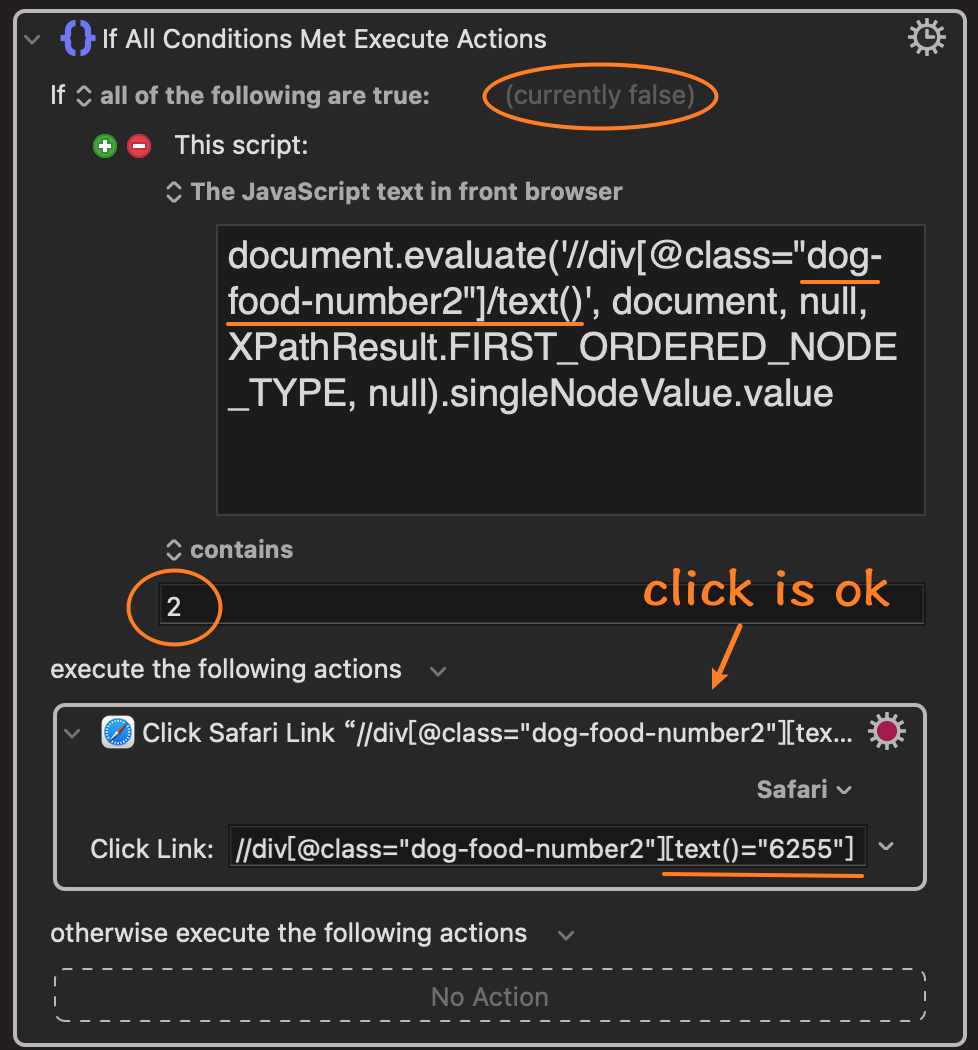
The strange thing is that the search for xpath fails, but the click is successful. It may be that there is a problem with the code for searching for xpath, but I don't know where the problem is. Please help, thanks!
Its hard to say, but the two XPaths are not the same (the ending of one is /text() while the other ends in `[text()="6255"], so that could be related to the issue.
I'm sorry and let me make it clear.
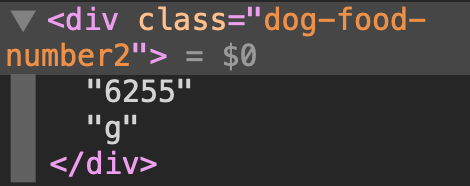
This xpath //div[@class="dog-food-number2"]/text() get the text part "6255" and "g". Obviously It contains 2.
I use this xpath //div[@class="dog-food-number2"][text()="6255"] clicked successfully to prove the first xpath is correct but why the if condition is false?
Until now I haven’t seen any example about The Javascript text in front browser except the one in your picture above. Can you give us a concrete and successful example? Great thanks.
Supplement another picture.
The first xpath is still false and the second is clicked successfully even though they are the same. @JMichaelTX Could you please have a look at this? 
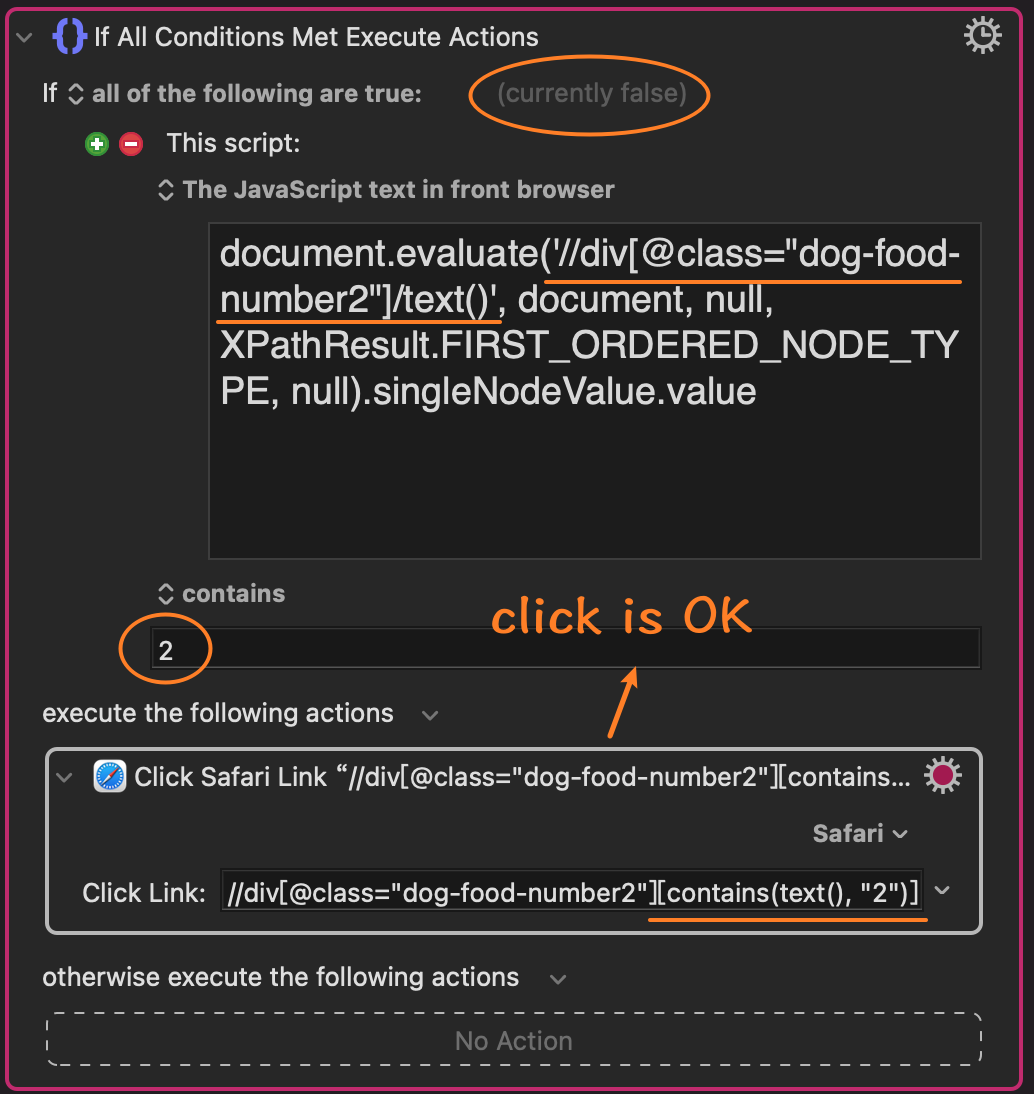
If the page is accessible, and you upload your failing action, then I'll take a look. Otherwise it is very hard to suggest why it might be different.
Since this is really a new topic, I've moved it to a new topic.
Sorry the page needed to be log in. I'll use another page for testing.

Just inspect the page in the web browser and try the code out. Your document.evaluate code errors.
SyntaxError: The string did not match the expected pattern.
Until your code works in the web browser, it isn't going to work in Keyboard Maestro.
If you use the same XPath as you use in the Click action, it works in the browser.
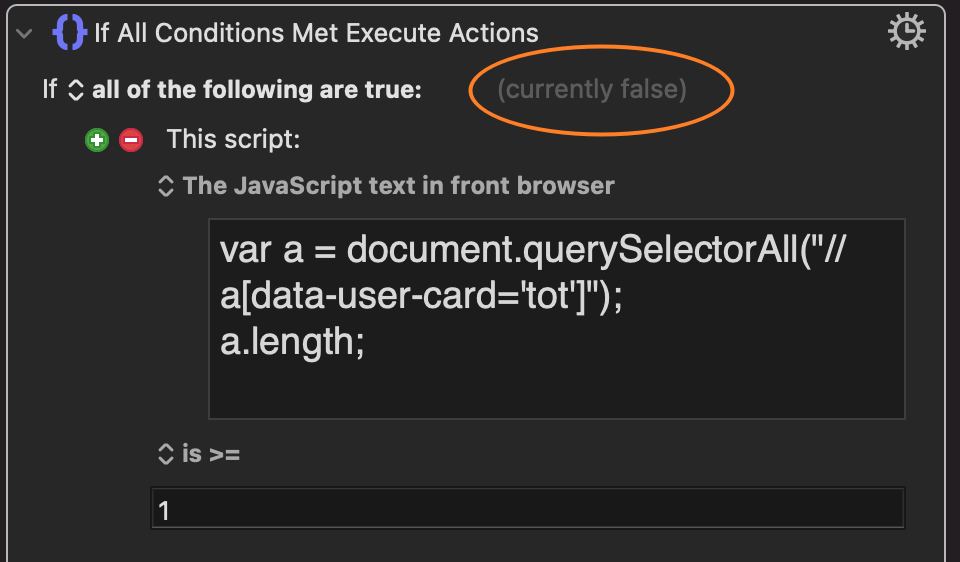
I tried the following and no one contains tot in KM. The first was copied in Safari inspector. I think the problem is not the xpath part but the rest part of codes. I don't know where it is.
document.evaluate('//*[@id="post_1"]/div/div[2]/div[1]/div[1]/span/a', document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue.value
document.evaluate('//*[@id="post_1"]/div/div[2]/div[1]/div[1]/span/a/text()', document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue.value
document.evaluate('//a', document, null, XPathResult.FIRST_ORDERED_NODE_TYPE, null).singleNodeValue.value
OK, I'm afraid this is a JavaScript/DOM issue, and I am not an expert in such things, so someone else will have to help you figure out how to reference that element with JavaScript.
Sorry to take your time. Thanks a lot! 
1 Like
Its no problem - someone else may be able to help you, its just not an area I know enough about.
You need to get the JavaScript working in the browser console, and then you should be good to go.
I see. I'm waiting if someone can help. 
Xpath is a powerful tool but a little complicated.
That is why I rarely use it. I prefer the JavaScript querySelector.
If you will post the following I will try to help:
- Page URL, or zip file of entire HTML source code
- Screenshot of the link yo want to click on.
Thanks for your reply! 
It's a pity that css removes the contains function. Document.querySelectorAll can determine whether an element exists by judging the number of this element, but that's all, it is impossible to determine whether an element containing a certain text exists. Document.querySelector can only determine whether the first element of the same kind of element exists.
Take our topic page as an example, I can only use css to judge that this page contains a user card, but I can’t judge that it contains mine 'tot'.
Xpath can accurately locate through text, but so far I've not found the correct code implemented in KM.
test.kmmacros (3.6 KB)
Another strange thing happened although the css test is correct in Chrome:
I have a simple JavaScript that does that:
//--- Use this Javascript to Click on a <div> that CONTAINS specific text ---
// (test is case INSENSITIVE)
divCollect = document.querySelectorAll('div.someClass a.withOrWithoutClass');
Array.from(divCollect).filter(e => /whatever text you want/i.test(e.innerText))[0].click()
It's cool! I tested it successfully. But there are still some problems.
First, which one should I choose? returns sucess seems invalid and it's always true.

Second, it has the same effect as Click Front Browser Link with Xpath + If All Conditions Met Execute Actions with The last action result is OK. But it will automatically trigger a click when you open the page and cause the page to jump, and the Xpath way will only recognize and click it when the macro is running.