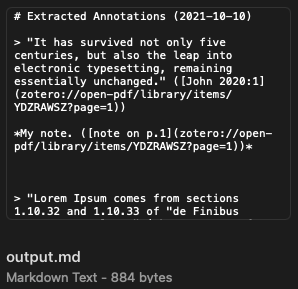
I have a rich text that I copied from somewhere else. The text contains a title (in bold) and some quotes.
They are extracted from a PDF file by Zotero.
I'd like to convert the rich text into markdown.
Zotero has an extension to generate a markdown file, but I'd like to use Keyboard Maestro to do the conversion, if it is possible.
I am attaching the sample PDF file (which is not necessary), the rtf file (which I simply copied from the extracted notes created by Zotero. It is the source. The real source is the clipboard, but I have to paste it into an rtf file to upload), and the output markdown file (which is my desired outcome. I'd also like to put it in the clipboard).
I did more tests. I found out that if I run @ccstone's script after copying from Zotero extracted notes, it says no "rtf" text. But if I copy from Word, Scrivener, or Nisus Writer Pro, the script works as intended.
I pasted the text that I copied from Zotero extracted notes to Nisus Writer Pro, and then copy the text from Nisus Writer Pro, the script works well.
It looks like Zotero's notes are in HTML format, when I copy and paste to Nisus Writer Pro, the text is converted into RTF. Therefore, the text I uploaded here as RTF does not accurately represent the text I copied from Zotero notes (HTML format). This also explains why I had to use «class HTML» over «class RTF».
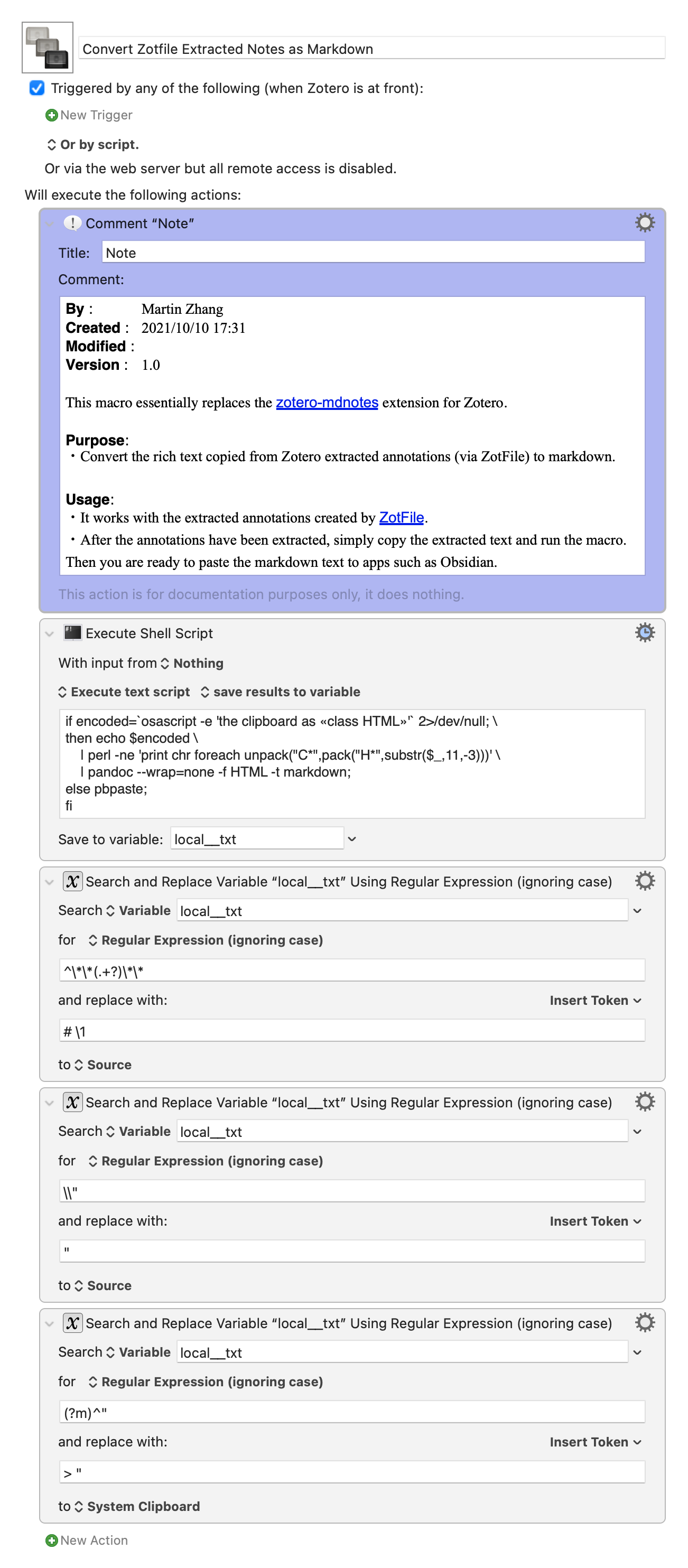
==After copying the extracted notes from Zotero (the content is essentially what shows in the rtf file), execute the KM macro, and it will put the markdown text to my clipboard.==
I don't know if pandoc can do it or not. I have tried something like:
# with input from the clipboard in KM Shell action
iconv -t utf-8 | /usr/local/bin/pandoc -f rtf -t markdown | iconv -f utf-8
Got the code from here to first convert the rich text in the clipboard to html, and then use Pandoc to convert html to markdown.
Code (I believe it could be generally used for any rich text in the clipboard):
if encoded=`osascript -e 'the clipboard as «class HTML»'` 2>/dev/null; \
then echo $encoded \
| perl -ne 'print chr foreach unpack("C*",pack("H*",substr($_,11,-3)))' \
| pandoc --wrap=none -f HTML -t markdown;
else pbpaste;
fi
After the conversion, I added a few other action to make the text in the same format as that generated by the zotero-mdnotes extension.
The benefits are:
No need for the mdnotes extenstion anymore.
The tutorials I have watched all use mdntoes to first create an markdown file, and then copy its content to apps such as Obsidian, and then delete the markdown file.
(() => {
"use strict";
ObjC.import("AppKit");
// main :: IO ()
const main = () =>
either(msg => msg)(md => md)(
clipBoardHtmlLR()
);
// --------------------- GENERIC ---------------------
// Left :: a -> Either a b
const Left = x => ({
type: "Either",
Left: x
});
// Right :: b -> Either a b
const Right = x => ({
type: "Either",
Right: x
});
// either :: (a -> c) -> (b -> c) -> Either a b -> c
const either = fl =>
// Application of the function fl to the
// contents of any Left value in e, or
// the application of fr to its Right value.
fr => e => e.Left ? (
fl(e.Left)
) : fr(e.Right);
// clipBoardHtmlLR = IO () -> Either String HTML
const clipBoardHtmlLR = () => {
const pboard = $.NSPasteboard.generalPasteboard;
return ObjC.deepUnwrap(
pboard.pasteboardItems.js[0].types
).includes("public.html") ? (
Right(
ObjC.deepUnwrap(
$.NSString.alloc.initWithDataEncoding(
pboard.dataForType("public.html"),
$.NSUTF8StringEncoding
)
)
)
) : Left("No HTML in clipboard");
};
return main();
})();
Thanks!
It generally does the job, except that linebreaks are created where there was no linebreaks. (Edit: Sorry. I spoke too soon on this. That was because the pandoc command does not have ==--wrap=none== parameter. Once it is added, the result will be the same.)
No, I did not. Now I have found more scripts that does the job. The swift code below also convert rich text in the clipboard to HTML. I know nothing about ObjC, but I believe it can do it in a similar way.
import Cocoa
let type = NSPasteboard.PasteboardType.html
if let string = NSPasteboard.general.string(forType:type) {
print(string)
}
else {
print("Could not find string data of type '\(type)' on the system pasteboard")
exit(1)
}
I didn't either, but I did search for “RTF” – and what did I find?
Your Swift code is not going to work unless the HTML class is already on the clipboard.
AppleScript ⇢ AppleScriptObjC ⇢ Code
--------------------------------------------------------
# Auth: Christopher Stone { Heavy Lifting by Shane Stanley }
# dCre: 2021/10/11 23:34
# dMod: 2021/10/11 23:34
# Appl: AppleScriptObjC
# Task: Convert RTF on the Clipboard to HTML.
# Libs: None
# Osax: None
# Tags: @Applescript, @Script, @ASObjC, @Convert, @Clipboard, @RTF, @HTML
# Test: Only on macOS 10.14.6
# Vers: 1.00
--------------------------------------------------------
(*
References:
Script Debugger Forum:
https://forum.latenightsw.com/t/converting-an-nsattributedstring-into-an-html-string/1048/2
Keyboard Maestro Forum:
https://forum.keyboardmaestro.com/t/how-to-convert-rich-text-in-the-clipboard-into-markdown/24203/7
*)
--------------------------------------------------------
use AppleScript version "2.4" -- Yosemite (10.10) or later
use framework "Foundation"
use framework "AppKit"
use scripting additions
--------------------------------------------------------
# Get the pasteboard.
set thePasteboard to current application's NSPasteboard's generalPasteboard()
# Get RTF data from the pasteboard.
set theData to thePasteboard's dataForType:(current application's NSPasteboardTypeRTF)
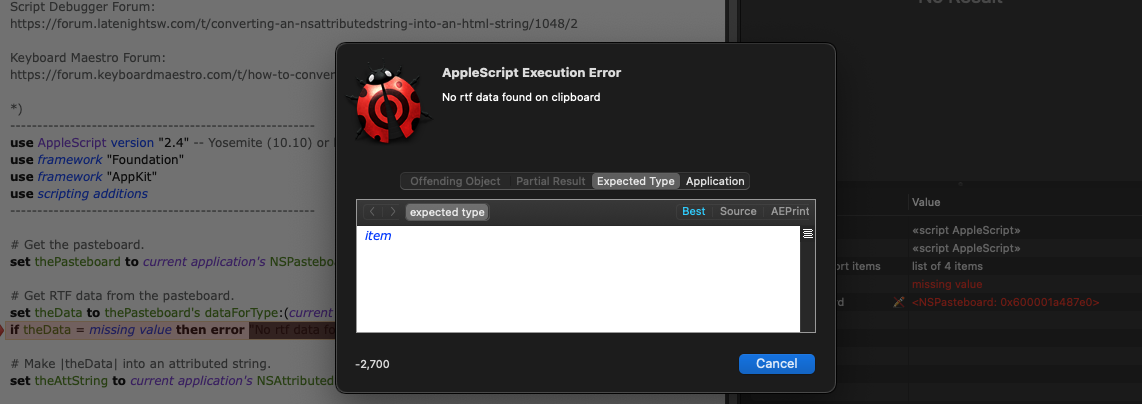
if theData = missing value then error "No rtf data found on clipboard"
# Make |theData| into an attributed string.
set theAttString to current application's NSAttributedString's alloc()'s initWithRTF:theData documentAttributes:(missing value)
set elementsToSkip to {}
# set elementsToSkip to {"doctype", "html", "body", "xml", "style", "p", "font", "head", "span"} -- ammend to taste
# Create an NSDictionary.
set theDict to current application's NSDictionary's dictionaryWithObjects:{current application's NSHTMLTextDocumentType, elementsToSkip} forKeys:{current application's NSDocumentTypeDocumentAttribute, current application's NSExcludedElementsDocumentAttribute}
# Extract |htmlData| from |theAttString| Using |theDict|.
set {htmlData, theError} to theAttString's dataFromRange:{0, theAttString's |length|()} documentAttributes:theDict |error|:(reference)
if htmlData = missing value then error theError's localizedDescription() as text
# Convert |htmlData| to an NSString.
set theNSString to current application's NSString's alloc()'s initWithData:htmlData encoding:(current application's NSUTF8StringEncoding)
# Convert NSString to text.
return theNSString as text
--------------------------------------------------------
This is a bit verbose, but it's flexible and quick.
The source is text is from the extracted PDF annotations via Zotero plugin Zotfile.
I have pasted the text to an rtf file and zipped it in the OP.
Maybe I'm confused with what is Rich Text or HTML text. Maybe the extracted text is already HTML? Then I have no idea how to tell which is Rich Text and which is HTML. Maybe that explains why I had to change «class RTF » to «class HTML »?
Thanks, @ComplexPoint.
This is very educational for me. The only thing I knew was that the clipboard contains either a plain text or a rich text.
I copied a sample text and ran your macro. It shows as:
{
"public.html as string": "<html><head><meta http-equiv=\"content-type\" content=\"text/html; charset=utf-8\"></head><body> (<a href=\"zotero://open-pdf/library/items/INMMCSCL?page=3\">Vanhoozer 2012:783</a>)</body></html>",
"public.html as data": "<html><head><meta http-equiv=\"content-type\" content=\"text/html; charset=utf-8\"></head><body> (<a href=\"zotero://open-pdf/library/items/INMMCSCL?page=3\">Vanhoozer 2012:783</a>)</body></html>",
"public.utf8-plain-text as string": "(Vanhoozer 2012:783)",
"public.utf8-plain-text as data": "(Vanhoozer 2012:783)"
}
I see html and utf8-plain-text here. Now, osascript -e 'the clipboard as «class HTML»' starts to make sense to me.
I don't see rtf or rich text. So, I don't know how osascript -e 'the clipboard as «class RTF»' would work out.
Also, what is the difference between public.html as string and public.html as data? The values are the same.
I tried the macro after copying a file. I see more information, such as file-url as propertyList. But, they still have the same value.
{
"public.file-url as propertyList": "file:///.file",
"public.file-url as string": "file:///.file",
"public.file-url as data": "file:///.file",
"public.utf16-external-plain-text as propertyList": ".file",
"public.utf8-plain-text as propertyList": ".file",
"public.utf8-plain-text as string": ".file",
"public.utf8-plain-text as data": ".file"
}
Yes – the script just tries the full cartesian product of {pasteboard item types} * {"propertyList", "string", "data"}, and that will often entail some redundancy.
You just need to find any single combination of (UTI, data format) that works for your purpose.
Where UTI (Uniform Type Identifier) is drawn from a set including {public.html, public.rtf} etc etc
and data format is drawn from {"propertyList", "string", "data"}
That combination will depend on the app you have copied from, and the kind of data you want to extract from the clipboard.
If I'm working with graphics copied to the clipboard from OmniGraffle, for example, the combination might be
I came across this thread (years later) looking for a way to take rich text out of the clipboard and convert it to Markdown. I have discovered a very simple way to do this in Shortcuts. My shortcut has three actions:
Get clipboard
Make Markdown from Clipboard
Stop and output Markdown from Rich Text
Just use "Execute Shortcut" in KM and send the results to a variable or a clipboard. So far, this has worked flawlessly for me.