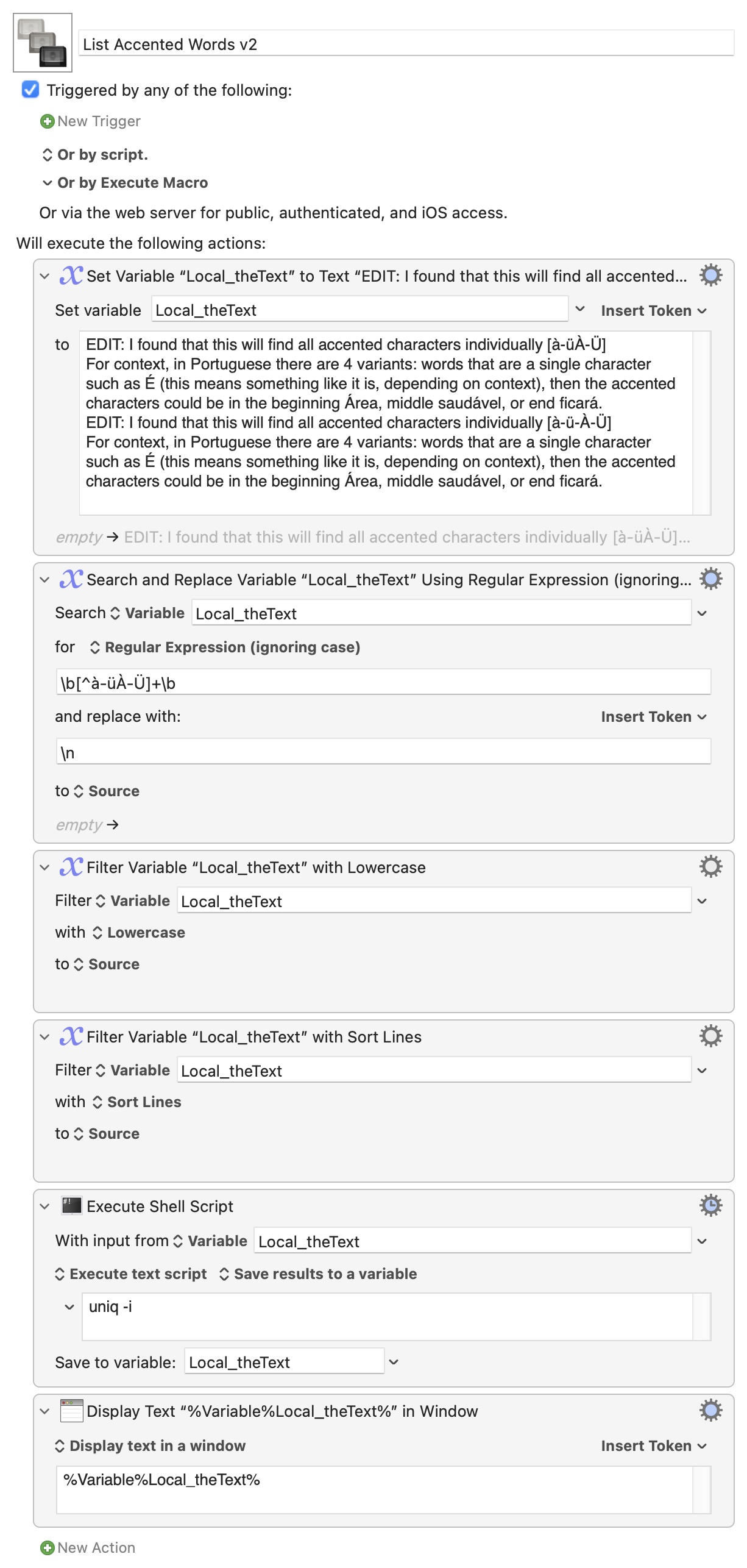
It doesn't seem to work and it seems to break the sorting completely

It's not a big deal. I can always add the Filter ![]()
It doesn't seem to work and it seems to break the sorting completely
It's not a big deal. I can always add the Filter ![]()
Thank you both @Nige_S and @ComplexPoint for your precious contribution ![]()
You saved me so much work and improved my workflow a lot ![]()
I've made one more update in the original post above.
Portuguese sort order should, I think, be better now.
const collator = new Intl.Collator("pt");
const ptComparison = collator.compare;
sort is logical in that it uses the underlying numerical code of the characters for the sort order -- some punctuation marks, then lower case a-z, then upper case A-Z, then similarly with accented and other characters. The Finder does "clever things" to make the sorting case insensitive. If KM's sort filter does that as well -- excellent!
The thing with uniq is that works by comparing each line with the next -- that's why you have to sort your input before using it. But a quick test suggests you can use the KM "Filter" action to do a case- and accent-insensitive sort and then use uniq -i which is smart enough to consider upper- and lower-cased accented characters to be the same.
But it's random as to whether it keeps the upper- or lower-case version of a line. Since you only want lower-case I suggest you put the text through another filter before sorting:
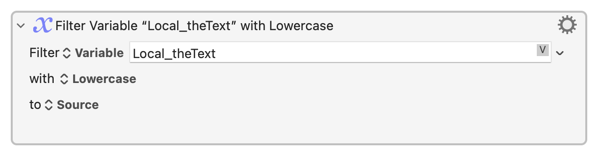
...giving us:
List Accented Words v2.kmmacros (4.9 KB)
Subsequently delegated segmentation into word tokens (in another update above) to Intl.Segmenter.
segmenter = new Intl.Segmenter(
"pt", {granularity: "word"}
);