I do see what you mean, and that's odd that it's happening for you and not for me. Here are my system details: System info:AppleScript version:2.7System version:10.13.6, although I don't think that's especially pertinent to what's going on. As some diacritics are character modifiers that operate upon a preceding character, it almost seems like the reversal has caused the diacritics to have been removed for the text transformation, then reapplied afterwards when the base characters were in reverse order. Whether that would be the AppleScript engine processing the characters wrongly, or the textviews of Script Editor drawing them wrongly, I couldn't guess. It could even be the fonts being used in Script Editor, some of which could lack full unicode support. You could try Script Debugger, though I suspect the result will be the same as it uses the same AppleScript engine, the same compiler, the same fonts, ...
Yes, there we match. And that result is perfectly expected from what I know about Keyboard Maestro and the pros and cons of the various different methods of reading its variable data.
I have not as yet, but I will do so and report back my findings.
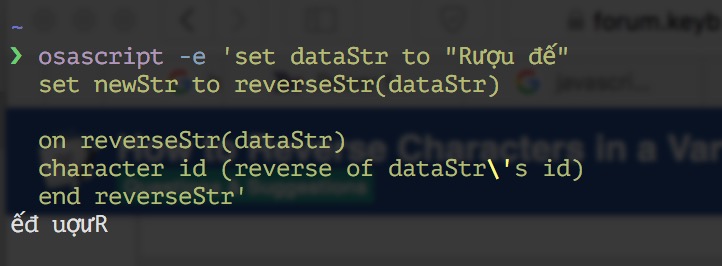
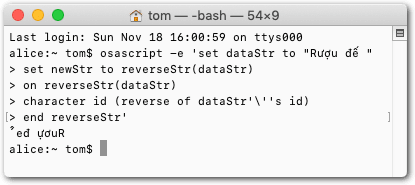
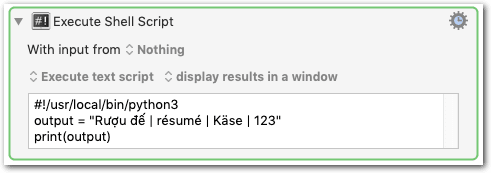
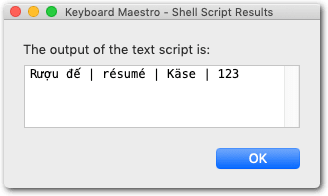
But I did try it in a shell, which can be fussy with non-Roman characters, but it seems happy with them in this instance:
I think I've got to the bottom of why it's happening. I'll update you a bit later when I have some extra time. But, the long and short of it is that the id property isn't well suited for string reversals, and it seems my earlier hunch about the way modifying diacritical characters are added onto a base character was a pretty good guess.
Yes, that’s what I thought initially. (Comparable to Perl’s reverse which is usable here only if the string is splitted by grapheme clusters (\X, script “1)” from here).
But then you showed me that this is not the case on your computer…
Chris, in case you have downloaded my macro with the script collection, can you confirm my results on your system, or do you get different results for some of the other scripts too? (With the long and the short test case.)
I would really like to know if those different results are limited to the AppleScripts, or if it is something more general…
As far as I can see I get the same results as you when running through your test macro.
Although I wasn't able to test your Perl script that uses the GCString module. It's not on my system, and I'm not seeing it when searching MacPorts – so I'm not wanting to mess with tying to install it at the moment.
That's interesting. What gave you the inkling/feeling that the id property wouldn't work as well ?
I investigated this disparity a bit more and found a partial explanation. The characters @ccstone and I were using in the tests that succeeded on our systems were different to the characters you were using that failed on your system. Here's your test string, taken from the testing macro you shared:
① Rượu đế
And here's the test string that I copied-and-pasted from your post that originally cited these erroneous results:
You can't really blame me for thinking that they are identical. However, when I saw that other methods in the collection were throwing out errors of the same nature, while I was still getting a positive result in Script Editor, it occurred to me that the issue stemmed from the nature of the input. So, I ran this command:
use framework "Foundation"
① set a to current application's NSString's stringWithString:"Rượu đế"
② set b to current application's NSString's stringWithString:"Rượu đế"
a's isEqualToString:b --> false
(and, in fact, thanks to the menlo font, you can see demonstrable visual difference between the two strings, noticeably in the topmost diacritics above the e:
Rượu đế | Rượu đế • seemingly the same
Rượu đế | Rượu đế • noticeably variant as soon as the code block encloses them
Here's the output of an AppleScript acting on these two variants:
② id of "Rượu đế" --> {82, 432, 7907, 117, 32, 273, 7871}
① id of "Rượu đế" --> {82, 117, 795, 111, 795, 803, 117, 32, 273, 101, 770, 769}
As you can see, ① is comprised of 12 separate unicode characters, 5 of which are modifying characters (combining diacritics) that result in a 7-character long string; ② has precisely 7 individual characters, all of which are precomposed entities.
@Tom, I'm guessing you originally composed or obtained that Vietnamese string from a source that made use of combining diacriticals, and this became the test case for your macro. But, when it was transcribed to Keyboard Maestro from where I copied the text, the multi-character entities were substituted for their precomposed counterparts, which I think is a process called normalisation. Thus, when I came to test my handler, it appeared to pass with flying colours.
The nature of the undesirable outcomes of my handler and a couple of the others, are a result of exploding the word not just into characters, but decomposing the characters into into their individual entities. If one simply recombines them, there's nothing to see that's out of the ordinary:
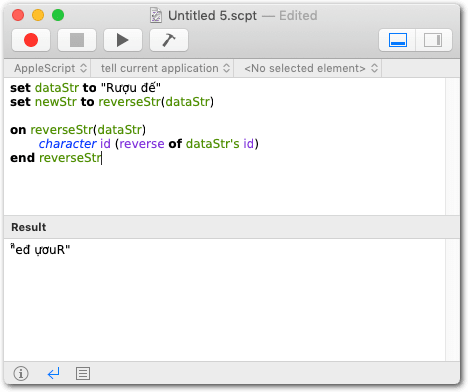
① character id (id of "Rượu đế") --> "Rượu đế"
But when one applies a reverse transform:
① character id (reverse of id of "Rượu đế") --> "́̂eđ ựơuR"
each of the diacritical marks has been displaced to the left, which now makes sense: the 7 characters were decomposed fully into 12 entities, so when recombined into a string, ended up modifying the character that was previously to the other side of it, resulting in new character compositions. (When the reverse transform is applied again—being a symmetrical transformation—the original string is restored.) Obviously, when operating on the precomposed version of the string, this issue never arises.
As for why the id property would fully decompose a string whereas characters of... would not is peculiar. But it's very good to now be aware that this happens.
Rather simple: The Perl scripts I experimented with have taught me that this string seems to be reversible only when treating it as a sequence of grapheme clusters, not as a sequence of “characters” or code points. (See the Perl scripts using the regex with the \X class and the Unicode::GCString module, “1)” and “2)” in the post.)
Since also the JavaScripts on the thread showed that “issue”, I was not really surprised to see the “character id” AppleScript doing the same. (The surprise —for me— rather was, that @ccstone’s “reverse of characters” AppleScript worked correctly.)
Thanks for investing the time and finding out that we worked with different source strings. I didn’t consider that the forum website might change the composition of the characters. Definitly my fault, especially since the original post with that string explicitly mentioned that it is necessary to use <pre> tags instead of <code> tags in order to not manipulate the characters. But somehow I had overlooked that warning. Sorry.
PS:
I have added a warning and a copy-safe version of the string to my post above.
Thanks for taking the time for testing, Chris. Fortunatly @CJK could solve the mystery now.
PS:
Perl modules are usually installed from the CPAN repository via the cpan client (comes with any Perl installation), or the cpanm client (separate install, but IMO the better way). So, MacPorts shouldn’t be involved here. (Except for installing the cpanm client, if you wish so.)
Thanks for this. And now I know what a grapheme cluster is. This one, seemingly-innocuous task request by a user has ended up teaching me a lot of good stuff about text.
My learning odyssey started when I had the idea to post a nice and elegant Perl one-liner with reverse, but soon noticed that Perl’s reverse out of the box wasn’t even capable to reverse “Käse” correctly.
Then I found out that “Käse” reverses correctly if Perl just gets the input in an adequate form (via binmode STDIN, ':utf8';), the same problem as with your initial AppleScript.
For a short moment I was content, but then came across the Perlmonks thread with that nasty lovely Vietnamese test string, where UTF8 stdin wasn’t enough, but requires to be split by \X before reversing it. (Where \X matches grapheme clusters, instead of characters like the ordinary dot does.)
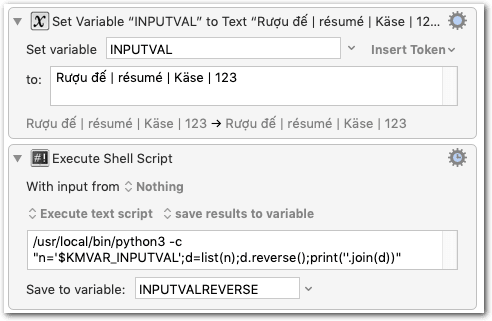
It works fine with non-Unicode inputs, but crashes with the following error with Unicode input:
File "", line 1, in UnicodeEncodeError: 'ascii' codec can't encode character '\u0308' in position 8: ordinal not in range(128) Macro “Reverse a text string” cancelled (while executing Execute Shell Script).
However, the exact same script works perfectly in Terminal with either ASCII or Unicode inputs.
How can I fix this?
I'm giving up trying Python with Unicode characters in KM, because the simple act of printing them seems to hit an encoding barrier in the "Execute a Shell Script" KM action
Results in: Traceback (most recent call last): File "/var/folders/9c/7mk3_3vn6h1gy0pr78nj28kc0000gn/T/Keyboard-Maestro-Script-4C47A7F1-7471-4BD0-BE08-D1A6EA221917", line 3, in <module> print ("R\u01b0\u1ee3u \u0111\u1ebf | r\xe9sum\xe9 | K\xe4se | 123") UnicodeEncodeError: 'ascii' codec can't encode characters in position 1-2: ordinal not in range(128) Note: same error whether output sent to KM variable or to system clipboard or to a window display or set to ignore results. Also same error if code executed from a script file
However, bypassing KM output and sending the output directly to the system clipboard works fine:
BTW, my interest in Python is because I can hack it better than Perl or JS. AppleScript interest has faded after struggling with inconsistent syntax and implementations over the decades. Maybe I should learn JXA
I’m not into Python at all, but can it be that it is a python install, path, symlink or environment issue?
Are you sure your python link in /usr/local/bin is pointing to a python3, and not to a python2?
(There seems to be a significant difference in Unicode handling between python2 and python3.)
I’m seeing a plethora of “pythons” in my /usr/local/bin: python, python2, python2.7, python3, python3.7; seems quite a mess. But I have no clue of the good python install practices, I use it just to run scripts, when needed.