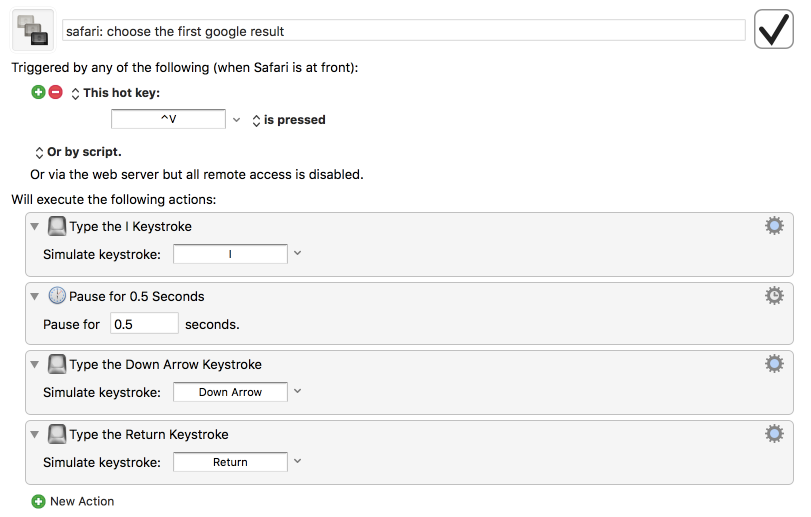
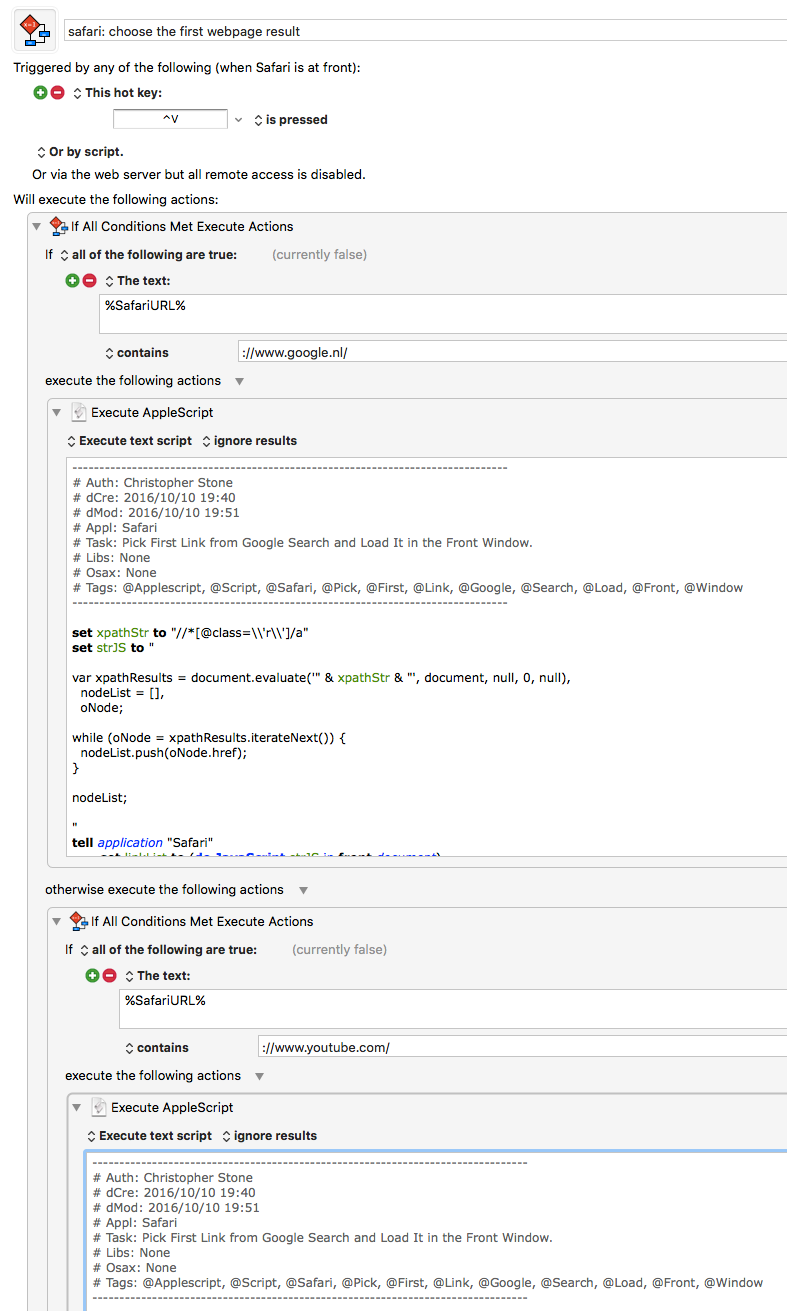
My question is whether it is possible to make this faster somehow as right now it takes about 2 seconds for this action, I would love for that to be instant.
You might be able to use JavaScript to click on the first link, identified by XPath or the first element of the class. Right-click on the first result, and select “Inspect” to view the element, then right-click on the element to copy the XPath.
Stripping the first link and loading it in Safari is easily done. It can be added to the AppleScript or done with Keyboard Maestro functions.
Here's how to do it with AppleScript:
--------------------------------------------------------------------------------
# Auth: Christopher Stone
# dCre: 2016/10/10 19:40
# dMod: 2016/10/10 19:51
# Appl: Safari
# Task: Pick First Link from Google Search and Load It in the Front Window.
# Libs: None
# Osax: None
# Tags: @Applescript, @Script, @Safari, @Pick, @First, @Link, @Google, @Search, @Load, @Front, @Window
--------------------------------------------------------------------------------
set xpathStr to "//*[@class=\\'r\\']/a"
set strJS to "
var xpathResults = document.evaluate('" & xpathStr & "', document, null, 0, null),
nodeList = [],
oNode;
while (oNode = xpathResults.iterateNext()) {
nodeList.push(oNode.href);
}
nodeList;
"
tell application "Safari"
set linkList to (do JavaScript strJS in front document)
if linkList ≠ "" then
set AppleScript's text item delimiters to linefeed
set firstLink to item 1 of linkList
set URL of front document to firstLink
end if
end tell
--------------------------------------------------------------------------------
This forum makes me really envious of knowing all the applescript wizardry. How does even come up with things like this.
Also I am quite curious, in all your scripts you make this form of author, creation date, tags and so on. This makes me wonder, how do you use this after. Do you file these scripts somewhere and index them or what?
Thank you for this wonderful solution. I actually use it quite often now, I hope to extend it to few other sites that give results from search queries like youtube or reddit :
I will try to figure out how to make it work for those websites too and ask you for help if I get stuck if you don’t mind.
I had trouble using XPath, but found a simple search on element class worked fine.
Try this:
##Macro Library [SEARCH] Click on First Link of Search Results [Example]
####DOWNLOAD:
<a class="attachment" href="/uploads/default/original/2X/c/cc4a4f1d80fa4a3222f066ae43ce120027f58998.kmmacros">[SEARCH] Click on First Link of Search Results [Example].kmmacros</a> (2.7 KB)
---
###ReleaseNotes
Do a Google Search in Chrome, then trigger this macro.
Technically the `click()` method of the HTML `anchor` element did not work, for some unknown reason.
So I had to get the target `href` from the element and open it in a new tab/window.
Also, trying to use the `window.open()` method caused my popup blocker to kick in.
So, I just returned the URL, and used KM to open a new Chrome Tab.
---
<img src="/uploads/default/original/2X/2/29337ee5918930c09a81246c2befc3f8eb5acb1c.png" width="680" height="757">
---
###Script
```javascript
//debugger;
(function run () {
'use strict';
var divTopClass = "srg"
var divClassList = document.getElementsByClassName(divTopClass);
if (divClassList) {
var firstLink = divClassList[0].getElementsByTagName("a")
var urlStr = firstLink[0].getAttribute("data-href");
return urlStr;
}
else {
alert('Class NOT Found:\n' + divTopClass);
}
})();
```
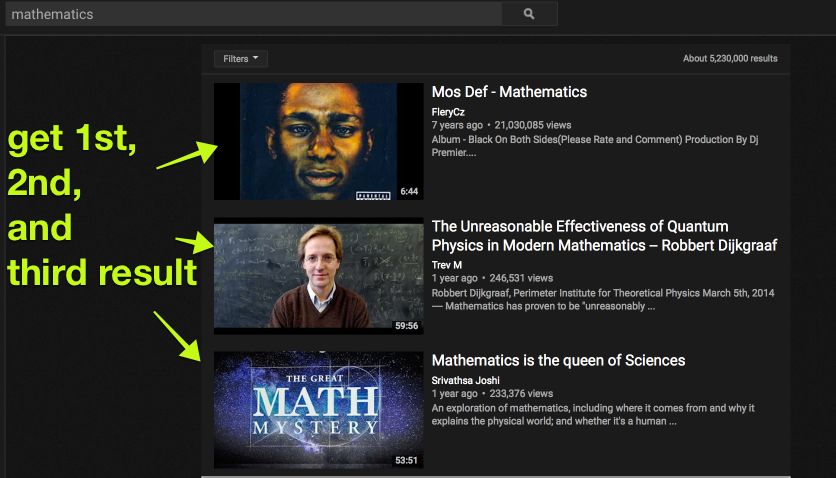
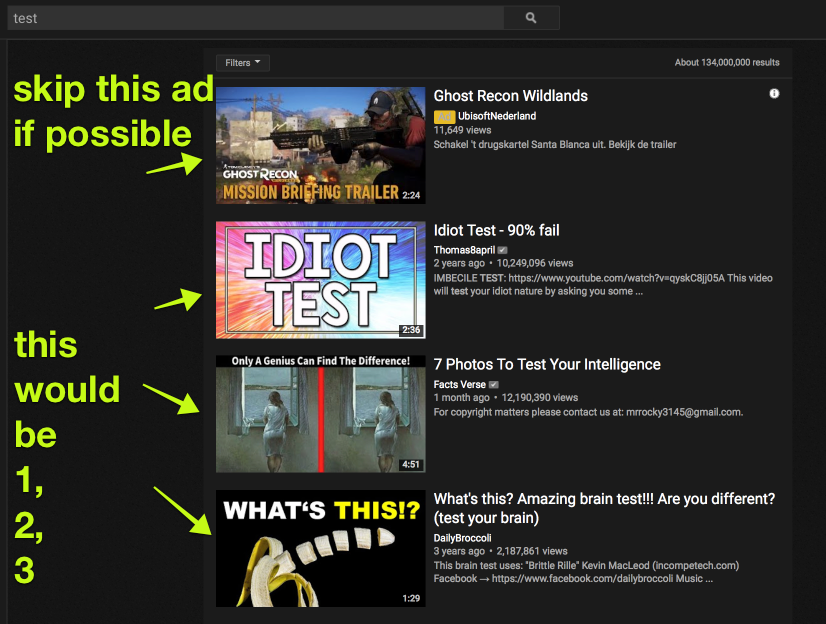
I am trying to modify your script that fetches the urls of first, second, third url from google to also apply for youtube, github and reddit. Starting from youtube but I really can't decipher what is going on in this script to produce the results it produces. I have this macro right now
I hope if you can provide a solution to this or some guidance I can try and understand more of how this script operates to extend it to GitHub, Reddit and perhaps other services with search functionality.
I don’t understand XPath well enough yet to get it working on YouTube, et al.
The Google Chrome inspector will let you copy the XPath of elements, but I’m not getting it to work so far.
I’ve had more luck parsing the raw source, but it’s more than I want to fight with right now.
--------------------------------------------------------------------------------
# Auth: Christopher Stone
# dCre: ?
# dMod: 2016/12/09 14:29
# Appl: Safari
# Task: Get the source of the front Safari page.
# Libs: None
# Osax: None
# Tags: @Applescript, @Script, @Safari, @Source, @ccs, @ccstone
--------------------------------------------------------------------------------
SAFARI_SOURCE()
--------------------------------------------------------------------------------
--» HANDLERS
--------------------------------------------------------------------------------
on SAFARI_SOURCE()
tell application "Safari"
tell front document
set pageSource to do JavaScript "document.body.parentNode.outerHTML"
end tell
end tell
return pageSource
end SAFARI_SOURCE
--------------------------------------------------------------------------------
Yes, I understand. Thank you for trying. I tried following @JMichaelTX approach with getting the Xpath but didn’t succeed myself unfortunately.
If you will have some time though, I would really appreciate if you or someone else can get this working. Your google search result macro saves me hours a week for sure.