I am building a AirTable DB for Medical Records, which I will share with everone when I am done.
Part of this is a table of Diseases, which has the Disease Name, and the CDC URL for more info.
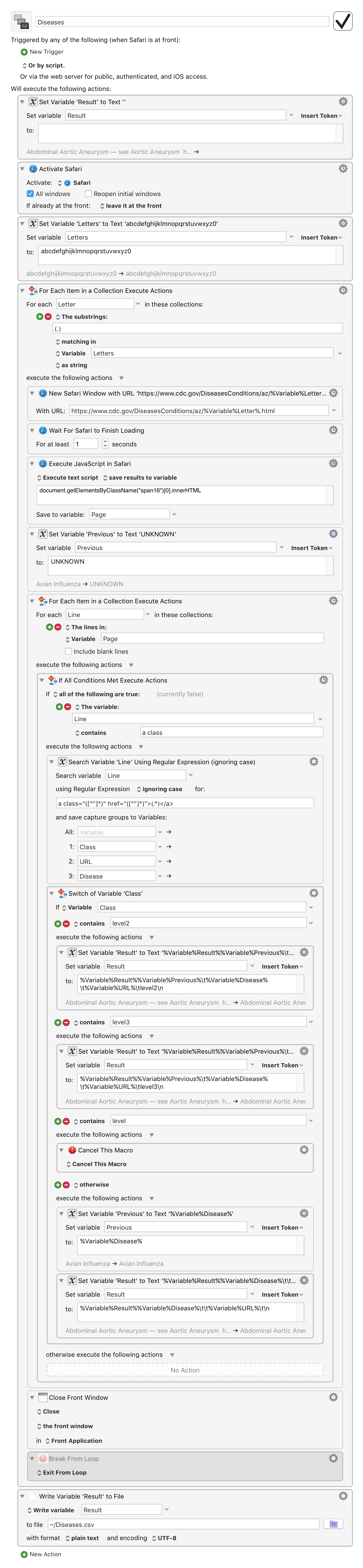
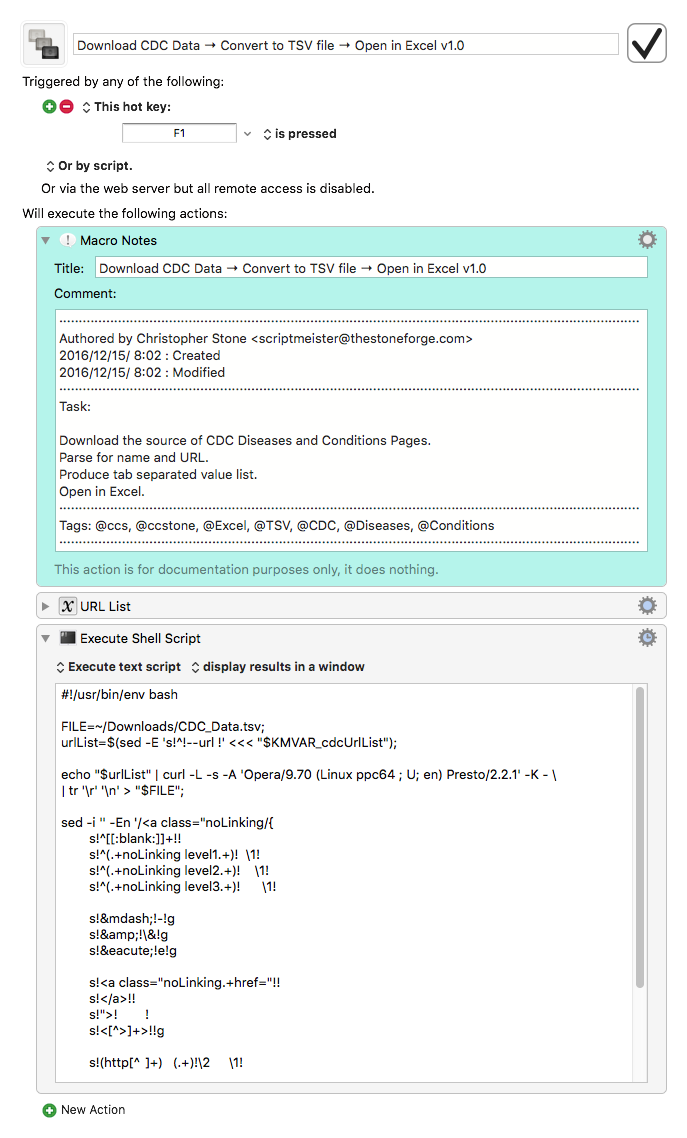
This will get you most of the way there. It processes all 27 pages, and creates a csv (well, actually tsv) with the first column being the named of the disease, the second column being the sub-type or see also entry, the third column is the URL, and the fourth is either level2 (sub disease) or level3 (see also). I have not processed the HTML for the Disease names, but that should be just a matter of a few search & replaces.
Peter, thank you so much! This is totally awesome!
I hope this did not distract you for long from your work on Keyboard Maestro. And, hopefully, other users will find this as a great example of the power of Keyboard Maestro in scraping (extracting) web pages.
Thanks to Peter's great macro, I was able to easily extract all of the data from the CDC disease pages. Then, with just a few RegEx tricks in TextWrangler, I cleaned up the extraction and moved some data to other columns. The cleanup had nothing to do with the extraction -- that was perfect. It was due to the alternate names that CDC embedded in the main name field.
I hope to have my AirTable Database app ready to publish/share within a few days.
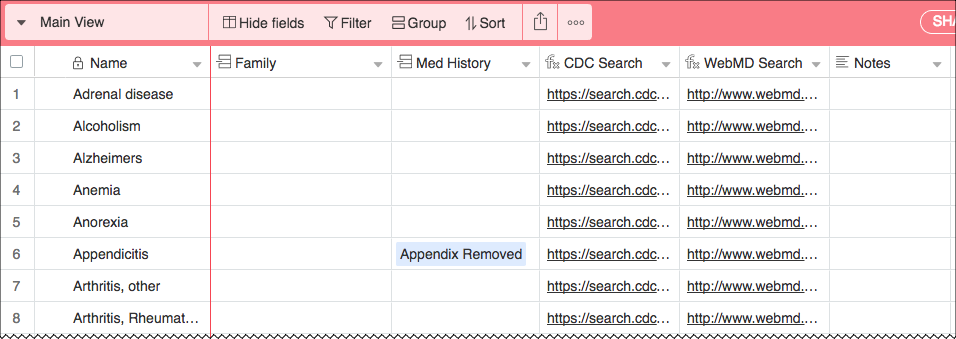
Here is what my Diseases table is looking like for now. AirTable is very powerful, but also veryf easy to use. Here I easily created two formula fields to dynamically generate the URL for search of the disease at CDC and WebMD.