Currently the vert files are deliberately disabled, because frankly I don't understand them.
It may be that I can just enable them and they will just work for you.
If you can grab the Japanese_vert.traineddata file, rename it to something like JapaneseVert.traineddata and put it in the Custom folder, it might “just work” - if so, let me know and I'll see what I can do about enabling them going forward.
FWIW I love the new OCR capability. So helpful for grabbing text from images etc. I have mine mapped to ⌘⌥⌃⇧4 to keep similar muscle memory as ⌘⇧4 for a grabbed screenshot.
If I successfully make the traineddata file, how do I make it usable for KM9? Is there an install location? The location in this post doesn't exist on my system.
I have found the KM provided OCR engine to be excellent, yielding accurate results 99% of the time. I'm running Keyboard Maestro 9.0.5 on macOS 10.14.6 (Mojave).
I have the same experience as you do. I use this feature on countless use cases. From Webcast conference note taking, to working around the VPN Citrix copy and paste limitations of my job, to quick and simple searches using the @ccstone macro that you modified. At first I didn't use it because I just didn't understand a use case for it. Now, I must have 10 different implementations for it. It's beautiful.
I agree that the OCR action works well. I should have clarified that the problem I was having, and still have, is that screenshotting using standard MacOS keyboard shortcuts is not sending the captured image to the clipboard for the OCR action to use. That must be a MacOS bug.
Thank you so much for the macro by @ccstone. And thank you @ccstone for making it. The command line script does send the screenshotted image to a clipboard usable by the OCR action. I don't understand why or how, but this works just as well as I could have hoped.
Hi from 2021 :),
Thank for for this macro, though, I'm having trouble with it.
For comparison I used iText (an app on the app store). The maestro macro is much lower quality. Other's who replied here are reporting good results. I'm wondering if I'm missing something?
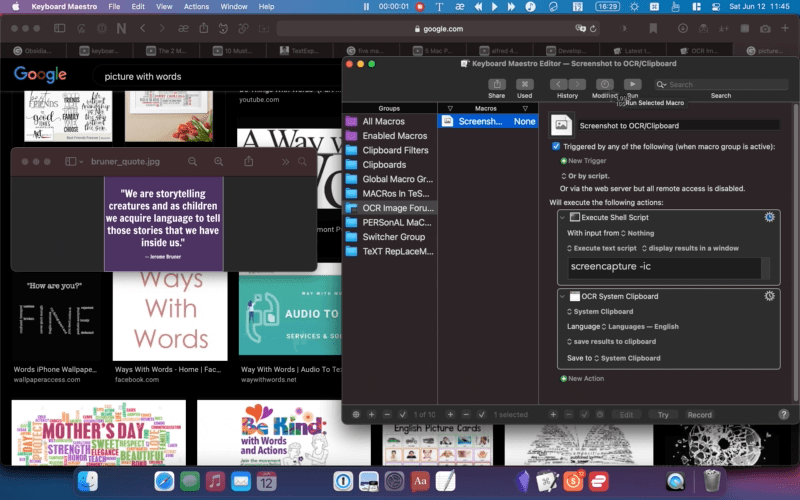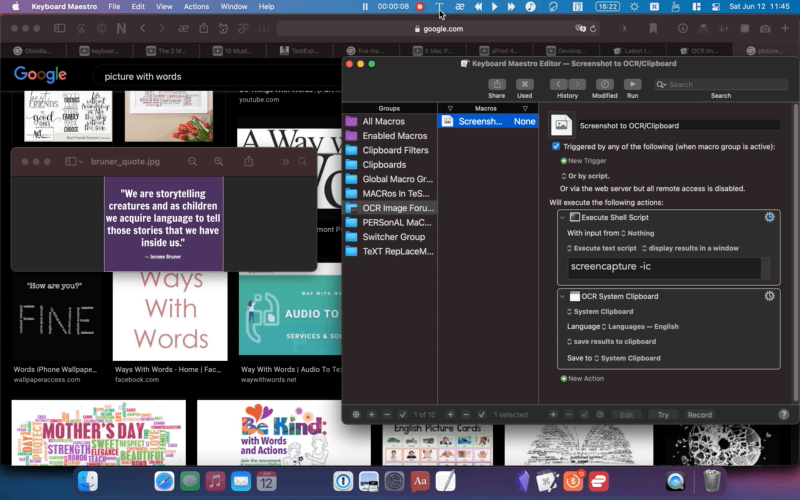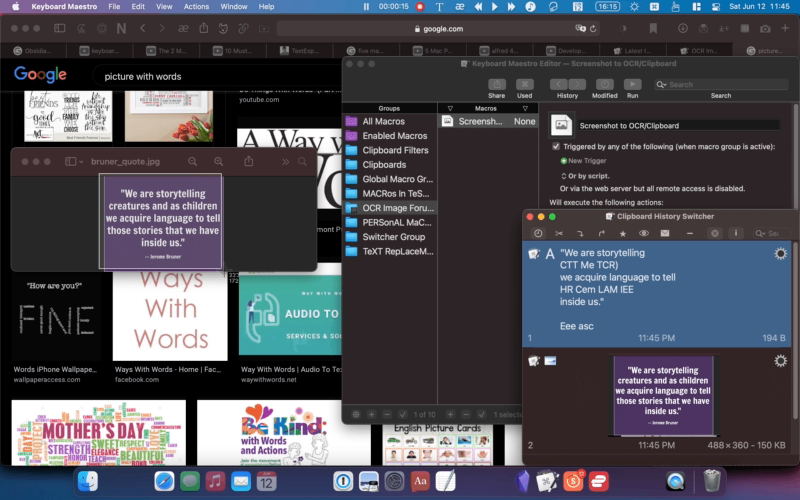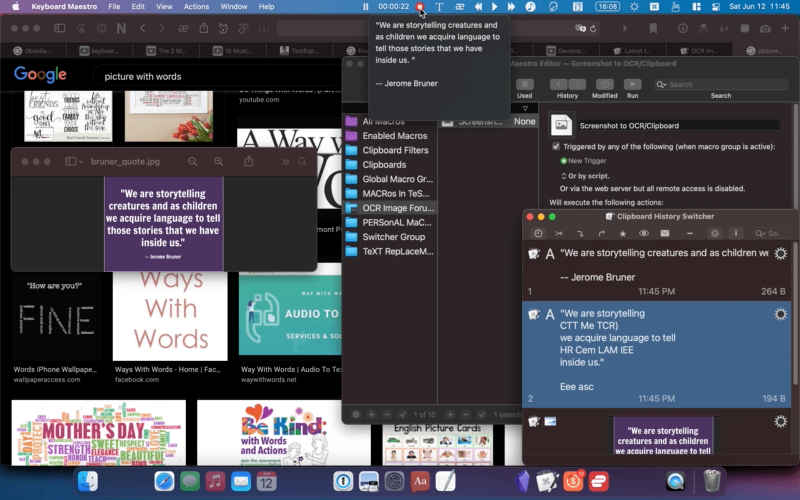
OCR using the macro:
"We are storytelling CTT Me TCR) we acquire language to tell HR Cem LAM IEE inside us."
Eee asc
OCR using iText:
"We are storytelling creatures and as children we acquire language to tell those stories that we have inside us. "
The advantage is a very good text recognition and I can still access the screenshots later.
Since I often have to translate something into another language, I can transfer the captured text from the clipboard to the online translator DeepL.
The advantage here is that I can still add or correct the text to be translated.
I am a big SnagIT user for many years, and have tried its OCR Grab Text a number of times.
For almost all of these use cases the KM OCR provided better results.
I am curious to see how iText OCR will perform.