It is provided as an example of how you can use submacros with this macro.
Be sure to read the Macro Setup in the Release Notes section below.
Use Case
Make it easy for most users, most use cases, to extract all hyperlinks in a list on a web page, and then process each link.
None of which requires the user to understand or change JavaScript.
Most often, these list of links will either be within a major HTML element with a unique Class, or each link will be within an element that has the same Class for all of these elements.
You can easily find this HTML element, and its Class, by using the Inspector in either Chrome or Safari.
This method/macro won't work in all cases, but hopefully it will in most cases.
If it does not work for you, we can probably figure out a method that will. Just post the URL of the target page.
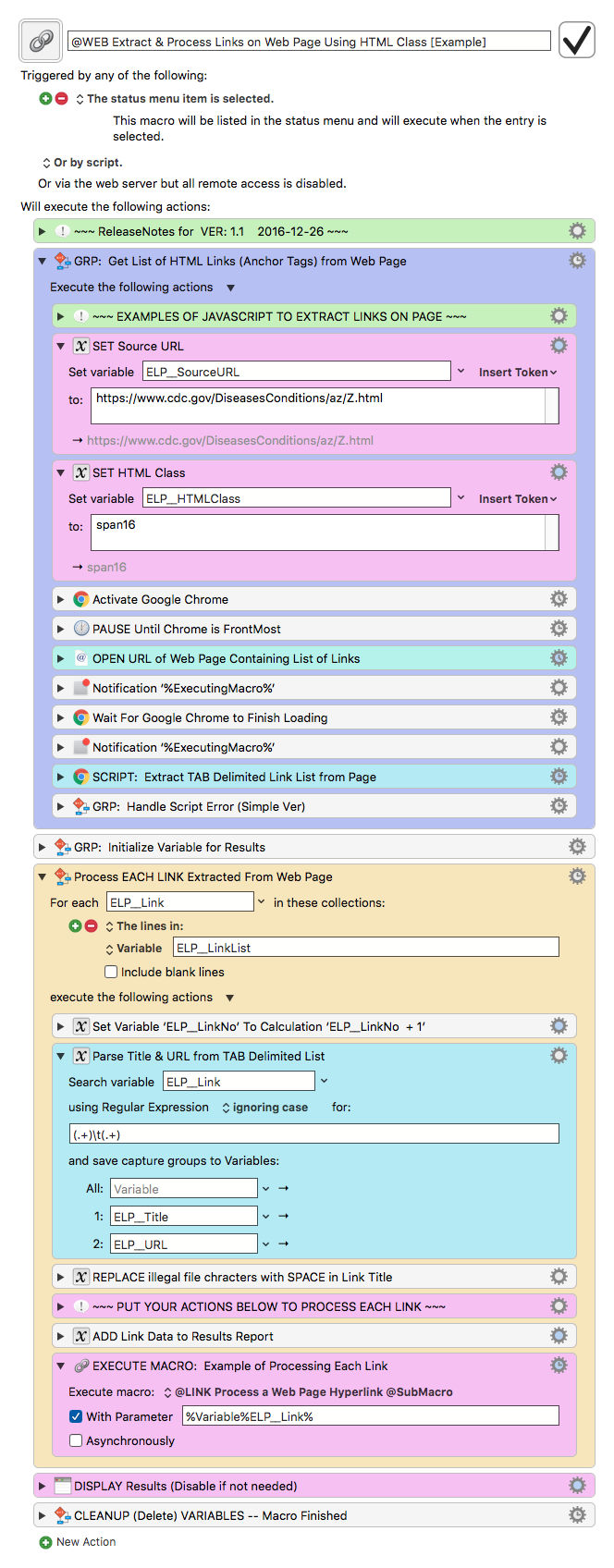
Extract Web Page Links Using HTML Class, and Process Each Link
MACRO SETUP
Note that all Actions with the magenta color are designed to be changed by you.
In some cases, they MUST be changed to fit your specific requirements.
Move Macro to Macro Group that limits trigger to apps you plan to use it with
(Note: This macro can be used ONLY with Google Chrome, but could be easily changed to use Safari, just by replacing the Chrome Actions with Safari Actions)
Assign a Trigger
Set the below Action "SET Source URL" to the URL of the Web Page that contains the list of links.
Set the below Action "SET HTML Class" to the unique Class of the HTML Element that contains each, or all, of the list of links.
ADD Actions at the bottom of the Macro to process each link as you desire.
If your web page has a lot of links, it is best to first TEST on a similar page with just a few links)
HOW TO USE:
Open Google Chrome Browser (any page)
Trigger this Macro
WHAT IT DOES:
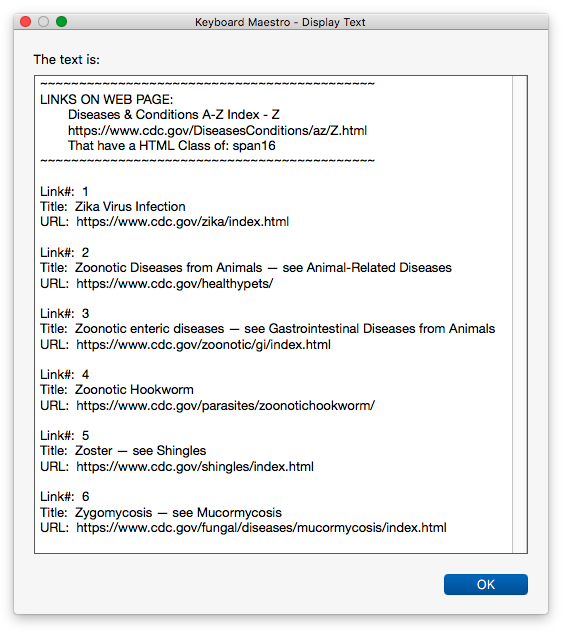
Gets a HTML Collection of all Elements that have the specified Class Name
Gets a HTML Collection of all Links (Anchor Tags) within that collection
Builds a TAB delimited list (array) of Link Text & URL from that collection
Returns a TAB delimited String, with each link on a separate line
FOR EACH link/line in that String:
Using RegEx, parses it into Title and URL
Process that Link
TAGS: @Links@Web@JavaScript@HTML
USER SETTINGS:
Any Action in magenta color is designed to be changed by end-user
This macro uses Google Chrome, but can be easily changed
ACTION COLOR CODES
To facilitate the reading, customizing, and maintenance of this macro,
key Actions are colored as follows:
GREEN -- Key Comments designed to highlight main sections of macro
MAGENTA -- Actions designed to be customized by user
YELLOW -- Primary Actions (usually the main purpose of the macro)
ORANGE -- Actions that permanently destroy Varibles or Clipboards
REQUIRES:
(1) Keyboard Maestro Ver 7.3+
(2) Yosemite (10.10.5)+
JavaScript
'use strict';
(function run() { // function will auto-run when script is executed
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
var ptyScriptName = "Extract Link List Using Class Name"
var ptyScriptVer = "1.1"
var ptyScriptDate = "2016-12-26"
var ptyScriptAuthor = "@JMichaelTX"
//~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~~
var returnResults = "TBD"
//--- Get Class Name from KM of Major HTML Elements Which Contain the Link ---
var classStr = document.kmvar.ELP__HTMLClass
//--- IF KM VAR "ELP__HTMLClass" IS EMPTY, RETURN ERROR ---
if (!classStr) {
returnResults = "[ERROR]\n\n"
+ "SCRIPT: " + ptyScriptName + " Ver: " + ptyScriptVer + "\n"
+ "Error Number: " + "C101" + "\n"
+ "Invalid HTML Class:" + ">>>" + classStr + "<<<"
+ "\n Must be set in KM Variable: 'ELP__HTMLClass'"
}
else {
//--- Get Element Collection Using Class Name ---
var majorElem = document.getElementsByClassName(classStr);
//--- Get Links (Anchor Elements) Within the majorElem Collection ---
var linkElem = majorElem[0].getElementsByTagName("a")
//--- Build TAB Delimited List of Link Text and URL ---
var linkList = [];
var numElements = linkElem.length;
for (var iElem = 0; iElem < numElements; iElem++) {
linkList.push(linkElem[iElem].textContent + "\t" + linkElem[iElem].href);
}
returnResults = linkList.join("\n");
} // END of else
//--- Merge Link List into String using LineFeed, & Return to KM --
return returnResults;
})();
I'm new to Keyboard Maestro and I downloaded this Macro @WEBExtract & Process Links on Web Page Using HTML Class [Example]. When I run it the below is the error message I'm getting.
"Search regular expression failed to match (.+)\t(.+) Macro trying cancelled (while executing Parse Title & URL from TAB Delimited List)."
I'm running Mac OS High Sierra. i purchase clothes from an online wholesaler LAShowroom.com. Ultimately I would like to build a macro that logs in to LAShowroom, goes to the "Orders" page and clicks all of the links that say "Download Image." This action opens a new tab and automatically saves the images to my Downloads folder.
I've successfully built the macro to take me to the "Orders page" and click the first "Downoad Image" link using the built in macro actions. But there are always multiple links with the same title.
I'm using your macro now to append to mine to complete the macro. The class is "image-download"
What's a bit more difficult is downloading the files.
You can't automatically (afaik) get either Safari or Chrome to download them – not without doing some UI-Scripting anyway.
But...
It's not too hard to download them with the curl command line utility. (I would do this in the Terminal, so I had feedback on the downloads.)
Or you could use Progressive Downloader. I believe it's still free, but you can buy it on the app-store for ($2.99 U.S.) to support the developer who's a good guy.
Or you could use Leech ($6.00 U.S.), which is my go-to downloader utility.
Both Progressive Downloader and Leech are AppleScriptable.
Oh, yeah. You could always just paste the PDF links into Safari's “Show Downloads” window.
thank you very much, that's incredibly helpful. I just purchased Leech and it looks like the perfect tool for the job (saw your name in the release notes from 2016, too, so you really must be a long-time supporter! :))
I got one more question, since I'm not too familiar with AppleScript (yet). I saw that the command "download URLs" would be helpful for me to achieve what I would like to do.
What would the AppleScript then look like? Could you (once more) point me in the right direction?
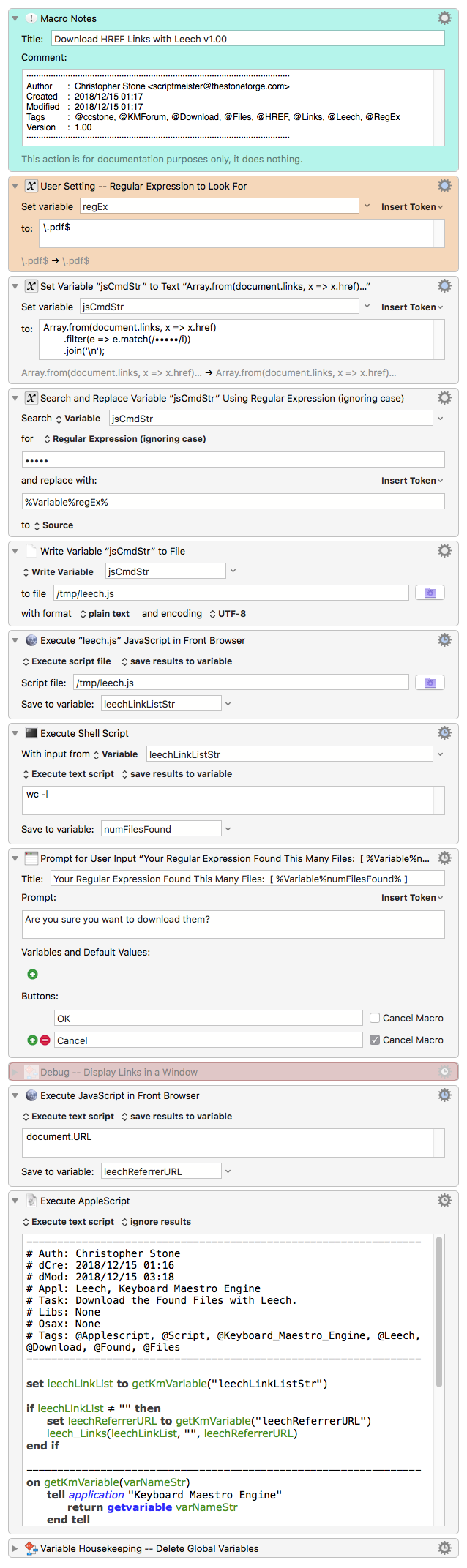
The basic code for Leech is pretty simple. The primary working code is only one line.
AppleScript Handler for Leech
----------------------------------------------------------------
# linkListStr == A linefeed delimited text list of URLs to download.
# downloadPath == "" empty string to use default location
# downloadPath == Full folder path PLUS file NAME of first file ONLY.
# refererURL == The URL of the page where the file URLs are found.
leech_Links(linkListStr, downloadPath, refererURL) -- call-to-handler
----------------------------------------------------------------
--» HANDLER
----------------------------------------------------------------
on leech_Links(linkListStr, downloadPath, refererURL)
# Assign an empty string to "downloadPath" to download to Leech's default location.
# The full "downloadPath" must contain the NAME of the first downloaded file!
tell application "Leech"
if not running then
run
delay 1
end if
activate
download URLs linkListStr to POSIX path downloadPath with referrer refererURL
end tell
end leech_Links
----------------------------------------------------------------
Drop Leech on the Applescript Editor.app to examine its sdef (scripting dictionary).
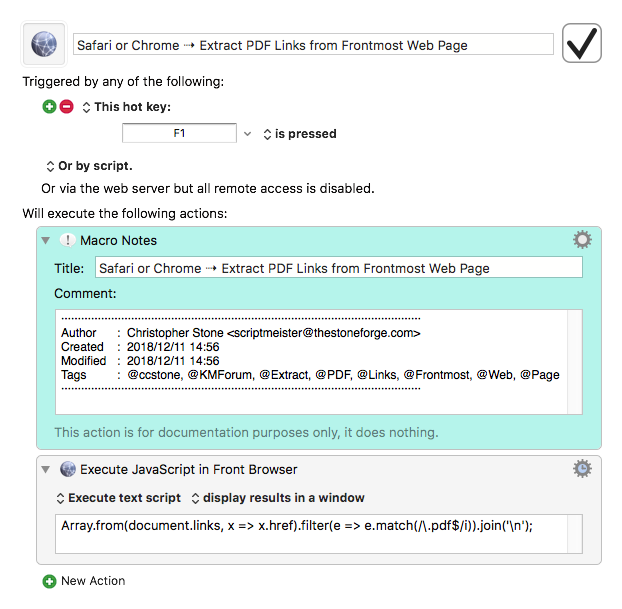
Here's a complete working AppleScript solution for downloading files from Safari:
Full AppleScript Code for Safari -- Leech Downloader
----------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2018/12/13 17:17
# dMod: 2018/12/15 02:33
# Appl: Leech, Safari
# Task: Extract HREF URLs from Safari with a Regular Expression and Download with Leech.
# Libs: None
# Osax: None
# Tags: @Applescript, @Script, @Leech, @Safari, @Extract, @HREF, @URLs, @Regular, @Expression, @RegEx, @Download
# Test: Only on macOS 10.12.6 with Leech 3.1.2
# Vers: 1.00
----------------------------------------------------------------
try
----------------------------------------------------------------
# ••••• USER ••••• RegEx for Link Extraction •••••
----------------------------------------------------------------
set linkListStr to extract_Href_Links_Safari("\\.pdf")
----------------------------------------------------------------
set refererURL to safariURL()
if linkListStr = "" then error "No links were found in front Safari Window!"
set linkListStr to paragraphs of linkListStr
set linkCount to length of linkListStr
set areYouSure to display dialog "Your Regular Expression Found This Many Files: [ " & linkCount & " ]" & ¬
linefeed & ¬
linefeed & ¬
"Are you SURE you want to download them?"
if button returned of areYouSure ≠ "OK" then
error "Bad Button!"
end if
set fileName to extractFilenameFromURL(item 1 of linkListStr)
set {oldTIDS, AppleScript's text item delimiters} to {AppleScript's text item delimiters, linefeed}
set linkListStr to linkListStr as text
set AppleScript's text item delimiters to oldTIDS
----------------------------------------------------------------
# ••••• USER ••••• Download Location •••••
----------------------------------------------------------------
# User selected ONLY one or the other of the download location options
set downloadPath to "" -- Leave empty string to download to Leech's default location.
# To download to a custom location uncomment this - MUST end with a file name.
# - Leech will create directories that don't already exist.
# set downloadPath to "~/Downloads/Test_Leech_Download/" & fileName
----------------------------------------------------------------
leech_Links(linkListStr, downloadPath, refererURL)
on error e number n
set e to e & return & return & "Num: " & n
if n ≠ -128 then
try
tell application (path to frontmost application as text) to set ddButton to button returned of ¬
(display dialog e with title "ERROR!" buttons {"Copy Error Message", "Cancel", "OK"} ¬
default button "OK" giving up after 30)
if ddButton = "Copy Error Message" then set the clipboard to e
end try
end if
end try
----------------------------------------------------------------
--» HANDLERS
----------------------------------------------------------------
on doJavaScriptInSafari(jsCMD)
try
tell application "Safari" to do JavaScript jsCMD in front document
on error e
error "Error in handler doJavaScriptInSafari() of library NLb!" & return & return & e
end try
end doJavaScriptInSafari
----------------------------------------------------------------
on extractFilenameFromURL(theURL)
set {oldTIDS, AppleScript's text item delimiters} to {AppleScript's text item delimiters, "/"}
set fileName to last text item of theURL
set AppleScript's text item delimiters to oldTIDS
return fileName
end extractFilenameFromURL
----------------------------------------------------------------
on extract_Href_Links_Safari(regexPatternStr)
set regexPattern to regexPatternStr
set jsCmdStr to "Array.from(document.links, x => x.href)
.filter(e => e.match(/" & regexPattern & "/i)).join('\\n');"
set jsResult to doJavaScriptInSafari(jsCmdStr) of me
return jsResult
end extract_Href_Links_Safari
----------------------------------------------------------------
on leech_Links(linkListStr, downloadPath, refererURL)
# Assign an empty string to "downloadPath" to download to Leech's default location.
# The full "downloadPath" must contain the NAME of the first downloaded file!
tell application "Leech"
if not running then
run
delay 1
end if
activate
download URLs linkListStr to POSIX path downloadPath with referrer refererURL
end tell
end leech_Links
----------------------------------------------------------------
on safariURL()
tell application "Safari"
try
if front document exists then
tell front document
set _url to its URL
try
_url
on error
set _url to false
end try
end tell
else
set _url to false
end if
return _url
on error
error "Failure in safariURL() handler of Internet Library."
end try
end tell
end safariURL
----------------------------------------------------------------
Here's a complete working Keyboard Maestro macro that breaks things up into easier to understand bits.
@ccstone Would you be possible to adjust the filter so that it would catch all image files? ... something that would catch jpg, jpeg, png, and gif files for instance?
I've seen in the forums some much longer methods of extracting and filtering href links from an HTML page ... is there any downside to your super simple code?
A big thanks for all the macros and code-bits you provide here in the forums!!
I don't know offhand when JavaScript adopted that method of filtering, but unless you go back to an ancient system with a very old version of JavaScript it ought to work.
I reckon this will do what you want:
Array.from(document.links, x => x.href).filter(e => e.match(/\.(gif|jpe?g|png)$/i)).join('\n');
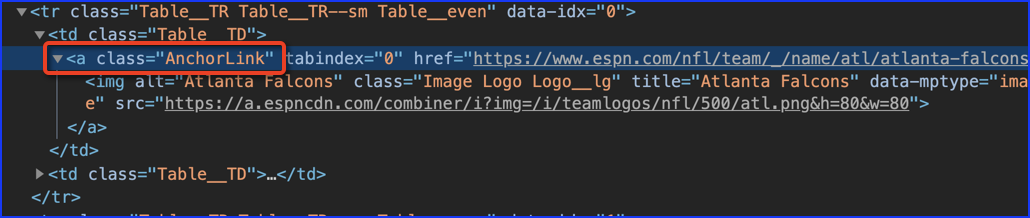
Any ideas how to adapt the code so that it would also capture images from a URL like this? I'm guessing it has to do with embedded images vs links to images?
I don't have time to fool with this right now, but I do have a prepackaged solution in AppleScript:
This is old code that's been updated a few times, and it still works well.
-Chris
--------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2010/11/13 21:15
# dMod: 2021/01/25 14:07
# Appl: Google Chrome & BBEdit
# Task: Send Embedded Images Links to BBEdit.
# Libs: None
# Osax: None
# Tags: @Applescript, @BBEdit, @Google_Chrome, @Send, @Embedded, @Image, @Links
--------------------------------------------------------
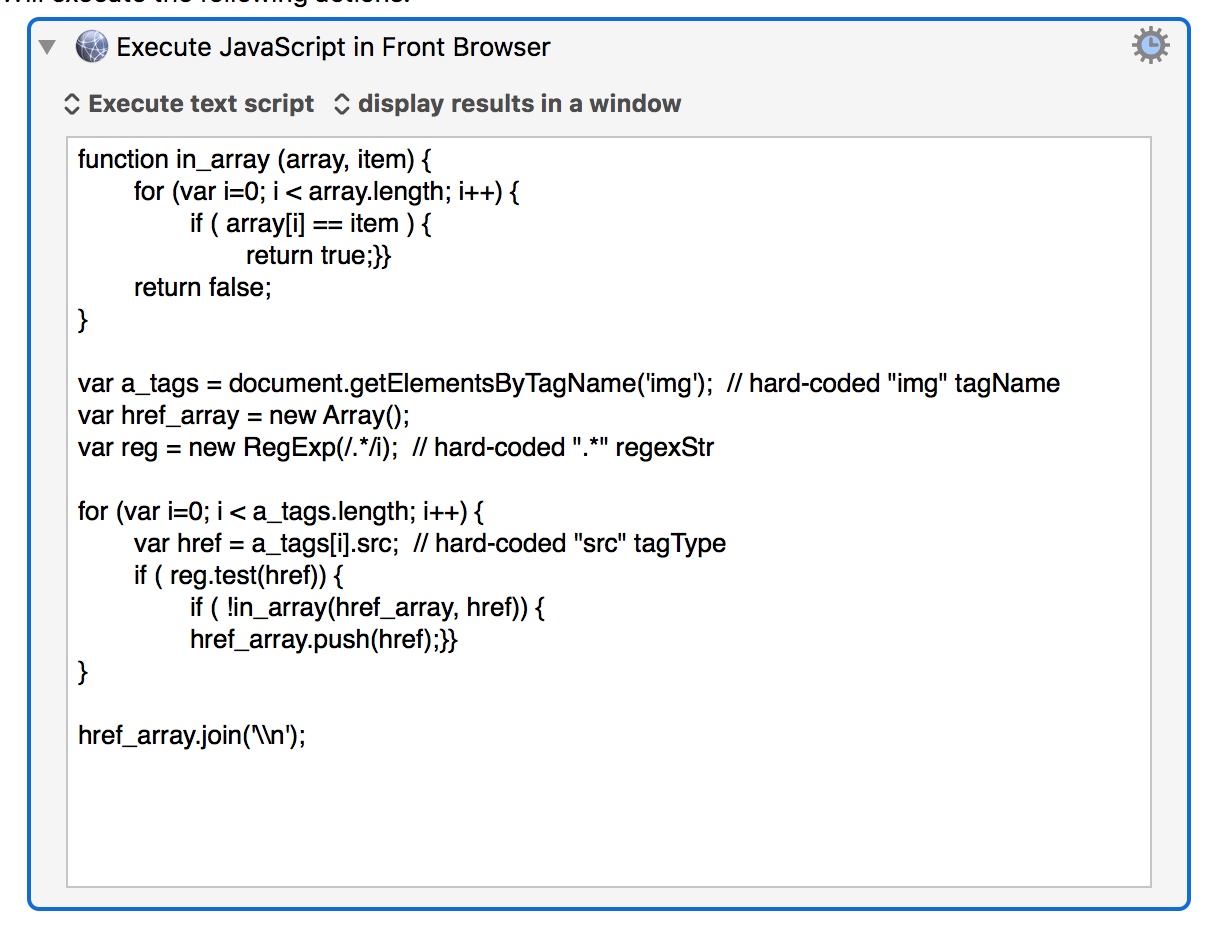
set regexStr to ".*"
set linkList to chromeLinks(regexStr, "img", "src")
set webpageTitle to getChromePageTitle() of me
set windowBounds to desktopBounds() of me
sendLinksToBBEdit(webpageTitle, linkList, windowBounds)
--------------------------------------------------------
--» HANDLERS
--------------------------------------------------------
on desktopBounds()
tell application "Finder"
set _bnds to bounds of window of desktop
return _bnds
end tell
end desktopBounds
--------------------------------------------------------
on chromeLinks(regexStr, tagName, tagType)
set javascriptCMD to "
(function () {
function in_array (array, item) {
for (var i=0; i < array.length; i++) {
if ( array[i] == item ) {
return true;}}
return false;
}
var a_tags = document.getElementsByTagName('" & tagName & "');
var href_array = new Array();
var reg = new RegExp(/" & regexStr & "/i);
for (var i=0; i < a_tags.length; i++) {
var href = a_tags[i]." & tagType & ";
if ( reg.test(href)) {
if ( !in_array(href_array, href)) {
href_array.push(href);}}
}
return href_array.join('\\n');
})();
"
try
tell application "Google Chrome"
if front window exists then
tell active tab of front window
set linkList to execute javascript javascriptCMD
if linkList = missing value then set linkList to {}
end tell
end if
end tell
on error
set linkList to {}
end try
return linkList
end chromeLinks
--------------------------------------------------------
on getChromePageTitle()
tell application "Google Chrome"
tell active tab of front window
set webpageTitle to title
return webpageTitle
end tell
end tell
end getChromePageTitle
--------------------------------------------------------
on sendLinksToBBEdit(webpageTitle, linkList, windowBounds)
tell application "BBEdit"
activate
make new text document with properties ¬
{contents:linkList, source language:"TEXT", name:¬
("Embedded Image Links ⇢ " & webpageTitle), bounds:windowBounds, soft wrap text:false}
tell front text window to select insertion point before character 1
end tell
end sendLinksToBBEdit
--------------------------------------------------------
Just in case anybody else tries to use your code, a couple of notes. I didn't get it to work exactly in your form ...
I didn't have BBEdit installed, so that needed to happen.
Even with BBEdit installed, the BBEdit AppleScript handler threw an error (maybe because of a newer version of BBEdit than you are using.
After simplifying the code to just avoid the BBEdit portion, I was still having problems.
I'm guessing I probably just screwed something up in adjusting your AppleScript, but ultimately, I had success with just putting the JavaScript portion in a Keyboard Maestro action. Not as elegant or flexible as your solution, but it's working ...
In my opinion all Mac users should have BBEdit installed. The full-featured demo period is 30 days – after that it reverts to Lite mode (free), and it's still a killer text editor and highly scriptable.
That's weird. What was the error?
Did you give Keyboard Maestro permission to control BBEdit?
Did you try running the script from Apple's Script Editor.app or from Script Debugger?
You do have this setting turned on – yes?
Hmm... I'd have to test the macro to find out what's up with that.
Please remind me what version of macOS you're using.
And what web browser.
I've tested on macOS 10.12.6 Sierra with BBEdit 12.6.7 (412120) – and on macOS 10.14.6 Mojave with BBEdit 13.5.5 (415093) the latest version.
In any case – I'm glad you were able to get it working.
Thanks for your follow-up and sorry for the delayed reply. In trying to get you some debugging info, I reran your original AppleScript (in a Keyboard Maestro "Execute AppleScript" action), but this time it worked perfectly and showed all the image links in BBEdit. Have no clue what the problem was before, but it resolved itself
I am brand new to Keyboard Maestro, and want to do something very similar. The first issue I am running into is that I want to do this on quite a few successive pages (or it should be able to save PDFs from concatenative links into subfolders, which is probably too much to ask), and so having the URL in the macro itself is not ideal; I would expect to be able to invoke the macro and have it operate on the current page. Is there a way to do this?
Secondly, when I run it, the first thing that happens is “Open URL failed.” This happens even when I leave the original URL. I don’t have Chrome, but this happens whether I change the browser in the macro to either Brave or Safari.