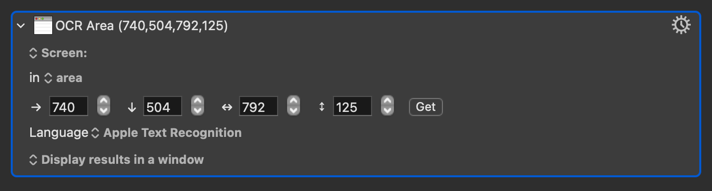
However, if I move my browser screen to the left, I get totally different results.
Now @peternlewis explained the following a few years ago, and I never understood it enough to get it to work - No matter what I do, I'll get a blank OCR:
Can someone explain how I can get the same result no matter where my browser is on the screen? I've tried entering the WINDOW (1, Right) + and - entries with coordinates above and get nothing.
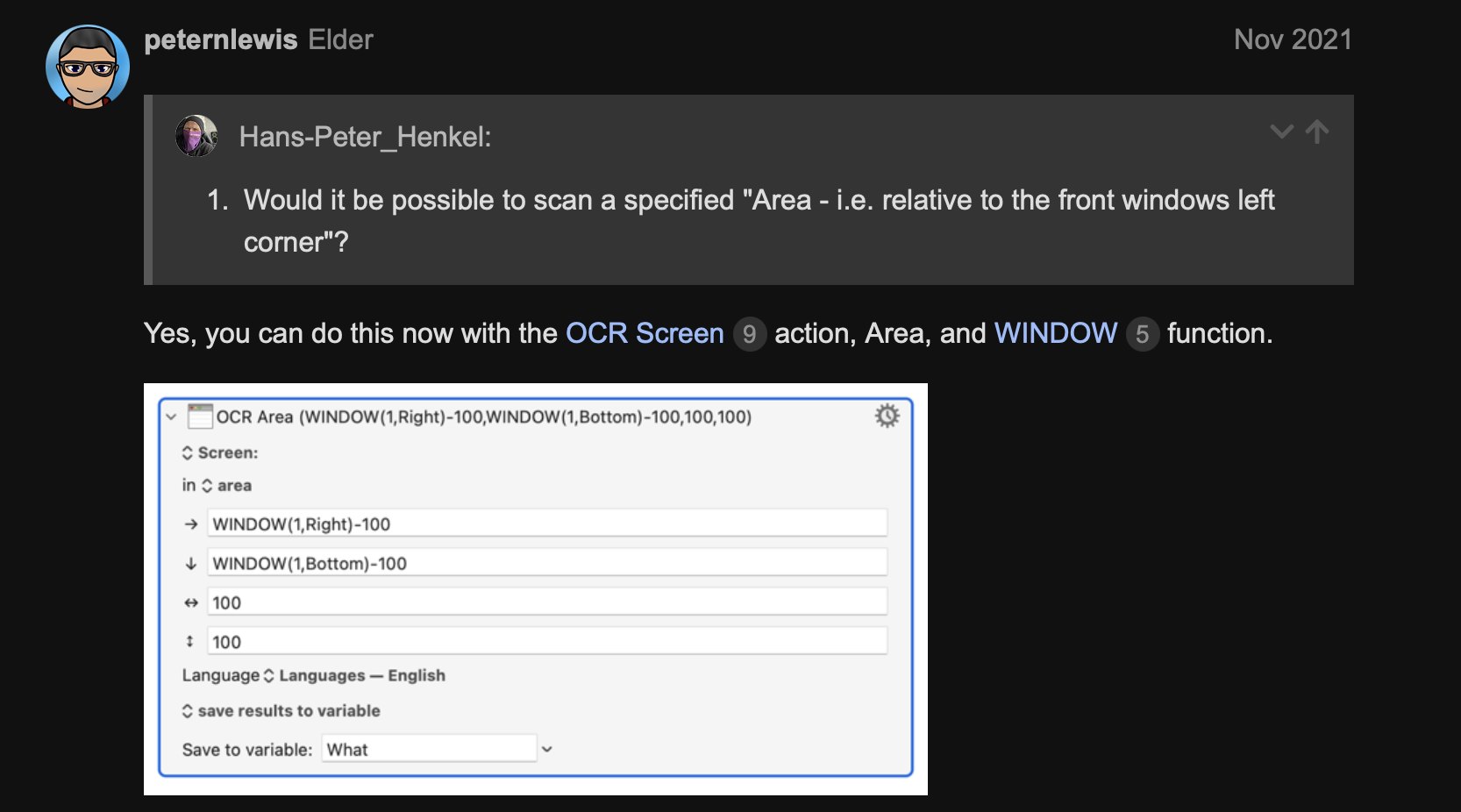
The action uses absolute coordinates, (0,0) being the top-left corner of your main screen. So you need to, somehow, get the absolute coordinates of the area of interest of the window, wherever that window might be.
So if the rectangle of that area of interest is:
100 pixels in from the left edge of the window
200 pixels down from the top edge of the window
800 pixels wide
125 pixels high
...and assuming the window is frontmost, you'd do:
Whether you pick left edge or right will depend on how the web page reflows when resized -- you may even need to base from the centre for those that keep the middle the same and pad out both sides!
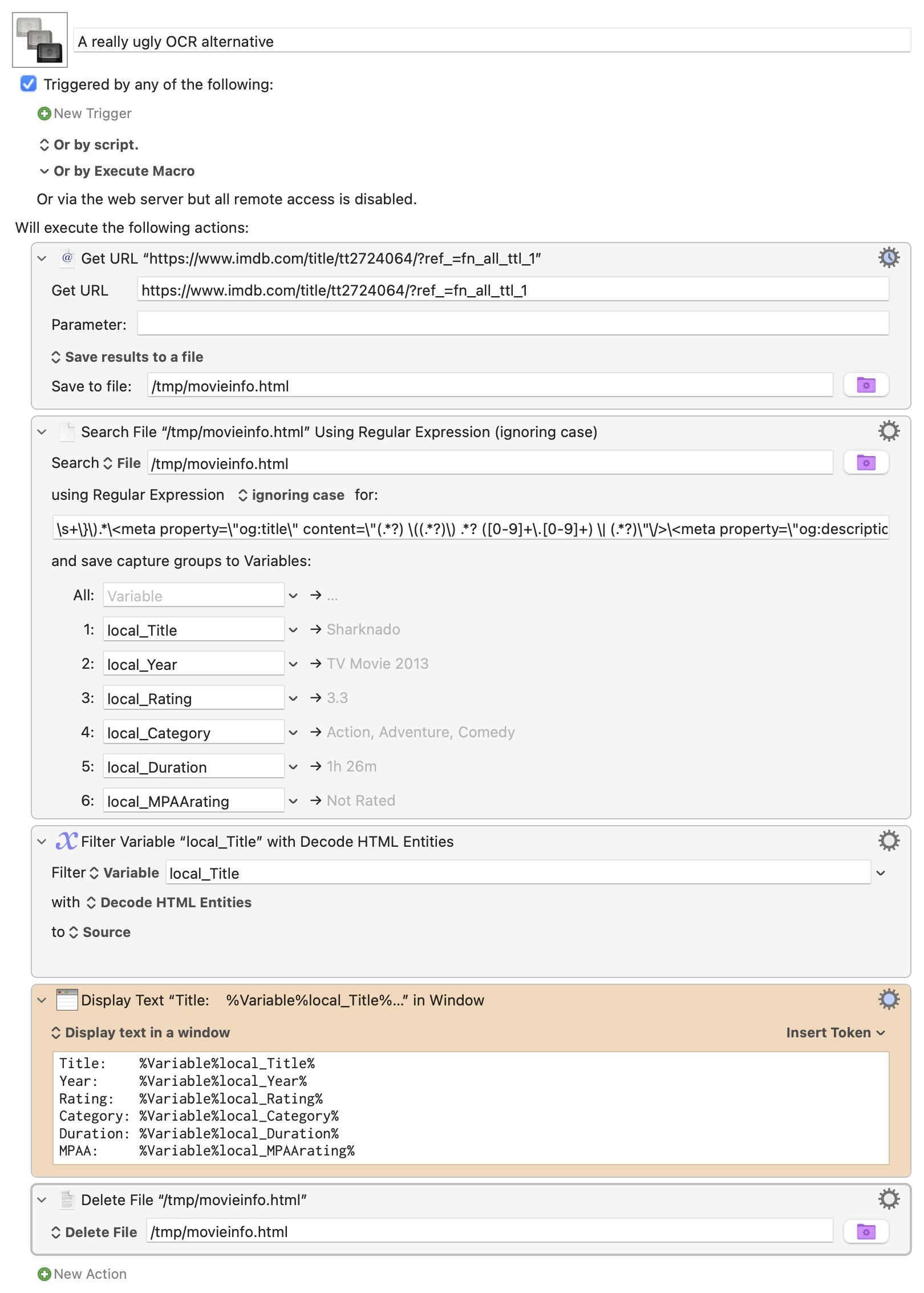
...you can get it without OCR at all. Ideally, if you know JavaScript for Automation, you could get it that way. But lacking that, you can brute force the data out with some ugly regular expression work:
It's not the recommended solution, but it does work...until they change their page format even slightly. With JavaScript for Automation, you could probably read those fields more directly, making it more robust. But that's beyond my skills.
@Nige_S - I was still getting nothing results-wise, using the OCR Area action, until I changed the language to Apple Text Recognition. I had it on Languages - English. I think @peternlewis indicated, a while ago, that Tesseract didn't like white on black text. As soon as I changed it, I got data. Lessons learned. Thanks for your explanation.
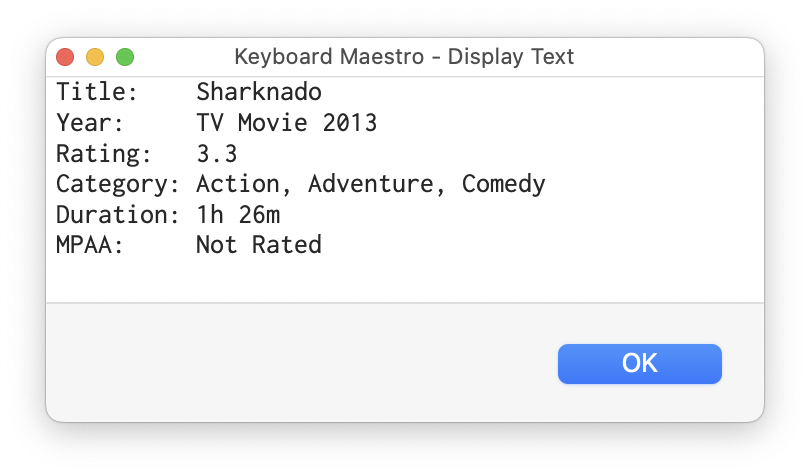
@griffman - Your brute force method was mean. I haven't a clue how to use JavaScript for Automation but I'll look deeper at your regex capture groups to see if I can add the Director, stars, writers and description as an exercise. Your setup worked very well for the information groups you pulled.
The "screen area" in the OCR action is no different from the screen area in several other actions. It's just an area identified by absolute coordinate values. I use each of the following actions frequently, which also contain absolute area values.