Fair warning, I'm a relative novice with KM, but trying to learn. I copied the Macro from this thread as a starting point.
My goal is to apply a series of PDF tasks across about 700 PDFs using PDFPenPro, including functions that are not designed for batch runs. The PDFs are a mix of scanned documents and native PDFs. I want to deskew, update OCR (removing and reapplying the OCR if it exists), and then compress the PDFs as they are currently using about 80GB of storage (some are massive due to resolution of the scans).
My intended workflow is to have Hazel monitor the folder of unprocessed PDFs, then call the KM macro through a shell script on each PDF, then move it to a different folder for the processed PDFs.
Two issues I haven't been able to figure out in the macro (or at least only two so far ):
How to get and apply the original file name to the processed PDF.
When PDFPenPro optimizes a PDF, it creates a duplicate of the original PDF named "Untitled.pdf". I can get the save dialog to the correct path for the new PDF, but I haven't figured out how to retrieve the original PDFs name to apply to the new PDF. I assume I can get it from one of the variables, store it, and then paste it in as the name in the save dialog, but I haven't figure out how to do that.
How to find a condition to "Pause Until" when removing the OCR layer on the PDF
PDFPen has a menu command to remove an OCR layer from the document. When it finishes there it can play a sound. The only change in the window, is that the displayed title now has —Edited as show in this screenshot.
However, that doesn't change the window title in the Window menu. I see there is a variable to get the frontwindowname, but I wasn't sure if that would see it either and haven't figured out how to use it in the macro so far.
Could any of you experienced KM...um...maestros? give me some pointers?
EDIT: Just realized I uploaded a version with actions I was testing (currently disabled) still in the macro. I was trying to figure out how to use the %frontdocumentpath% token, thinking I might be able to get the file name out of it and to the clipboard to help solve problem 1. I also see that my attempt to identify the "edited" in the window title to solve problem 2 is in this draft as well. Finally noticed that my notes on the keystroke actions aren't visible either, so let me break down the macro:
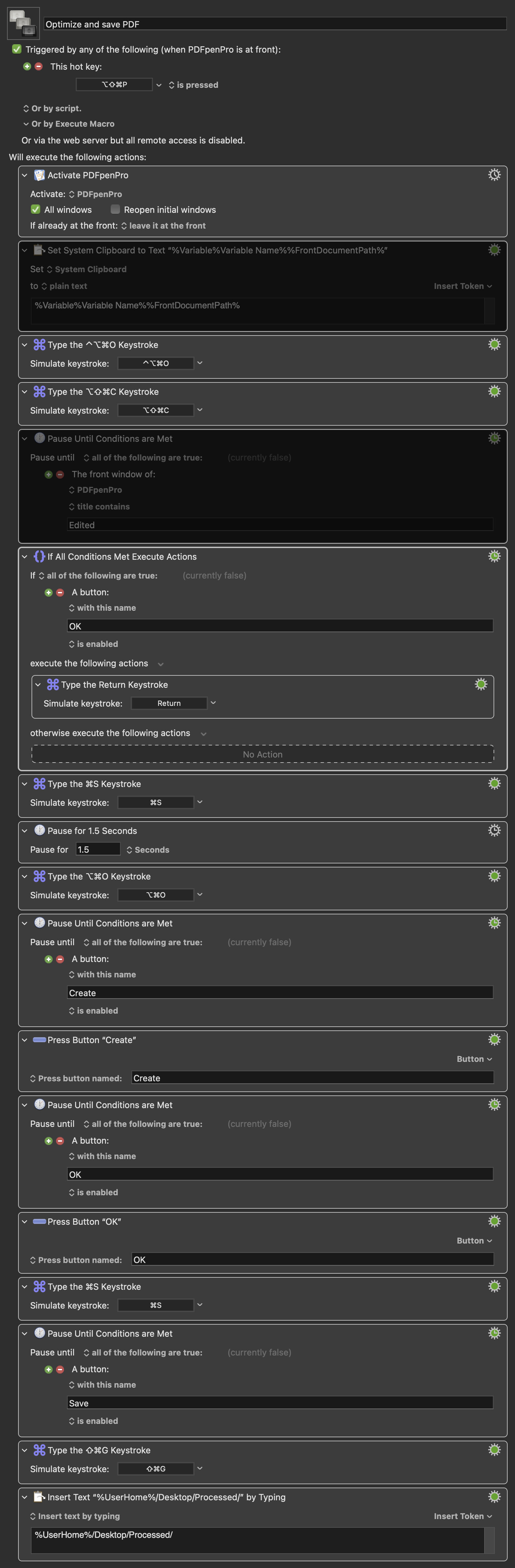
Open PDFPenPro (PPP)
Some method to get the filename of the source document into a variable
Clear the OCR Layer on the document
Run OCR on the document
Apply some pause condition that will will delay the next step until the OCR layer step is finished
If the attempt to OCR generates an error, clear the error and proceed
Save the changes
Brief pause in case it is needed for the save to complete
Custom shortcut to trigger the Optimize menu command
Wait for the create button
Select create button
Wait for okay button
Select okay button
Open the save dialog
Wait for the Save button to be present (waiting for the dialog to open)
Open the "Go To Folder" field in Finder
Enter the destination path for the processed PDF and (once I figure out how) name it the same as the source PDF.
The first part of my response isn't really an answer, (the second part might help a bit) but I've done this sort of thing before once, with the manual for my favourite game, Civ VI. The manual was available online as a PDF. I wanted to import it into macOS Pages so I could edit it. The point to editing was to be able to study it, so I could become a better player. (I'm still no good.) But it was a much bigger job than I expected (even considering the fact that no OCR was involved. EDIT: I just remembered I did use OCR for my work!) I wanted to properly convert every footnote, every header level, every diagram, ... everything perfectly converted to Pages.
I don't want to go through all that work again (10-20 hours at least.) That was just for one manual. And you want to do the same thing with 80GB containing 700 PDFs that - for some documents - require OCR? How many hours of work do you expect this to require?
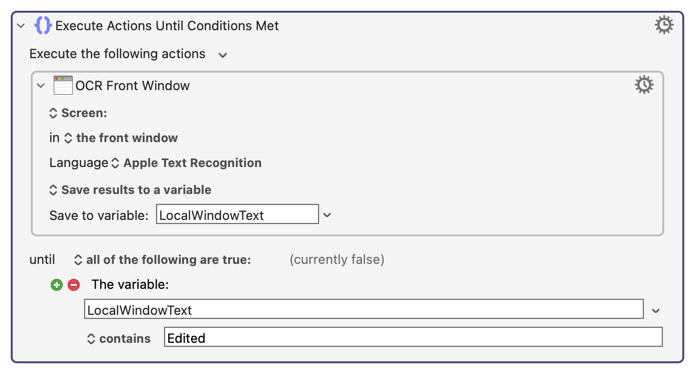
Anyway, I'll give you one specific pointer. In your screenshot I see the characters, " - Edited". Since the word "Edited" appears in that image, it's very easy for Keyboard Maestro to detect that sort of thing. You can simply have your KM macro pause until the word "Edited" appears in the window. It would look something like this:
Just had time to get back to this. Thanks for the suggestion. I didn't think about using OCR to read the title of the Window. That's a good idea.
As for the rest, I don't want to do the same thing you did. I'm not aiming for that level of conversion of perfection. I'm leaving them as PDFs, I just want to compress all the scanned PDFs so that it will take up a fraction of the storage. I don't need to the very high scan resolutions many of them contain. I'm also just trying to get OCR of the general text. It won't be perfect as there are lots of unusual color changes and placement of text for many of them, but most of the text seems to be read by OCR well, which will allow searching them quickly, which is good enough for my purposes.
Looks like there was a second poster who made some suggestions in the notification email, but not seeing their post here. I'll share my macro if I get it all figured out. Still working on setting the original file name when saving he compressed copy.
You can also get a free 7 day trial of Adobe Acrobat Pro which gives more options than the free version above. Perhaps you can get all your compression done during the 7 day trial.
If you still want to use OCR to convert to a word processor format, the end result will most likely look horrid, based on my experience. But if you can do it, I will be immensely happy for you.
That free PDF compressor, when I tried it, gave me 3 levels of compression to choose from which reduced the file size from 30% to 70%. So you might be able to reduce your 80GBs of data to 30 GB.
I appreciate the suggestions. I'm sorry if I've not been clear, but I'm not converting them to word processor formats. I'm not changing them from PDF. I'm only taking scanned images in a PDF, and making them searchable by using OCR on those PDFs. They will be PDFs coming and PDFs going out, just with an OCR layer added and compressed to a smaller file size in the course of my macro.
When PDFPenPro "reads" a document with OCR, it saves the text it reads as an invisible layer over the visible text in the images in the scanned PDF. This invisible layer effectively embeds the text of the document so it can be searched digitally, just like a PDF that was not scanned and created with digital text. The end result is I can search the text from the scanned images in the PDF just as I could search a PDF that doesn't contain scanned documents.
Is that using PDFPenPro's builtin OCR software, or are you trying to use KM's? It's hard to tell when reading your macro because I don't know what those keyboard shortcuts mean. Since I don't have PDFPenPro, I probably can only help with specific questions. Maybe someone else on this forum has your software.
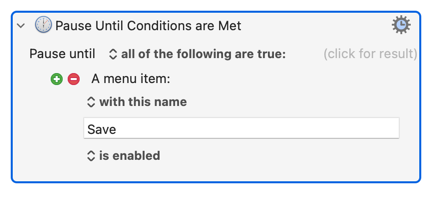
If you are still stuck on this bit (I got a bit lost in what you have and haven't got working) then check the state of PDFPenPro's "File" menu before and after the "Remove OCR layer" step.
The hope is that before step 3 you've made no changes to the document, so the "Save" item won't be available. After layer removal and the document shows "Edited", the "Save" item should be available. So you might be able to:
However, that doesn't jibe with your list of steps, where your pause is until the OCR has finished. If you still need that, does the app display a dialog or progress bar you can leverage? Or maybe disable a menu item until the OCR is complete? I'm guessing that you can't, for example, clear the OCR layer until the OCR has finished...