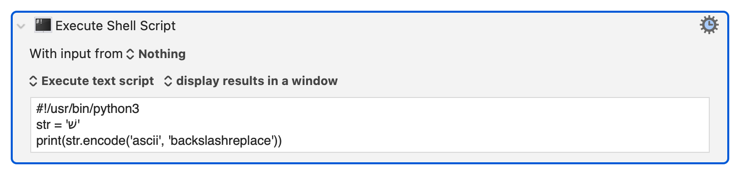
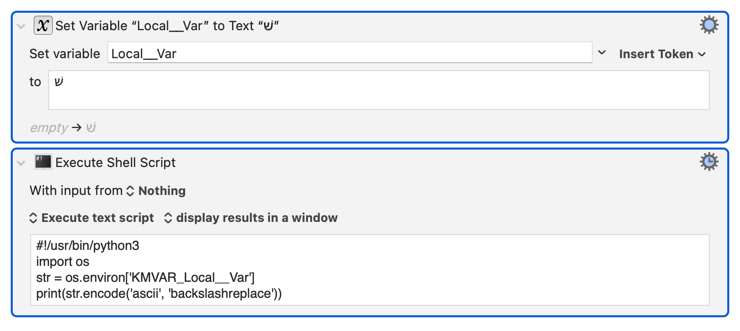
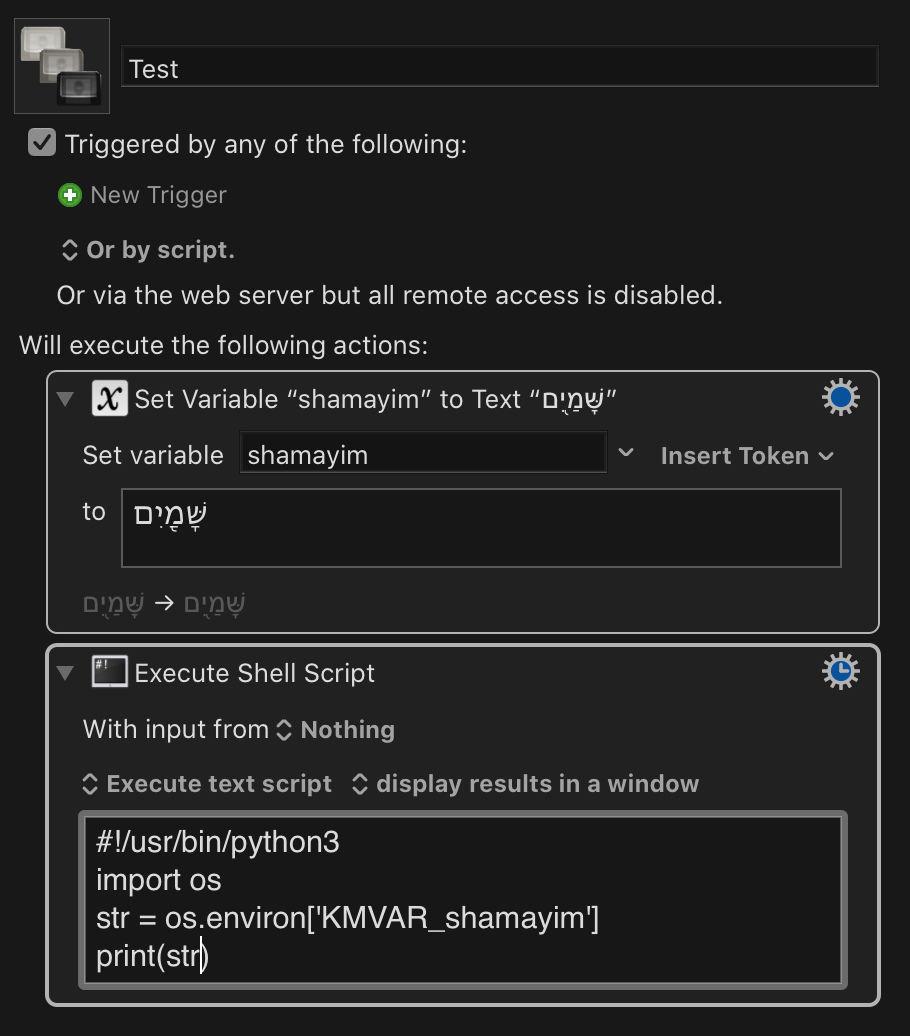
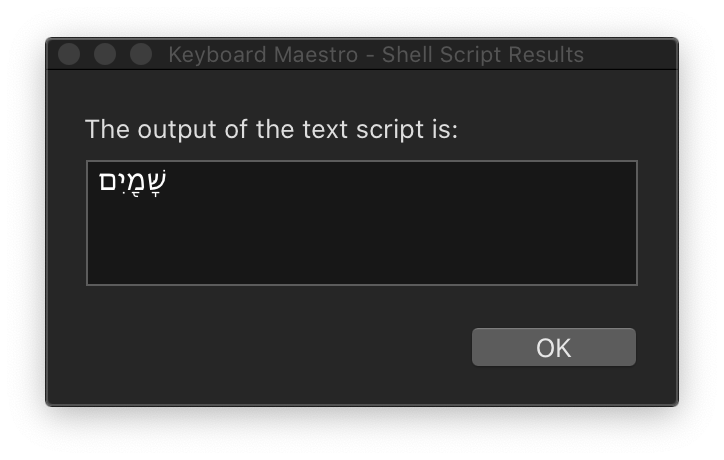
My issue was not clear when I had the problems described above. Now It becomes clearer to me after some tests.
Copy from and Paste to:
Firefox:
Firefox to Firefox: NO normalization
Other apps to Firefox: NO normalization
Firefox to other apps: normalization
Even if we use AppleScript, JXA, or Python to directly read the SystemClipboard that contains the text copied from Firefox, the text is still normalized. Since copying and pasting from Firefox to Firefox does not involve normalization, Firefox probably does not normalize the text during the copy process. I have no idea when the normalization happens.
Safari (MacOS, not iOS):
Safari to Safari: normalization
Other apps to Safari: normalization
Safari to other apps: NO normalization
For Safari (MacOS), the normalization also happens at least on Canvas by instructure.com. In the fill-in-blank questions of Classic Quizzes, when students type Hebrew words in quizzes and hit "submit", the input was normalized, but the answer key was not. In that of the New Quizzes, however, both the input and the answer key are normalized. It's a mystery to me.
Chrome:
Chrome to Chrome: NO normalization
Other apps to Chrome: NO normalization (Firefox overrides)
Chrome to other apps: NO normalization (Safari overrides)
I believe other Chromium-based browsers should work the same way as Chrome. But I only tested on Brave Browser.
Conclusion: Firefox and Safari behave in the opposite way. Chrome behaves normally and consistently (except when it is overridden by Firefox and Safari).
Unless developers for Safari and Firefox make changes, I guess we have to live with it.
As for as Keyboard Maestro is concerned:
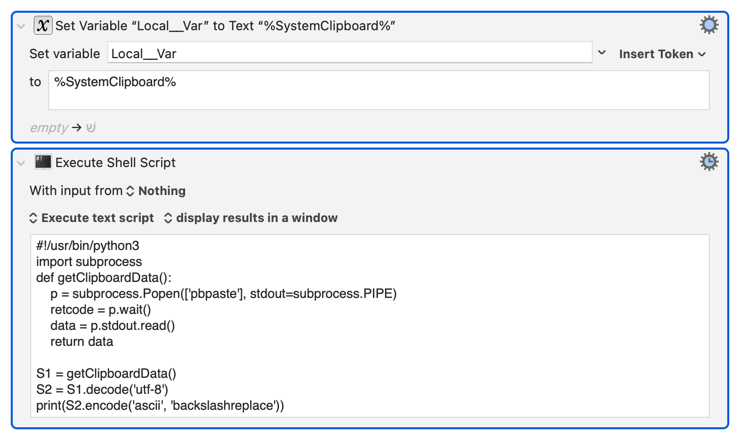
When Keyboard Maestro use Python gets the value of a variable via os.environ KMVAR, the string is normalized in the process.
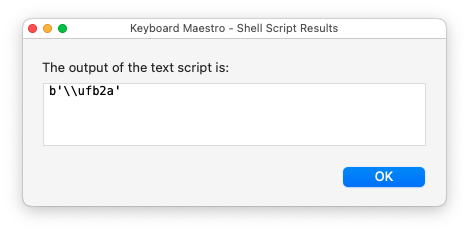
But if it reads directly from the SystemClipboard, the text is NOT normalized.
When Keyboard Maestro use JXA to get the value of a variable or read directly from the SystemClipboard, the text is NOT normalized.