For the macro I'm trying to build, there's no way around it: I need KM to find a Found Image on the screen, and the found image occurs multiple places on the screen. I don't mind which one it clicks. The one closest to the top left makes sense, but functionally, any will work.
I first tried to do this using a Move or Click Mouse and set it to "relative to the center of the found image" but that doesn't seem to work. I enabled the Display checkbox (note: Display is not mentioned in the documentation, and should be) and KM does correctly "see" all instances of the button I'm trying to press, but it won't press any of them.
However, I found a workaround: if I use the Find Image On Screen action, save its location to a variable ("buttonloc"), then use the Move or Click Mouse function to click at buttonloc.X + 50 and buttonloc.Y + 10 (with absolute positioning), then it does work -- it clicks on the first top/left instance of the button it finds.
So I guess I'm OK. I'm just posting so that I understand the logic that KM uses. Why didn't it work when I simply used Move or Click Mouse the first time? Seems like an inconsistency.
Also, it would be great if some of this was better explained in the documentation. Display is never mentioned, and I've figured out how to use variables and their derivatives (.X, .Y, etc.) only by trial and error. If it's explained in the documentation, I'd love to know where that is so I can learn about it properly instead of feeling like I'm groping in the dark.
In the Move or Click Mouse action, there is no option to allow finding a non-unique match. The found image must be unique for Keyboard Maestro to know where to click.
In the Find Image on Screen action, there is an option to find either any matching image or a unique image (and return nothing if none can be found).
To click at the center you can use buttonloc.MidX,buttonloc.MidY (because Find Image returns the rectangle of the match (plus the fuzz)).
Any reason you can’t use Move or Click Mouse to find a non-unique match? (Again – seems like an oversight that that functionality is available in the Find Image on Screen action but not Move or Click Mouse.)
Also – speaking as someone who is crossing the threshold from newbie to intermediate KM user – where do I learn about things like MidX and MidY and so on? I feel like I discover these things in bits and pieces via the forum but it’s not at all obvious from the UI. (I’m really giving you constructive criticism for the documentation. :)) I’m one who thinks the perfect programs are the ones which you don’t have to read the manual for. Obviously, KM is incredibly complicated and powerful and that might not be 100% realistic, but still, I’m giving you feedback in the hopes that it’ll help other users figure things out faster!
And a reminder there too, most of the menus listing actions/triggers/tokens/etc, if you hold the option key down will take you to the help on the item on the wiki.
Thanks very much. I had been using the cog wheel to click on Help for various things, but occasionally found omissions on the exact subject I was wondering about (variables, why Move or Click Mouse to a Found Image doesn’t work when there are multiple matches), etc. which is what led me to post here.
Thanks for the links (above) – I hadn’t noticed the parts of the documentation dealing with variables of found images before right now. Sorry if I missed it earlier.
I'm running the outdated KM 6.4.8 on one of my old machines. I was never capable of achieving stable results with its Find Image on Screen action, which - if I'm getting it right - was the first iteration in its history. Therefore, its purpose and role in the KM 6 environment are unclear, so it bears some questions.
What was the scope of its application as of KM 6? Was it other KM actions, opened windows, or displays? Where is "On screen"? As I already mentioned, this concerns KM 6.4.8. This revision lacks look-out functionality narrowing down the target zone to a screen area or app windows specifically.
Abiding by the instructions in the corresponding Wiki article, I dragged a PNG image to the image well, copying it to the Desktop in advance. Clicking on try followed by playing with the action's settings (changing the fuzzing level and selecting the offered checkboxes) brought me nowhere.
I downloaded the example macro containing the action from its Wiki page and ran it successfully. The only difference I was able to discern was that of the image size. I copied the picture to my macro, and it revived it. Below is the image I was experimenting with. Are there limitations on file type, dimensions, etc.?
Even with it finally kicking into an operational mode, the practicality still left me wondering. All the display option made was to highlight it, and its variant in the Click and Move action yielded a click on the image in the well. Is that it? What for? How's that useful?
The most common use case is being able to interact with UI elements that can only be interacted with visually.
An App might have a "button" that has an image on it and you want to press this button as part of your Macro. Or you might want to pause your Macro until a certain visual UI element appears. Usually, "found image" is the last resort if you can't get the Macro to work any other way. Having said that, it is still a great tool to have as an option.
For example, an app might have a palette like the below and give you no other option than to click on the icons (i.e. no equivalent menu options or hotkeys).
In which case you could take a screenshot of the icon you want Keyboard Maestro to click on.
That is because the image in the Action you downloaded is nowhere else on your screen, but only in the image well. In real use you would have taken a screenshot of an actual UI element that you wanted to work with and the Keyboard Maestro editor wouldn't be showing when you ran the Macro.
You would probably have more success if you took a screenshot of a small unique part of a large image like that (otherwise Keyboard Maestro would be trying to find a match for an enormously complex arrangement of pixels).
Coming back to the purpose of the feature - it is to detect unique arrangements of pixels on a part of your screen and act on that result to do something in your Macro.
I came across a problem involving websites whose page doesn’t load all in one go, but requires you to scroll down before another part of the page loads. The specific problem I was having was when trying to print to PDF many such web pages and I found that the complete page would print only once I had scrolled to the very bottom in order to ensure the whole page had been loaded.
The solution, of course, was to get KM to repeatedly scroll the web page until the bottom was reached. But then, how could KM know it had reached the bottom so it could stop scrolling and then automatically initiate the print to PDF process? Well, the websites I was dealing with had icons at the very bottom of their pages which KM could “look for” and when found stop scrolling.
In summary, the logic of the macro was this:
Repeat {
Scroll web page by one screen height
Look for bottom-of-page-icon
If image found finish Repeat otherwise continue Repeat
}
Perform print to PDF process
In this case there was no requirement to click the found image or interact with it in any way - its presence was used solely to control the flow of the macro. BTW in keeping this example simple I haven’t explained how I dealt with multiple websites with varied bottom-of-page markers nor the error handling needed for it to work reliably. But I hope you get the idea.
I use found images less often these days since I’ve become more familiar with AppleScript and Javascript but there are certain situations where they are indispensable such as in the example the above.
Not sure how the would help. Most people who can't understand "Find Image on Screen" when they are looking at images on a screen will really struggle with "graphic elements" and "viewport".
Action names have to be fairly broad descriptors, so that their (often many) options are also covered.
People who can afford to understand the meaning of variables, semaphores, and control flows by using automation tools involving scriptwriting that requires knowledge of the basic concepts of programming and working out solutions revolving around honed decision-making skills won't have problems with a viewport. Either way, one more entry in the KM documentation would eliminate any uncertainty.
"in the viewport" could be omitted. I stressed the first part but the viewport is what it's all about actually.
Why do you want to omit "in the viewport" if the viewport is what it's all about?
Putting "viewport" front-and-centre in the documentation makes the documentation worse because you'd then have to explain that "A viewport can be all screens, a single screen, a window, or an area". Since those are all listed in the action itself, any reference to a generic viewport is both redundant and confusing to a beginner. And anyone with basic knowledge of graphical programming will know that they are viewports without being told.
Were you trying to catch me in a word? You ignored the 1st paragraph of my response in which I reflected on the learning experience. Since I don't like going over again, I leave it for you to re-read.
It's all about the viewport, but you may or may not use the word. You may use other 1000 substitutes for it, but we're not talking of a programming theory. We're talking about the everyday use of an application.
When you bring up the beginner, I was that beginner who had never used this action, and I have basic programming experience. If it had a name specifying its actual function and requirements that I learned in this discussion, I'd use it more often or at least have a clear vision.
I wasn't aware that the image, in fact, is a small piece of graphics and that the full-fledged image files that usually take up a large amount of space data-wise aren't suitable because the action scans for identic small graphic objects in an application's visible area which is another term for "a viewport". It wasn't evident that "finding an image on a screen" is not synonymous with locating a file in the filesystem.
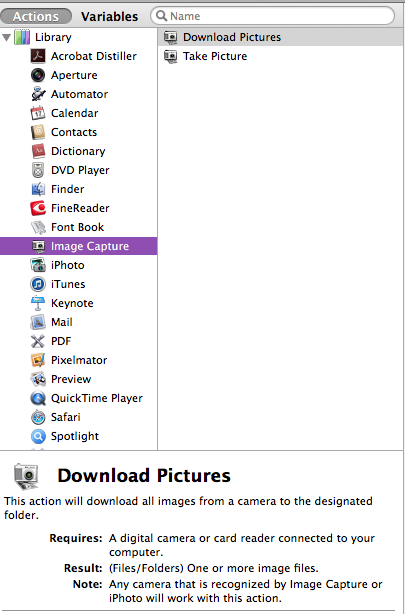
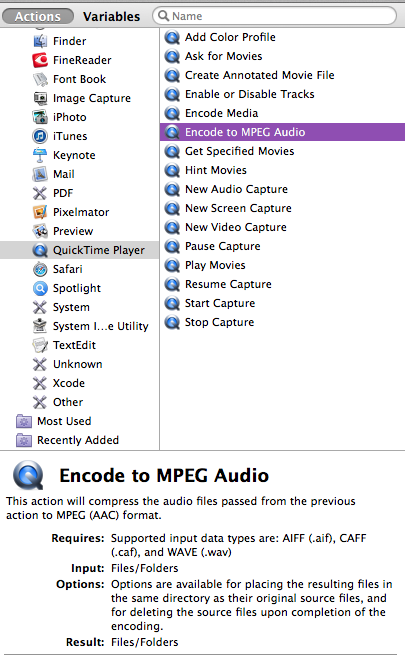
On top of that, the major drawback is that KM actions lack a description, a stark contrast to Automator actions, each of which briefs a user on its purpose, input, and output of the data it accepts.
To make up for this fault, I don't think adding a few lines of an explanatory message to KM Wiki would be unattainable. Call a spade a spade.
Not at all -- I was confused as to whether you wanted to omit "in the viewport" or actually meant omit "find a graphic element". It seems to be the latter, which is good because the action doesn't look for a graphic element -- it looks for an image.
Its name is "Find Image on Screen". Its function is to "find an image" and it requires that image to be "on screen". That's enough for most people to understand its basic function, which is expanded upon on the action's Wiki page.
No -- by default it does not do this. And while 5 of the 9 options do allow you to search for an image in one viewport of the frontmost application, naming it for that specific use would be misleading.
Most KM actions are adequately described by their name -- at least in their generality. But I agree that it would be nice to have a brief synopsis of an action available in the Editor, in the way that Automator does it. (Although most of Automator's descriptions are similarly redundant -- does anyone really need to be told that the "Connect to Servers" action "connects the computer to the specified servers on the network", for example?).
Any details are better than no details. In your cited example, the action's title is generic. and the description contained clues that the servers should be specified by a user.
More examples follow:
In the former case, we have a description of prerequisites for the action to work and what results to expect. In the latter case, we are told what media types the input accepts and how it may be manipulated further should such a need arise.
You cherry-picked an instance that's not representational, but I'm glad you acknowledged the problem.
Which is a graphical object. Any heavily downscaled graphical entity (which is the type that the action works with best) boils down to a combination of paths characterized as graphical objects if we're not debating the usage of euphemisms.
What is a "screen"? Is it a window, static text, or scrollable area? Is it overlays such as one with the "Start Recording" button appearing when one is about to start a QuickTime screen recording (which KM fails to digest, BTW)?
What is "on screen"? What is to "find on screen"?
There are no answers to any of these questions on the Wiki page. Are you implying I'm dumb or what?
What does it do by default? Can you bring an example of what it does with images that aren't graphical objects and where the term "viewport" isn't applicable?
What image types are acceptable for this action? No information on that at all.