Mileage will vary, but I find it useful to first normalize the data to a predictably formatted JSON list of lists, by letting the Python CSV module analyse a sample of of the CSV to detect its dialect, parse the CSV accordingly, and return it as JSON.
Here is a working sketch. Note, however, that to handle Unicode (you almost always will need to) you need to install and use Python 3, rather than the default Python 2 which is still preinstalled on macOS systems, but which has a rapidly approaching horizon.
An advantage of the JSON format is that you can read it directly to live data using JSON.parse(string) in an execute JavaScript for Automation action in Keyboard Maestro.
(Another approach would, of course, be to use Python 3 to detect and read the wild variety of CSV, and then write the data out again in something more tightly defined, like Excel CSV)
Tidy CSV to JSON list of lists thru Python 3.kmmacros (19.0 KB)
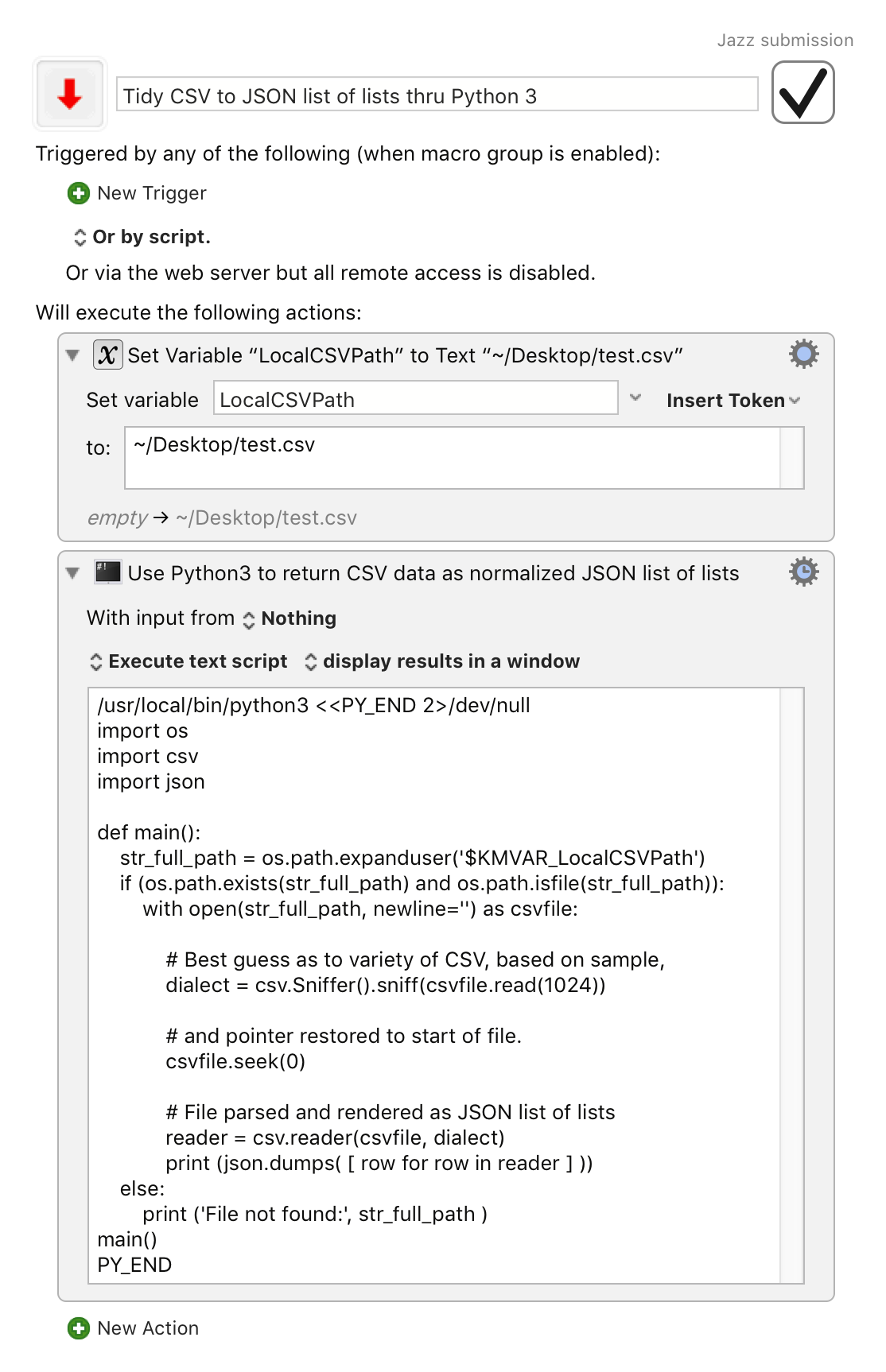
Python 3 source for a KM Execute a Shell Script action
#!/bin/bash
/usr/local/bin/python3 <<PY_END 2>/dev/null
import os
import csv
import json
def main():
str_full_path = os.path.expanduser('$KMVAR_LocalCSVPath')
if (os.path.exists(str_full_path) and os.path.isfile(str_full_path)):
with open(str_full_path, newline='') as csvfile:
# Best guess as to variety of CSV, based on sample,
dialect = csv.Sniffer().sniff(csvfile.read(1024))
# and pointer restored to start of file.
csvfile.seek(0)
# File parsed and rendered as JSON list of lists
reader = csv.reader(csvfile, dialect)
print (json.dumps( [ row for row in reader ] ))
else:
print ('File not found:', str_full_path )
main()
PY_END