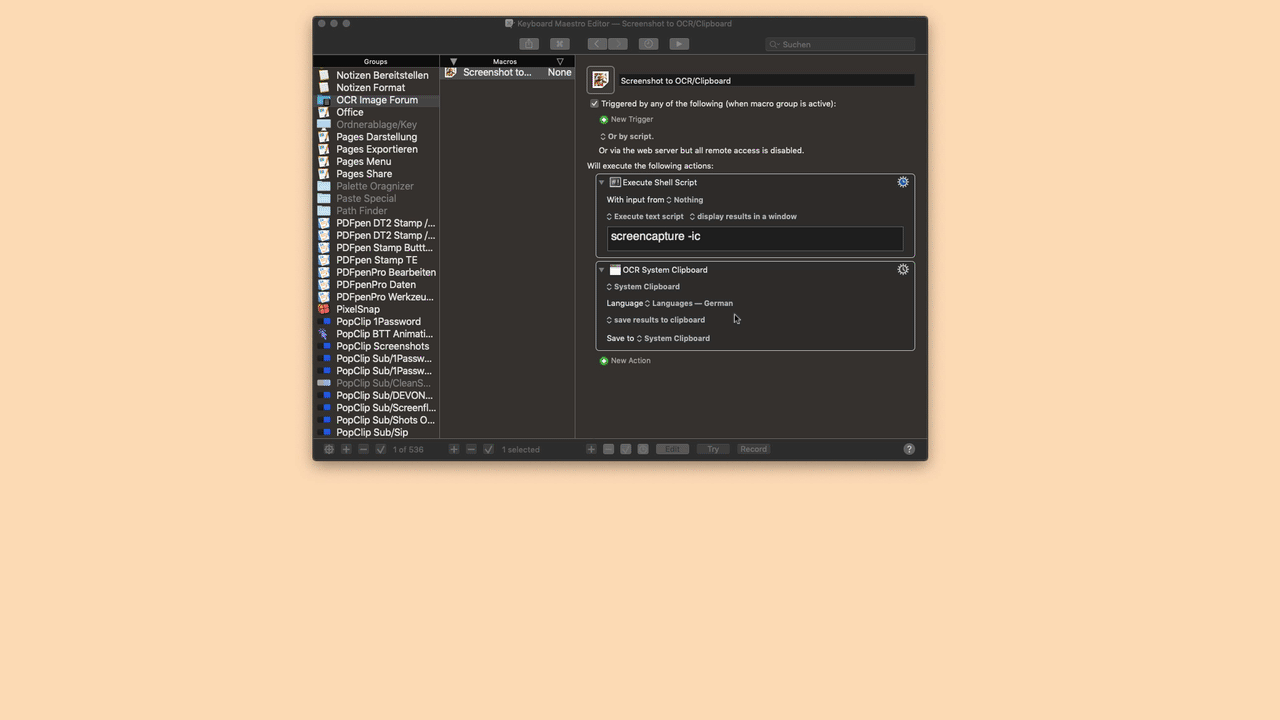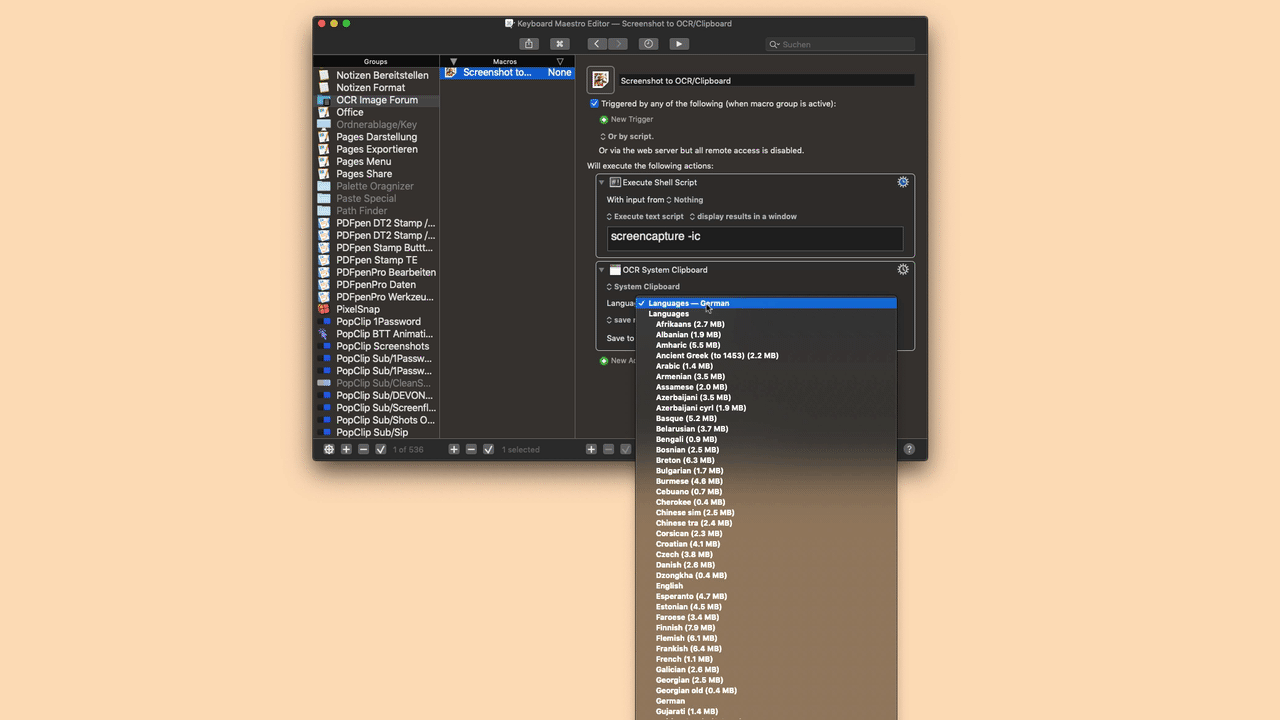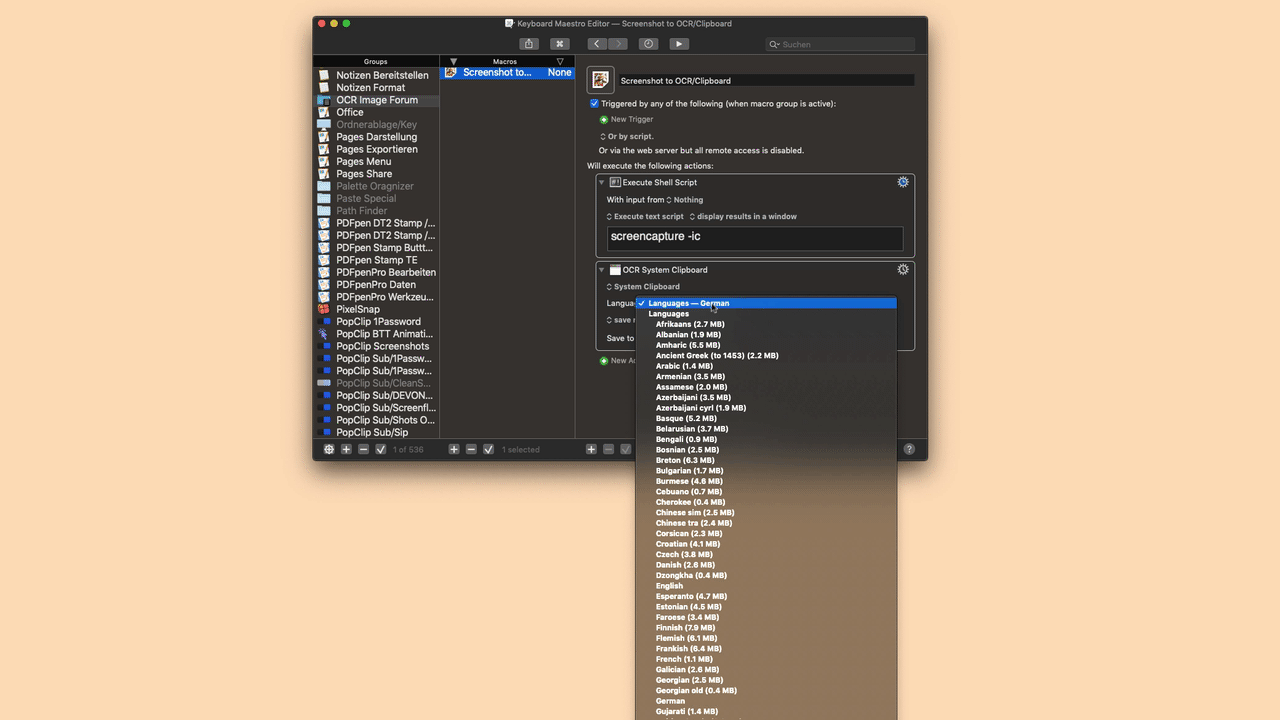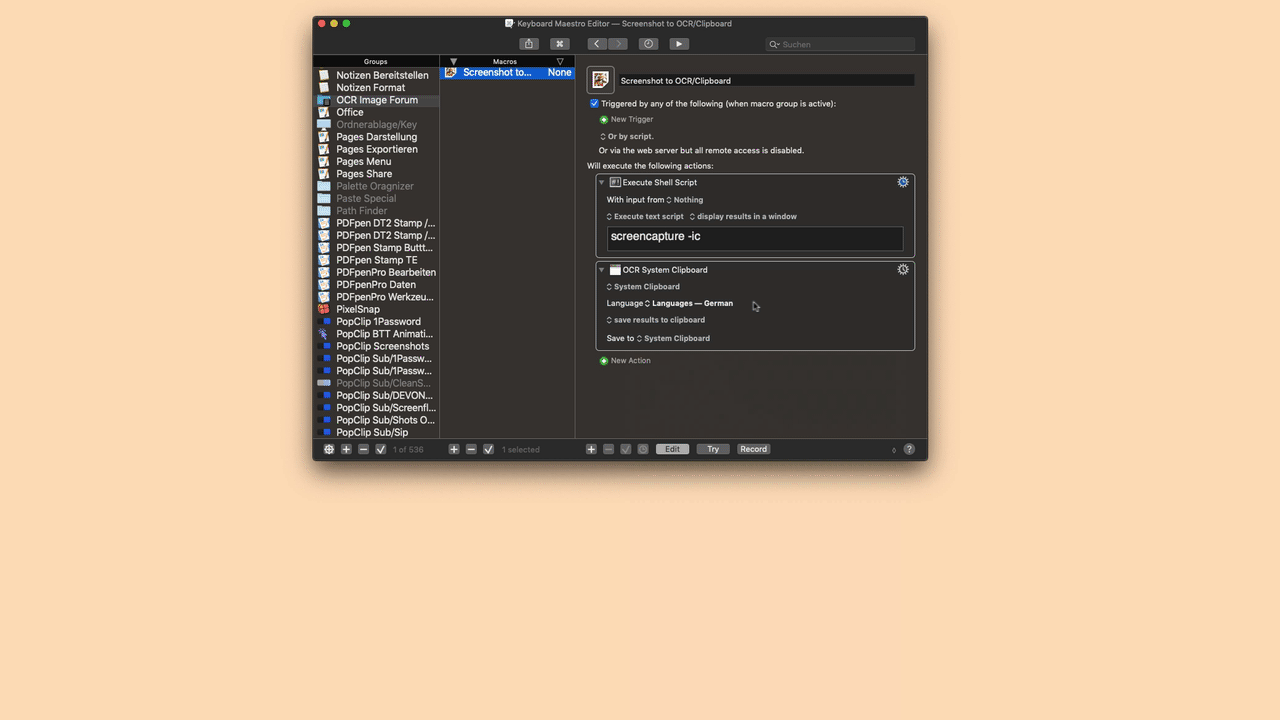
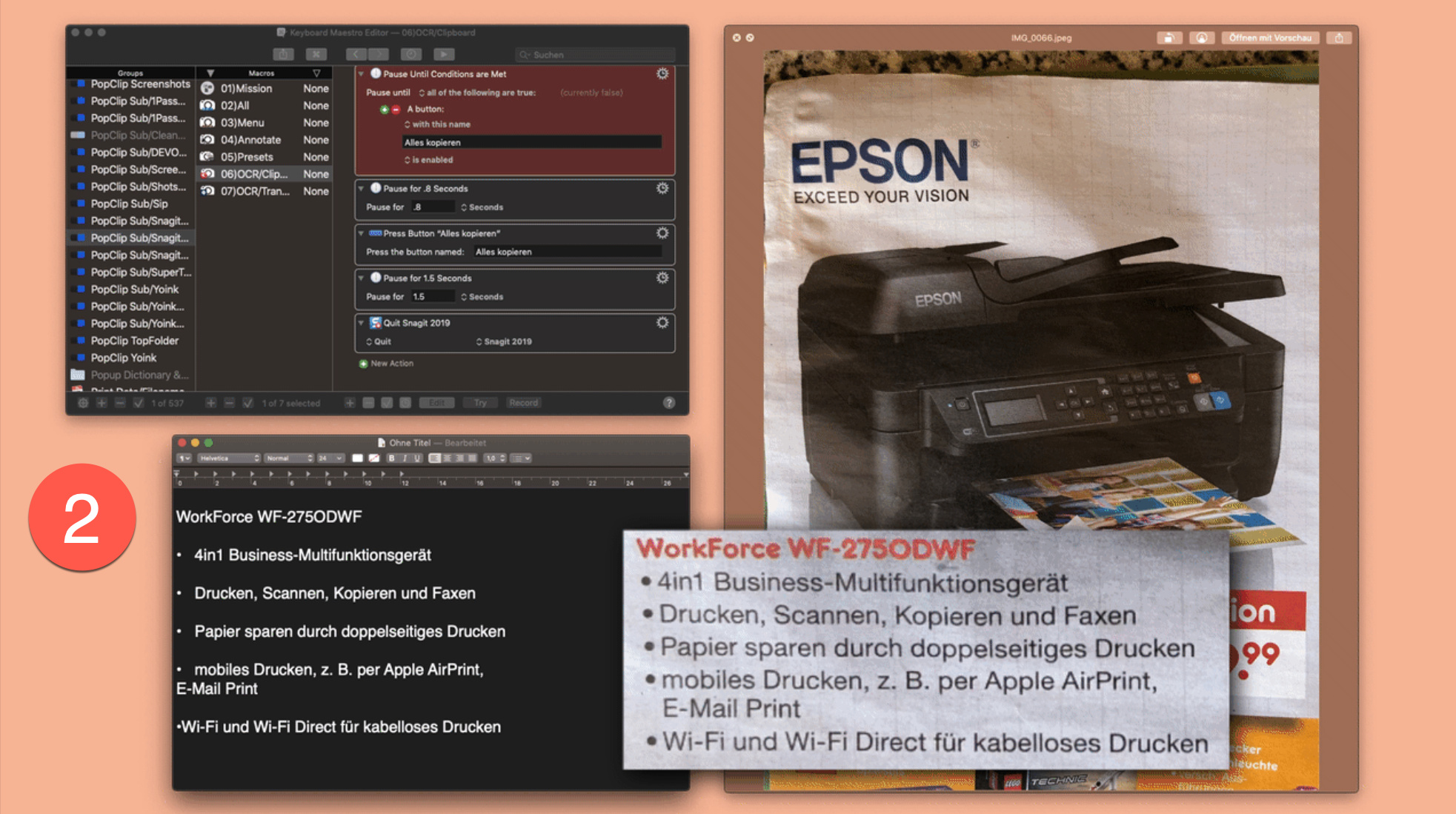
It would be much easier to see the source image used, and the two resulting German OCRed text.
Not that it is likely to make any difference, Keyboard Maestro uses Tesseract, and the Tesseract training data. It is technically possible to train it yourself, but it is certainly possible that the German training data is inadequate.
That said, in my testing in English, it has worked surprisingly well for me, although I do admit I generally am using it on “perfect” text, captured from screen, rather than scanned from a magazine article.
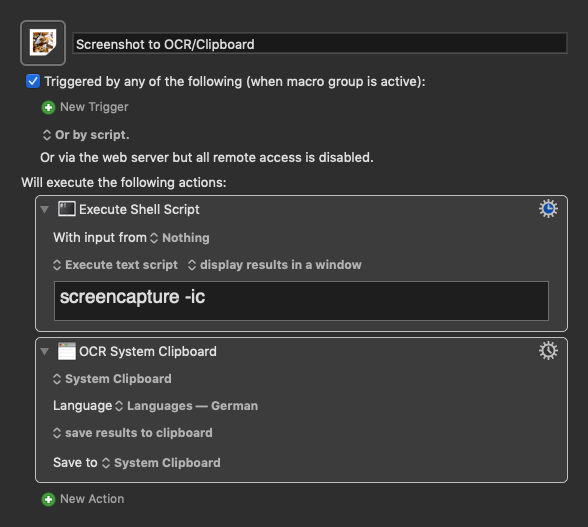
Thank you, @appleianer , for sharing your OCR macro.
My first experience with screenshot OCR in German is excellent, exactly what I was searching for!
Walter
Hello everyone, this is my first contribution. I have only recently started working with Keyboard Maestro, but with great enthusiasm. What a unique software and a great community here!
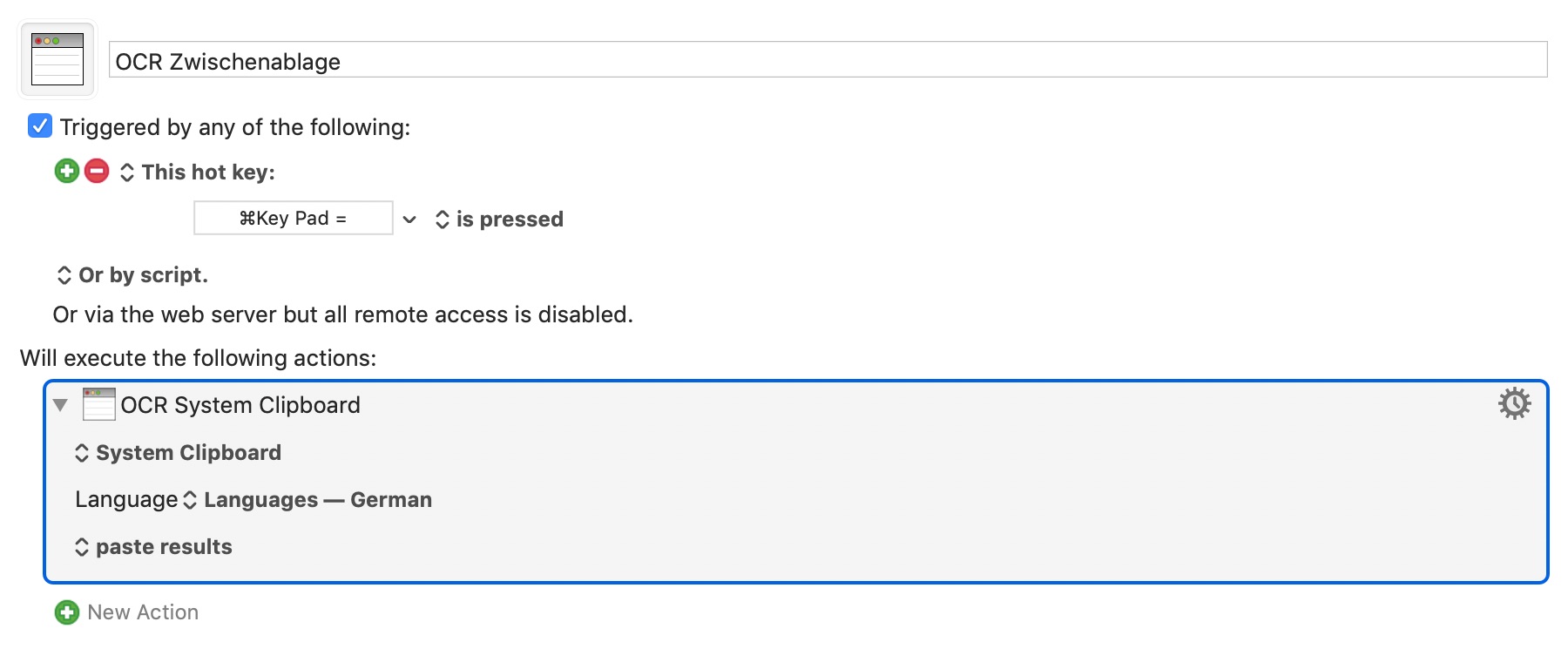
The OCR function works perfectly, but not in every way. If a screenshot is made directly to the clipboard under Mojave, it doesn't work. The log says:
OCR Image cannot get target In macro “OCR Zwischenablage” (while executing OCR System Clipboard).
Assertion Failed: ainfo, file: …/Source/Actions/AOCRImage.mm:110, value: 0
However, when I save the screenshot as a file, open it in Preview and copy it to the clipboard, it works. Strange …
Your macro looks fine, and I had no problems with the same action, taken from a screenshot in Mojave to the clipboard.
Before you run the macro, check your Clipboard History Switcher, and verify that the image is in the clipboard as expected, and has not been replaced by some text or something else.
Thank you for your input. I restarted the Mac and immediately executed the macro, with the same result. Maybe this is just a problem on my machine. I hope a clean install with Catalina in September will solve the problem. In the meantime, I will find a workaround or use the solution from appleianer.
Before you run the macro, check your Clipboard History Switcher, and verify that the image is in the clipboard as expected, and has not been replaced by some text or something else.
Then use the built in OCR Image macro (via the gear menu on the image entry in the Clipboard History Switcher).
I copy a part of the screen with Command-Shift-4 to the clipboard.
I see this part when I switch to the Finder and use the “Show clipboard” command.
But the Clipboard History Switcher remains empty. No image.
Then:
When I open Preview and choose “New from clipboard” (or similar, I use the german localization), I can see the image.
When I copy this image with Command-A and Command-C, it appears immediately in the Clipboard History Switcher and the OCR command behind the gear icon works as expected.
It's fantastic to have OCR built into Keyboard Maestro 9, and it's using 'Tesseract', the open-source OCR engine I'd previously hacked into some of my shortcuts using shell commands.
I've got a pattern and whitelist that I'd previously used with Tesseract to OCR SMPTE timecodes, and I'd love to be able to use this as a custom language inside Keyboard Maestro's OCR step. Is there any way to do this? I did some searching and tried plopping them into ~/Library/Application\ Support/Keyboard\ Maestro/Tesseract\ Trained\ Data/Custom, but that doesn't seem to have had any effect. I've attached those customization files in case anyone wants to try to get them to work.
Wow! I made a few tests in Japanese and it works very well.
One problem, though, is that it works mainly for horizontal text.
I checked for a solution in Tesseract’s documentation, and it says that this option is available for vertical text recognition:
tesseract-ocr-jpn-vert
It would then be great to have the two choices in the macro menu:
tesseract-ocr-jpn for horizontal text
tesseract-ocr-jpn-vert for vertical text
I can't seem to duplicate this, but I do think I saw that sort of behaviour when I was testing something earlier, so it is possible there is a bug somewhere with the clipboard switcher display.
Just should be able to do it, but the file must be in aTesseract .traineddata file (and don't ask me what the format of that is or how you generate one, as I have no idea).