Is there a way to pull stock info from a URL within KM or do I need to use a java script to place it into a Variable? I thought I could just use the Get URL command - but had no luck.
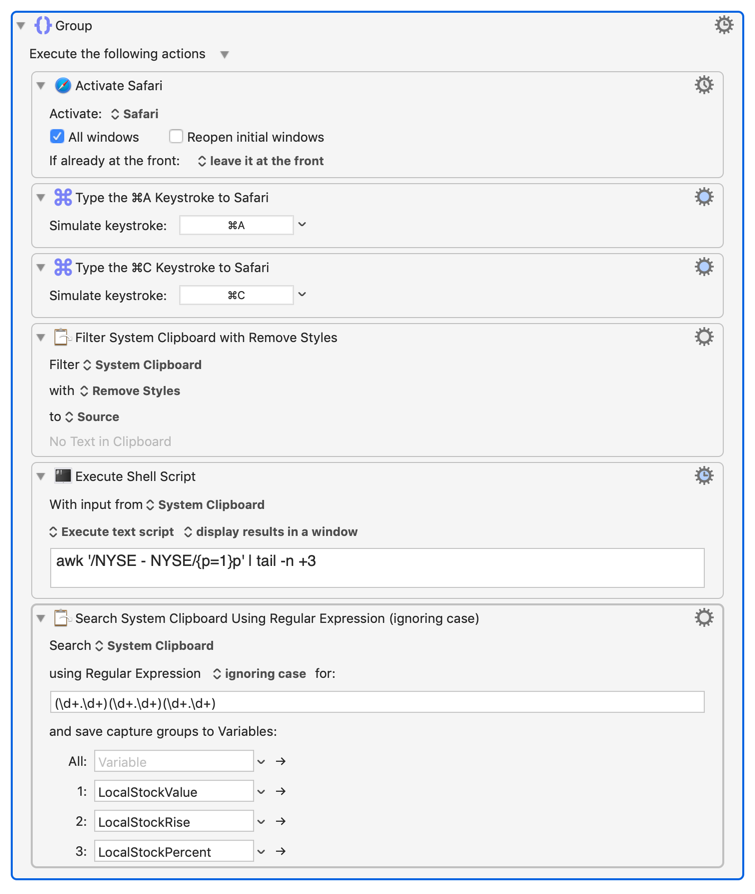
In this case my approach is probably not the best, because people who know AppleScript will tell you that AppleScript is much better. And then there are people who know how to extract data from Safari fields by using the "Set Variable to Safari Field" action. But I'm less sophisticated than those people. So here's my approach. 1) Load the page. 2) Send CMD-A then CMD-C to the page to copy all the text to the clipboard. 3) Examine the clipboard manually to see which words come before and after the value you need. 4) Use a shell command to strip of the before and after data. 5) Assign the remaining text to your variable.
When I perform step 1 to 3 here's what the data looks like around the price:
**Finance results**
[ **Market Summary** ](https://www.google.com/search?client=safari&rls=en&q=finance&ie=UTF-8&oe=UTF-8&stick=H4sIAAAAAAAAAOPQeMSozC3w8sc9YSmpSWtOXmMU4RJyy8xLzEtO9UnMS8nMSw9ITE_lAQCCiJIYKAAAAA&tbm=fin&sa=X&ved=2ahUKEwj1076ouYvkAhVIZN8KHarRCzwQ6M8CMAB6BAgPEAI) **> Apple Inc.**
Follow
Following
Following
**NASDAQ: AAPL**
**206.50 USD +4.76 (2.36%)**
Closed:
So if you look you can see the data you need is the first number past the line that says "NASDAQ:" and it will probably always be that way. So from this point you can use either a KM action or a shell command to extract the price.
I'm sure there's much better ways to do it than this. But you can probably learn from this approach too.
If you tell me whether you prefer using KM actions to extract text or Shell commands, I'll help you with either method if you pick one.
Google does not really want people parsing their search results, and will actively thwart your attempts (I've learned this the hard way).
DuckDuckGo is often better (especially their non-JavaScript site at https://start.duckduckgo.com/html/) but even their results for stocks require JavaScript.
Now, I'm not sure if the HTML is dynamic or not. If it is, then that might not work.
I did try two different symbols, and reloading the page, and it seem to hold.
You need to put this in a KM Execute a JavaScript in Front Browser action, and, of course, you have to wait until the page loads.
Give it a try and let us know if it works for you.
It's hard to tell if you mean using Javascript or using shell commands. Being able to see things "clearly labelled" suggests you mean shell commands, because Javascript uses labels that are invisible to the human eye.
I'm going to guess that the three things you listed above are the three biggest numbers on the page, even though that's not clear to me because I'm not very smart about stocks, and they aren't labelled.
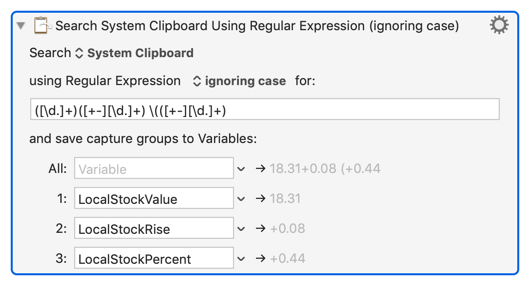
Sure, it looks easy enough. When I extract the page into the clipboard, I see this around the middle where your three numbers are:
**Alcoa Corporation (AA)**
NYSE - NYSE Delayed Price. Currency in USD
Add to watchlist
[Visitors trend2W10W9M](https://finance.yahoo.com/chart/AA?studies=Yahoo%20Finance%20Visitors%20Trend&ncid=qspvitre_wddhddl5q00)
**18.31** +0.08 (+0.44%)
At close: 4:01PM EDT
I imagine that the three numbers you want are the ones near the bottom of that block of text.
I think this website manipulated the text when I pasted it here, so not everything you see here is from the website, that's a bit of a problem here.
Here's what I would do. I would strip out everything before "NYSE - NYSE" using a shell command. The website doesn't make it easy to extract the valid data here. But I think it's safe to say the data you need always will be in a line that contains a parenthesis and a decimal point. But the one we're interested in always seems to be the first such line after "NYSE - NYSE". So those are the filters I would use. I would pipe the output from this web page into a filter that stripped out everything before "NYSE" then stripped out anything without a decimal point and parenthesis then the first line after NYSE would be your data which you could extract with a simple KM action.
So that's my approach. Writing the code would take me another 10 minutes. But if you don't object, see if you can write the code to do that. If not, I'll be back and write it.
If you could post a screenshot of the page and highlight the 3 fields (boxes, arrows, etc) that you are trying to identify it would be easier to figure out if it's possible.
I've got most of the code here, and it seems to work. One problem, I'm pretty lame with Regex so the Regex in the last action is not quite working. I'm still trying to get it to work. Maybe someone will beat me to that.
My code assumes that you've got the page loaded. Perhaps you don't have that code ready and need some help getting the URL for the page loaded and sent out. Let us know.
Oops, that second last action should be sending its output to the clipboard, not a window. But since the last action isn't debugged yet, I guess that's not really a problem.
OKAY here's what the last action should look like. It works now:
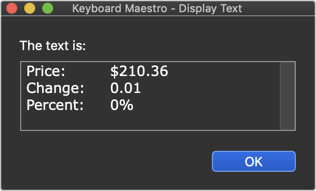
Using this code you can extract all three values from any Yahoo page. Well, I only tested one page. You need to do more testing. If something doesn't work, I can probably fix it if you tell me what doesn't work.
**Requires: KM 9+ macOS 10.11 (El Capitan)+**
(Macro was written & tested using KM 9.0+ on macOS 10.14.5 (Mojave))
#### DOWNLOAD Macro File:
<a class="attachment" href="/uploads/default/original/3X/1/0/10215fa8922de24c1b6c08bb81abcdd1684ba5ff.kmmacros">Extract Stock Data from NASDAQ [Example].kmmacros</a>
**Note: This Macro was uploaded in a DISABLED state. You must enable before it can be triggered.**
---
<img src="/uploads/default/original/3X/a/1/a178107ebe3ea6589f34f10e1ba0ae992d95f718.png" width="591" height="804">
This is just the basis for proof of concept.
If this is what you want, you can easily add Prompt for symbol, open the URL, and then get the data.
I am uploading the Macro I am working on so you can get a better picture on what I am trying to attempt. I have it working for Nasdaq, but was exploring some advise that using Yahoo would be a "safer" method.
I am making a macro that will display real time stock info on a Steam Deck.
That's cool. I like it. Although I don't monitor stocks. Very nice.
It makes me wonder if I could use it for something else like city times, city temperatures, KM debug information, or something else.
Aren't the numbers delayed by 20 minutes from most websites?
Actually when the next version of macOS arrives, it will support Sidecar, which is a way of extending the screen to an iOS device (iPad only?) so I may use that instead of this device for extra real estate.