Though I’m not sure that I’m quite clear about a couple of your steps:
Rule 1 seems to remove numbers that start with 7 ('any number that doesn’t start with ‘07’ or ‘44’)
Rule 3 seems to expect numbers that start with 7 to still be there
Rule 2 – I am not sure that I have understood the referent of “the gap”
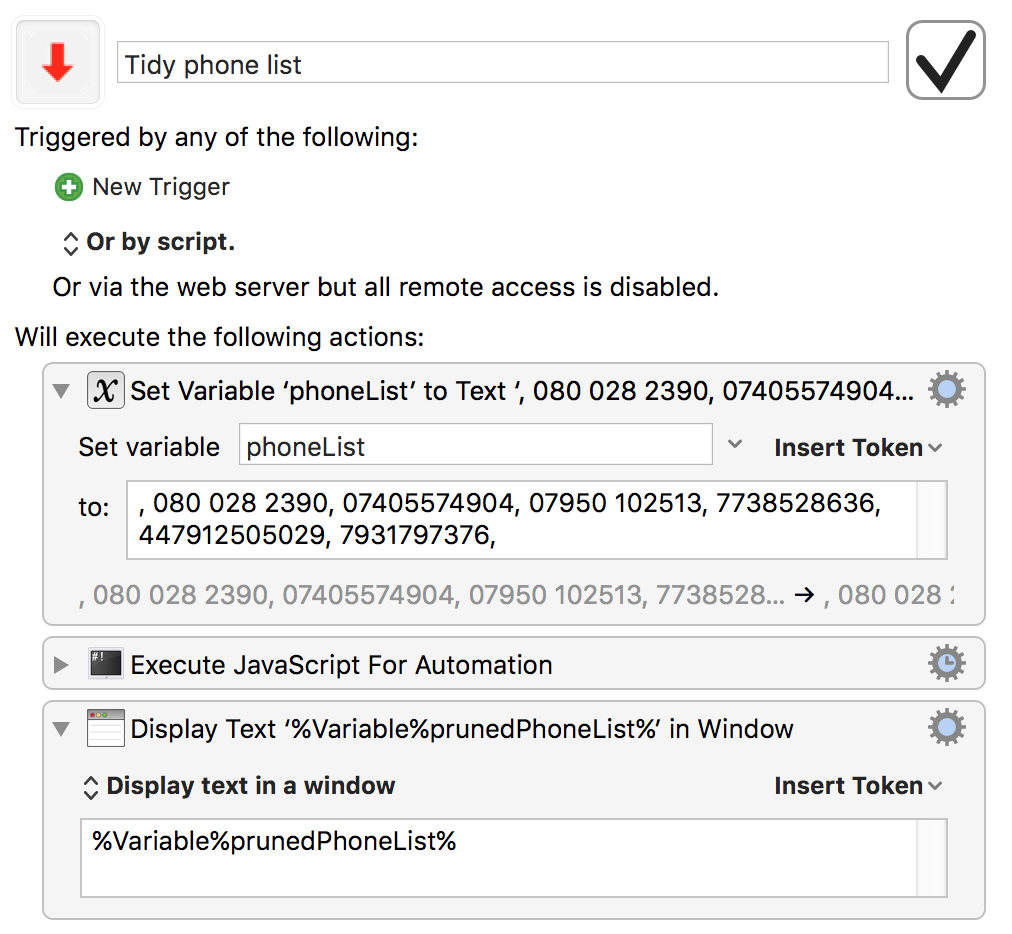
So you might (if you want to leave gaps where deleted numbers were, for example) want to change the filter stage (drops things completely) to a map stage (transforms things), so that you can leave gaps between commas where numbers have been pruned out.
Incidentally, if you are going to use an Execute JavaScript for Automation Action (it’s probably more maestronic to use a string of more specialised KM actions), and you are running Sierra, you can write these maps and filters a little more briefly:
(() => {
'use strict';
// ES6 version (Sierra)
return Application('Keyboard Maestro Engine')
.getvariable('phoneList')
.split(', ')
// Dropping space within numbers
.map(x => x.replace(/\s+/, ''))
// Prefixing leading any leading 7 with a 0
.map(x => (x.charAt(0) === '7' ? '0' : '') + x)
// Dropping numbers that are not UK or UK mobile
.filter(x => {
let strStart = x.substr(0, 2);
return strStart === '07' || strStart === '44';
})
.join(', ');
})();
I'm sure someone can put that together quite quickly with a For Each action – I'm not sure what best practice is on script-free splitting by delimiter.
As an interim fall-back, here is the script action version:
As a footnote reflection on the general issue of broader accessibility, I wonder if this kind of thing is within reach without the use of mutation and regexes ?
In a script version, I guess one could always drop the /\s+/ and just replace all spaces with ‘’, but I wonder if there are any entirely non-regex routes through the other KM primitives ?
Scripting is clearly not something that all users will want to fiddle with - I wonder if regexes occupy a similar position ? (Not that I would want to get into Jamie Zawinski territory )
On the potential complexities of variable names which refer to mutating contents, I thought some of the state-transition images here: https://www3.hhu.de/stups/prob/index.php/State_space_visualization_examples
concretised rather vividly that feeling of oh what a tangled web of state, when first we practise to mutate …
I agree that to ensure the widest possible understanding of a macro it should avoid scripting and regex (although once you learn either of those they become a tool of choice since they are often faster and shorter).
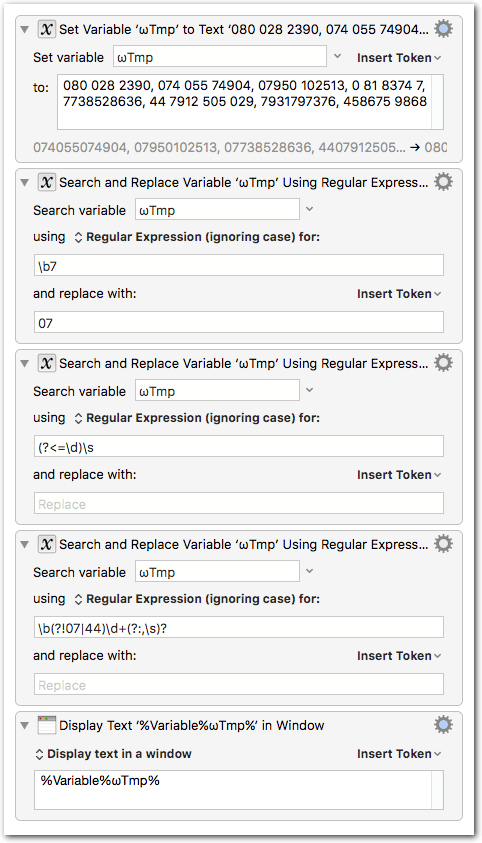
In this case, what you do to avoid the regex is to remove the edge cases - specifically the start and the end of the string. So you apply something like this:
@demirtas1, as a long-time programmer/scripter, but relatively new (about 1 yr) to Regular Expressions (RegEx), I can share that the benefits of RegEx, working with KM, are huge. If I were going to suggest scripting vs RegEx to a non-programmer, I'd suggest RegEx.
I suggest RegEx for these reasons:
With just a few hours of study and experimenting, you can become productive on many common use cases
There are hundreds, if not thousands, of RegEx solutions available to you just by a simple Internet search
You can find KM RegEx solutions/discussions by searching the forum for "RegEx" and by searching Topics tagged with "regex".
There are some great tools, like www.regex101.com, to help you build and understand RegEx
Use of a RegEx in several KM Actions make them very powerful:
Search and Replace
Search (and extract data fields)
IF/Then
Switch/Case
and more
RegEx work in many apps, like BBEdit and TextWrangler
Finally, there are a number of KM Forum members who are well versed in RegEx who are often ready to help out.
RegEx may seem like "magic" at first, and can be initially intimidating. But if you have any interest in this, then I'd encourage you to give it a try. A great place to start is:
 )
)