[sorry about the smiley faces. I don't know why it's doing that]
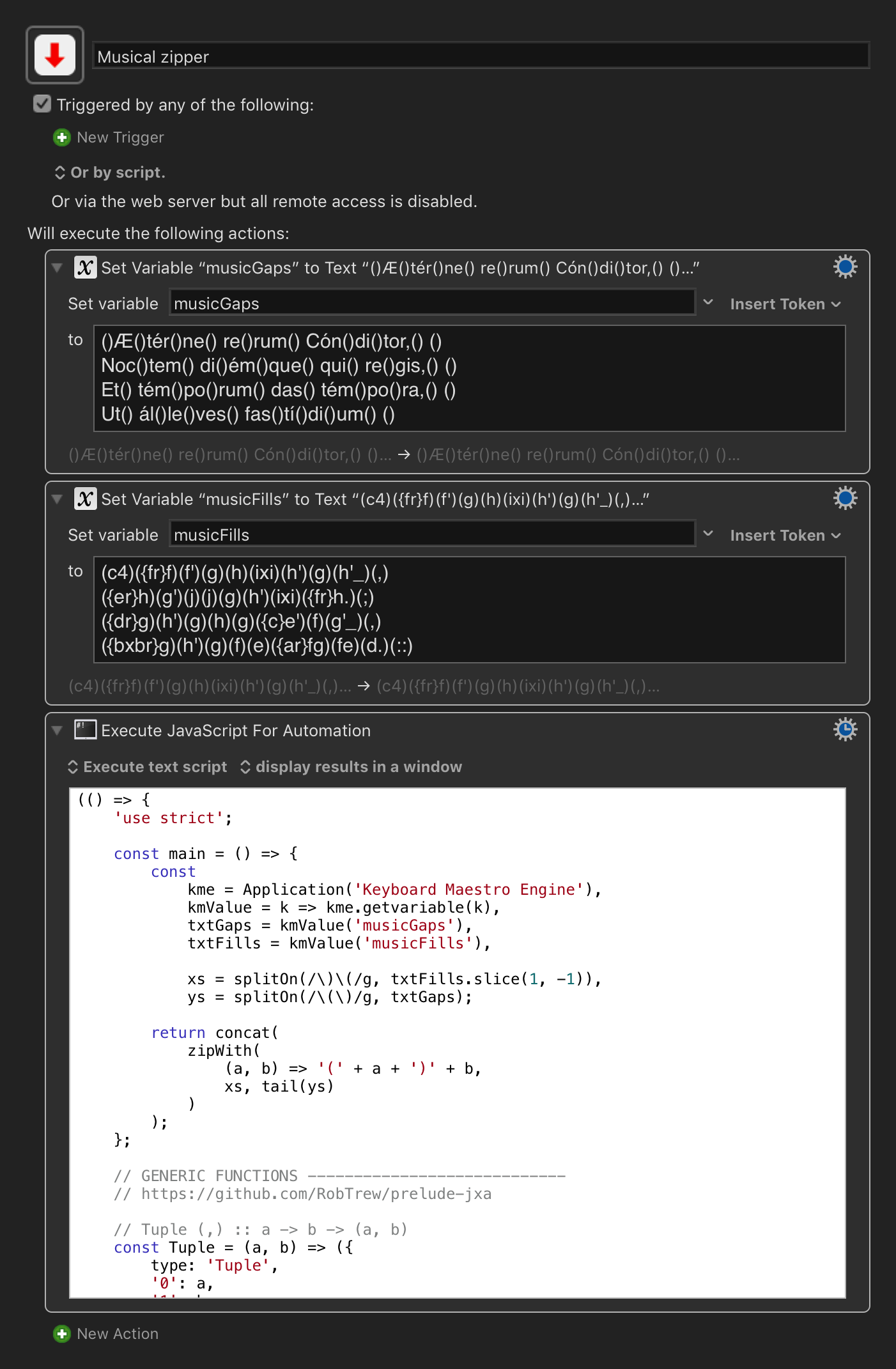
Now, what I want to do is tell KM to put those elements in each set of parentheses of the second file into the first file, in order.
The first word, for example, would come out like this: (c4)Æ({fr}f)tér(f')ne(g)
I tried to write a macro, but I can't figure out why it doesn't work. Here is what it looks like. I think the problem is at the last 'for each' block. I'm calling variables defined outside the 'for each' block' and I think it gets stuck. I don't know. I looked at it for 2 days now.
It appears that why when just paste special text into the Forum Editor.
It is always best to put your source data, and desired output data, into Code Blocks.
Use "text" for the language in this case.
I have edited your post to make these changes.
This ensures that your data is displayed exactly as you have it on your local system.
And will make it much easier for others to understand your data.
@R_B_Jawad, I hope you don't mind that I have revised your topic title to better reflect the question you have asked.
FROM: Macro for sequential text insertion
TO: How Do I Combine Two Sets of Data?
This will greatly help you attract more experienced users to help solve your problem, and will help future readers find your question, and the solution.
ComplexPoint,
Thank you for the help. That was a lot of work, I'm sure.
The macro you posted above works pretty good, but it has some problems.
The first line looks good, but by the second line, things are off. Specifically, ({er}h) should come after Noc. I would try to edit it, but I am not familiar with Java.
Actually, nevermind. The macro I posted above works. It's just, the last step "set clipboard to variable" fails, for whatever reason. I changed it to 'display text in window'. Thanks anyway for your help.
Here is a completed version, if anyone else is interested. It takes two text files as input. It finds the first pair of parentheses in the first file and inserts the content of this into the first pair of parentheses in the second file.
I'm not a programmer, and I don't think it is very efficient. Takes the computer probably 10 sec, which is way better than my old cheap way, which probably took 20 min (I had the computer clicking back and forth), which was way better than doing it manually. I basically just used a bunch of Regex commands and a 'for each' command. The way it works is, it converts each text file into a string of characters. The two strings are each prepended with an identifier (@). Then it finds the first ( ) after @ and stores that. Then it finds the complement after @ in the second file. Then it glues those together. Then it deletes the stuff it just selected in each file, so that now, the second ( ) becomes the first. And just repeats that over and over, adding on the glued segments to what it already has. Finally, some formatting is done, specific to my file to get it back like it was originally.
It also has a check at the beginning, to make sure the number of parentheses agree. Because of elisions in my texts, I had to build a small modification in, which basically removes these extra parentheses, and then puts them back in at the end. gregoriofillnotes.kmmacros (34.7 KB)