns. Would using javascript and JSON.parse fix this?
I’m attaching a file called cfdb7-2017-11-15.csv which I download from the server. I paste the data line of that into my submission template.csv (also attached) which tidies it up a bit. I then cut and paste the result it gives me into a third file which KM reads (and I usually need to modify this, to delete CR’s, extra semicolons). I need to paste as values into this third one, and the other thing is text entries (like a phone number +3531234567 gets converted into a 453E+12 type number, and a split cost like 12/10 turns into a decimal. So perhaps the JS way is superior and worth the effort. If you have the time and inclination you can have a look, but you’ve helped enough as well, I don’t want to take more of your time.
Cheers,
Damian
EDIT: Attachment removed - wrong file
I can see some Excel files in there – should I also see one called
cfdb7-2017-11-15.csv ?
Might it have slipped out of the zipping ?
Good point. Indeed. Wrong files.
Archive 2.zip (30.6 KB)
Looks very difficult to solve downstream of that rather unconstrained and under-grouped data collection …
Really needs more rigour and ‘bracketing’ of the fields upstream (form design ?)
At the moment there are really no reserved field delimiters or record delimiters – it must be creating a huge amount of work for you. Fixing it upstream should make a big difference …
I’m not sure I understand fully. Especially by ‘reserved field delimiters or record delimiters’. But I do think I generally understand what you’re saying. The most obvious changes I can think to the form are to separate the address into separate fields, and to be clear in my instructions for certain things - like not to use a currency symbol and not to use a semicolon or blank lines.
It’s not causing me too much work because it’s just a small side project, not my day job or anything, in fact it’s all also a part of just learning KM and automation, while having a real life application, but there are obvious limit to what I can do. At the moment it takes about 5 minutes or so to manually adjust everything so that KM can read it. That’s not too bad for now, and KM reading it, means I’ve automated a lot of stuff, filling in webforms basically. Anyway, thanks for all your help, I’ve got a lot to think about. I’ll work on the form for a start.
1 Like
reserved field delimiters or record delimiters
Just that there needs to be:
- One unique character (or short string of characters) which marks the definite end of one record and the start of another (in CSV that's generally assumed to be some LineFeed / CarriageReturn combination, so any CR or LF inside the data fields will prevent interpretation. (Record delimiter). And,
- One unique character (or short string of characters) which marks the definite divider between fields. (Field delimiter).
(CSV formats often make some use of quoting to cope with fields in which a delimiter character needs to be used as data)
So in my example, there are many ways for the form to produce CR and LF’s, thereby starting a new record, and no way of preventing the user entering commas, which act as the definite divider. I get it. Yes, the quoting has happened and is a pain because it turns my entry from
Damian Evans
into
"Damian Evans"
which I don’t want either.
Also, sometimes in the long description people use quotation marks, so that gets messy also, I can’t use them as definite dividers. Semicolons seem to make the most sense.
It’s certainly a messy business. I’ll give it some good thinking. 
Yes, the quoting has happened and is a pain
Well, the quoting may turn out to be your friend:
- CSV parsing software (like Python3 CSV) will treat it as 'syntax' and can drop it automatically from the output,
- The quoting can solve some of the problems of special characters like commas occurring within the data - CSV parsers can ignore such things if they occur inside a string that is between quotes.
Good luck !
1 Like