If you only have singlebyte characters in your input (for example [a-z][A-Z][0-9]) you can also get away with a very nice and short Perl solution:
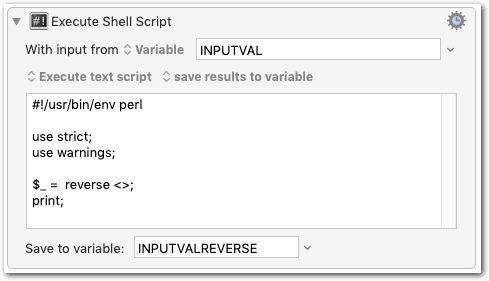
#!/usr/bin/env perl
use strict;
use warnings;
$_ = reverse <>;
print;
Or as a command-line one-liner:
perl -pe '$_ = reverse'
[Skip the rest of this post if you are not interested in reversing any kind of UTF characters.]
The pitfall (or: “what I have learned today  ) is that this fails to a different degree if the string contains multibyte UTF characters like
) is that this fails to a different degree if the string contains multibyte UTF characters like ä, é, ợ, đ etc.
For the more simple things like Käse, résumé etc. it seems to be sufficient to explicitly set the stdin mode to “utf8” with
binmode STDIN, ':utf8';
With this modification, the Perl script from above produces correctly esäK and émusér.
But with more “sophisticated” strings like Rượu đế this is not enough.
So far the only solutions I have found to work with any kind of strings are these:
1) — Splitting the string with the \X special (“Match Unicode eXtended grapheme cluster”):
#!/usr/bin/env perl
use strict;
use warnings;
binmode STDIN, ':utf8';
$_ = join('', reverse <> =~ /\X/g);
print;
From perldoc.perl.org
2) — Or using the Unicode::GCString module and reversing the result as list:
#!/usr/bin/env perl
use strict;
use warnings;
use Unicode::GCString;
binmode STDIN, ':utf8';
my $str = Unicode::GCString->new(<>);
$_ = join '', reverse @{ $str->as_arrayref };
print;
From Stack Overflow
As test case I have used the nice Vietnamese word Rượu đế, found in a related discussion on perlmonks.org.
The correct reverse string is ếđ uợưR.
Depending on the used technique, I’ve seen two different wrong results:
-
ÌÌeÄ u£ÌÌoÌuRwhen using the multibyte incompatible script at the top of this post, and -
́̂eđ ựơuRwhen only setting the binmode to utf8.
If you want to try the scripts above:
All the scripts are written to be used in a KM Shell Script action with input from a variable (stdin), as shown in the screenshot at the top.
You should also set the output to a (non-local) variable, because the KM Shell Script Results window doesn’t show all characters correctly. (At least on my computer.)
Edit/PS:
If you want to test a script with the Vietnamese test string, you have to copy it from the following line (do not copy one of the inline instances in the text!) :
Rượu đếAlthough the string looks different here, this will maintain the original composition of the characters. Once you paste the string into a Unicode-compliant editor (and using a compliant font) on your computer it will again look like “ Rượu đế ”, but with the correct composition.
Alternatively you can copy the string from inside this macro.