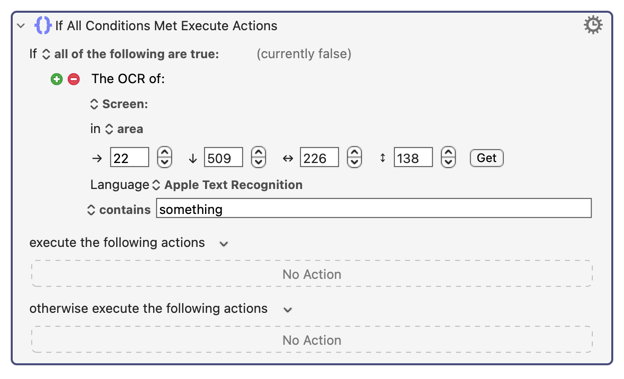
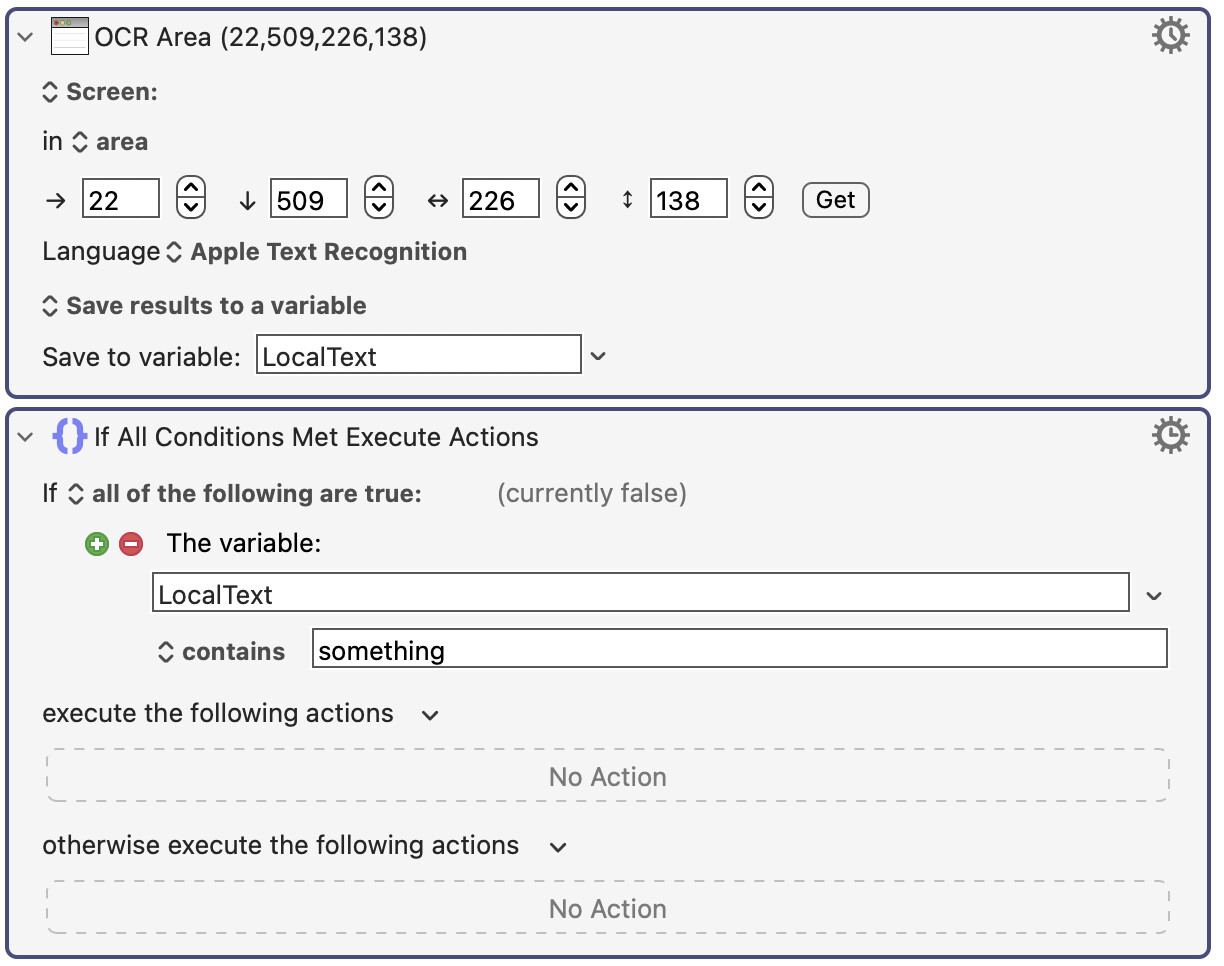
But why should these two pieces of code have significantly different results? They should both get very similar results, since they are both using Apple OCR. And yet the first block of code above gets results similar in accuracy to the less accurate non-Apple OCR.
Just a wild guess, but is it possible that the first action above is actually not using Apple OCR even though it says it is? This is what the results I'm getting suggest to me.
Moreover! I just put these two sets of actions in a loop that repeated 111 times, and the first method took 65 seconds while the second method took 10.2 seconds. I think that's convincing evidence that the first method is using the wrong OCR!
Your logic sounds good to me. It'll be interesting to see what Peter has to say.
Just for kicks and giggles, have you looked in the KM log file? I wonder if it leaves any evidence to support your theory? I'm not sure just what Peter logs during these actions. Just a thought.
Thanks. In the meantime the workaround above solves the problem.
Another solution that you might want to consider, is the feature you added to "Find Image" which as an option box called "Wait for Image" which you could also add to the OCR action called "Wait for Text" which could wait for "any text" to return. This feature would be better if you could specify the text we are waiting for, but that would add complications.