MACRO: Break List into Groups [Example]
~~~ VER: 1.1 2018-05-12 ~~~
![]() 2018-05-12 15:50 GMT-0500
2018-05-12 15:50 GMT-0500
- Added option to output each Group to a File
DOWNLOAD:
Break List into Groups [Example].kmmacros (23 KB)
Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.
This macro was built in response to this request:
Find and cut lines from list to new list based on name
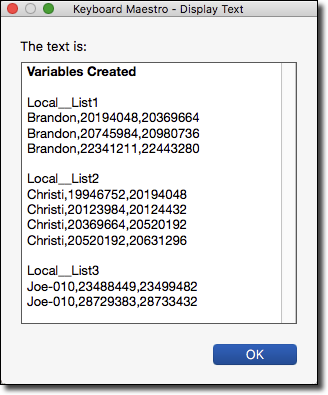
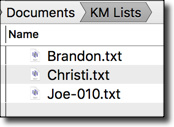
Example Results
ReleaseNotes
Author.@JMichaelTX
PURPOSE:
-
Separate a List into Variables Based on String at Beginning of Line
- Provide option to Output to Files
REQUIRES:
- KM 8.2+
- But it can be written in KM 7.3.1+
- It is KM8 specific just because some of the Actions have changed to make things simpler, but equivalent Actions are available in KM 7.3.1.
.
- macOS 10.11.6 (El Capitan)
- KM 8 Requires Yosemite or later, so this macro will probably run on Yosemite, but I make no guarantees.

NOTICE: This macro/script is just an Example
- It has had very limited testing.
- You need to test further before using in a production environment.
- It does not have extensive error checking/handling.
- It may not be complete. It is provided as an example to show you one approach to solving a problem.
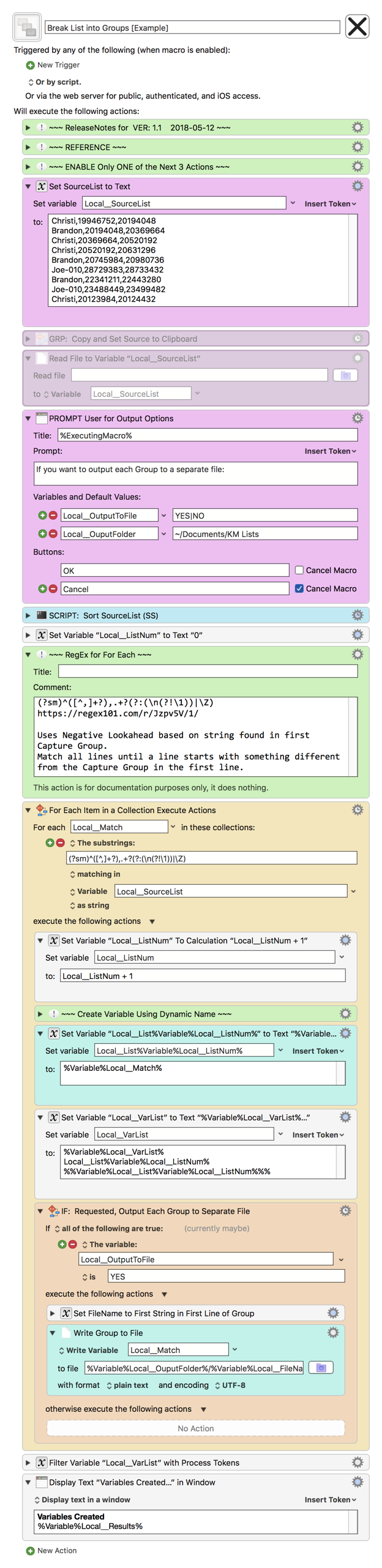
How To Use
- Enable the Action you wish to use to set the Source Data:
- Set Variable (default, and enabled)
- Copy (disabled)
- If you use this, then first select the text to be used as Source
- Read file (disabled)
- Trigger this macro.
- It will then sort the data so that lines that begin with the same string are grouped to together.
- A RegEx is performed to extract the Groups into separate Variables, named as follows:
Local_List<N>- where
<N>is the sequential integer based on Group position in the sorted Source List.
- where
MACRO SETUP
-
Carefully review the Release Notes and the Macro Actions
- Make sure you understand what the Macro will do.
- You are responsible for running the Macro, not me. ??
.
- Assign a Trigger to this maro..
- Move this macro to a Macro Group that is only Active when you need this Macro.
- ENABLE this Macro.
.
-
REVIEW/CHANGE THE FOLLOWING MACRO ACTIONS:
(all shown in the magenta color)- Enable ONE of the first 3 Actions to choose your method of setting the Source Data.
- Be sure to DISABLE the other two Actions.
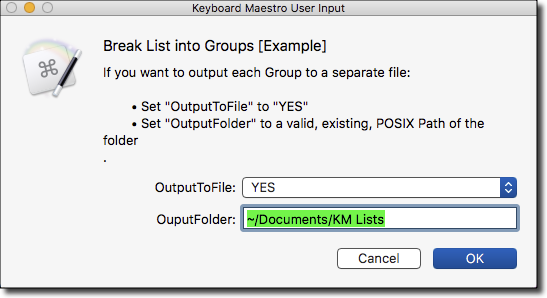
- IF you choose Read File, enter full POSIX path to file
- IF you choose Set SourceList to Text, Enter the list in the Action's text box
- Prompt User for Output Options
- Change defaults as desired
TAGS: @List @Variables @RegEx
USER SETTINGS:
- Any Action in magenta color is designed to be changed by end-user
ACTION COLOR CODES
- To facilitate the reading, customizing, and maintenance of this macro,
key Actions are colored as follows: - GREEN -- Key Comments designed to highlight main sections of macro
- MAGENTA -- Actions designed to be customized by user
- YELLOW -- Primary Actions (usually the main purpose of the macro)
- ORANGE -- Actions that permanently destroy Variables or Clipboards,
OR IF/THEN and PAUSE Actions
USE AT YOUR OWN RISK
- While I have given this limited testing, and to the best of my knowledge will do no harm, I cannot guarantee it.
- If you have any doubts or questions:
- Ask first
- Turn on the KM Debugger from the KM Status Menu, and step through the macro, making sure you understand what it is doing with each Action.
RegEx Details
(?sm)^([^,]+?),.+?(?:(\n(?!\1))|\Z)
For detailed explanation, see:
Uses Negative Lookahead based on string found in first Capture Group.
Match all lines until a line starts with something different from the Capture Group in the first line.