I am trying to create a macro to remove all lines from the system clipboard that don't contain any text. The relevant lines are displayed correctly, but how do I remove them from the clipboard?
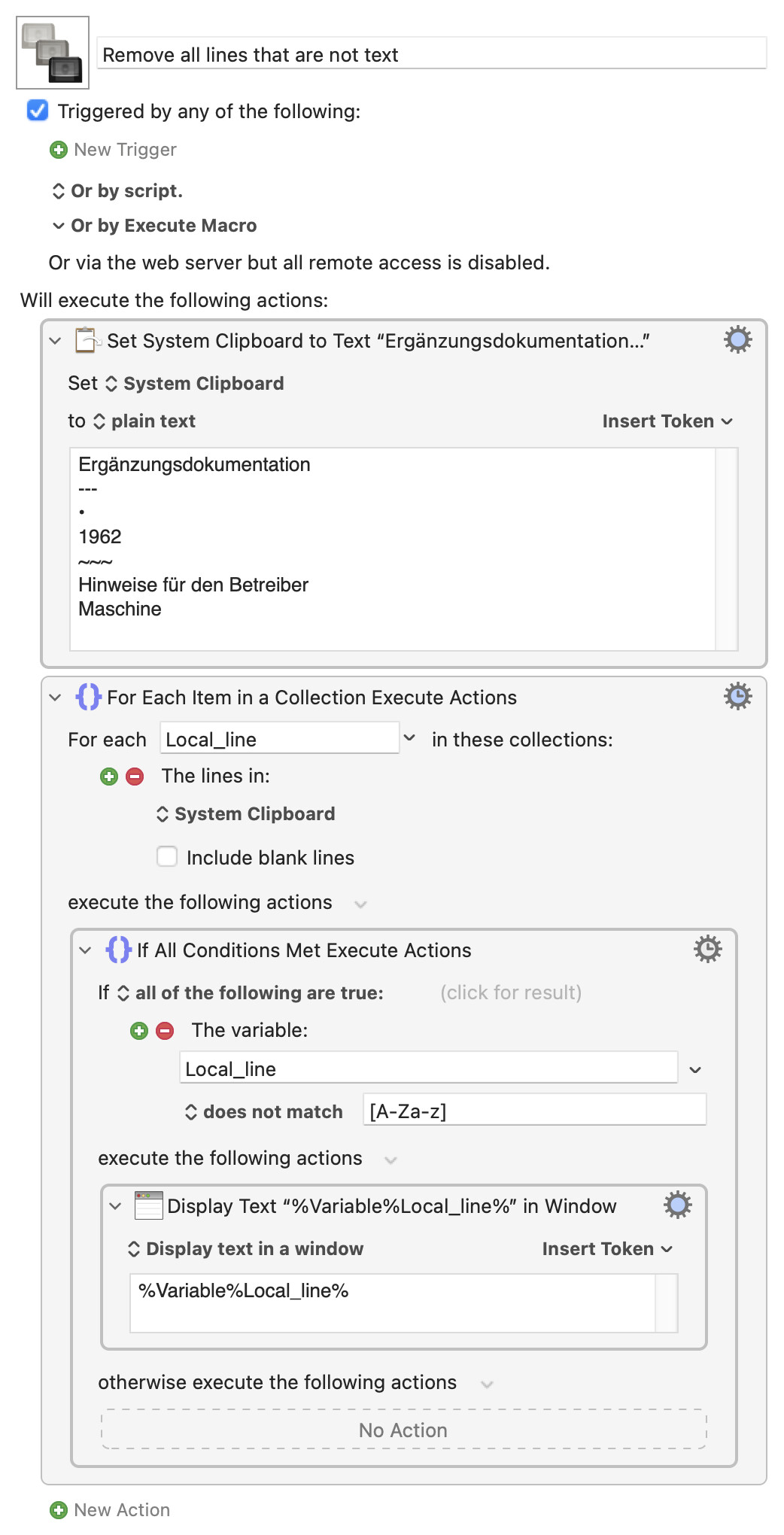
Remove all lines that are not text Macro (v11.0.3)
I am trying to create a macro to remove all lines from the system clipboard that don't contain any text. The relevant lines are displayed correctly, but how do I remove them from the clipboard?
Remove all lines that are not text Macro (v11.0.3)
One approach is to start with an empty accumulator,
adding to it only the lines that you want.
Thank you.
Another example where I had to think in the opposite direction: don't remove the lines that don't meet the criteria, but keep the ones that do.
FWIW the "filtering out" approach may be easier to sketch in script form:
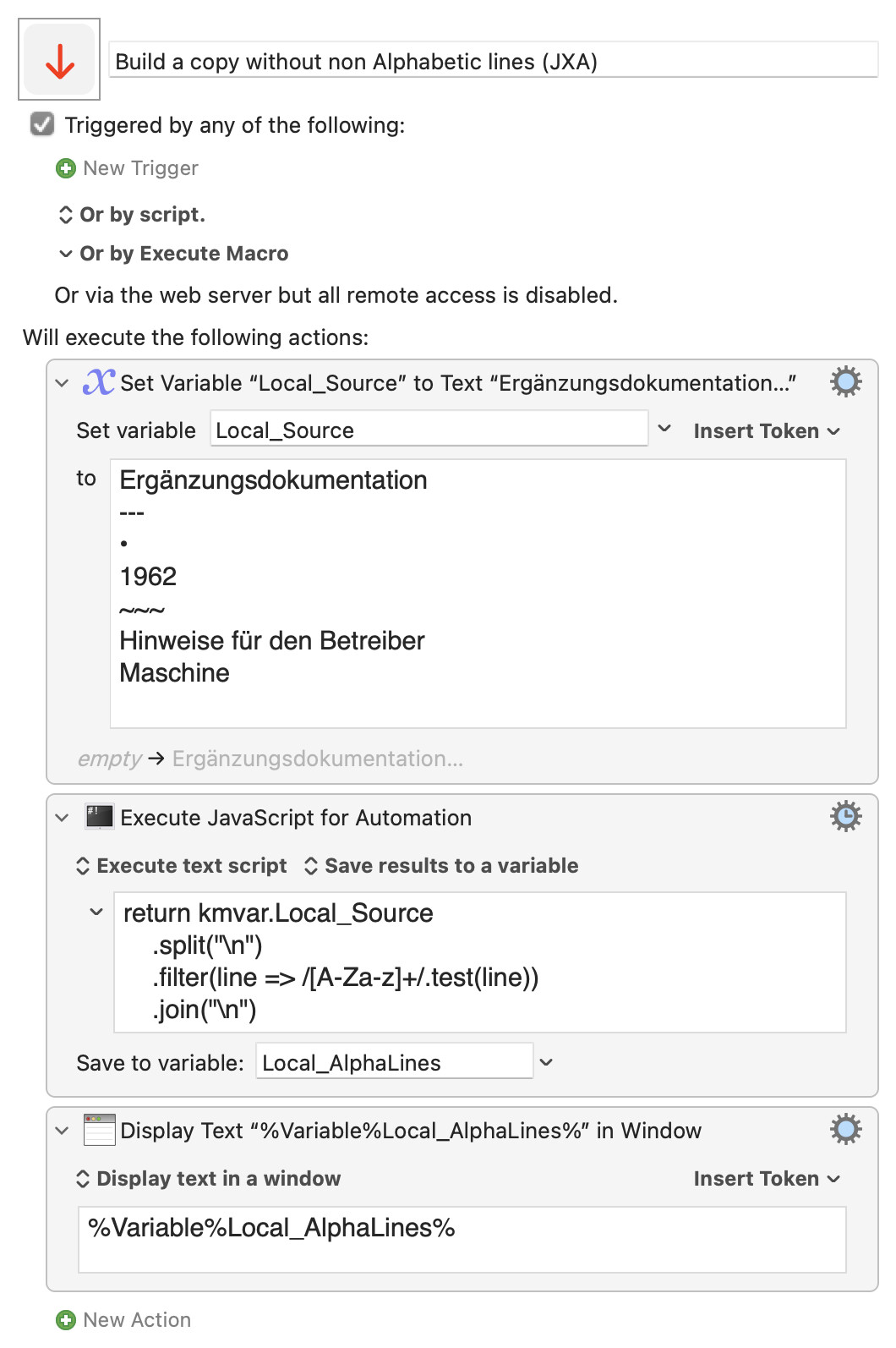
Build a copy without non Alphabetic lines (JXA).kmmacros (3.5 KB)
return kmvar.Local_Source
.split("\n")
.filter(line => /[A-Za-z]+/.test(line))
.join("\n")
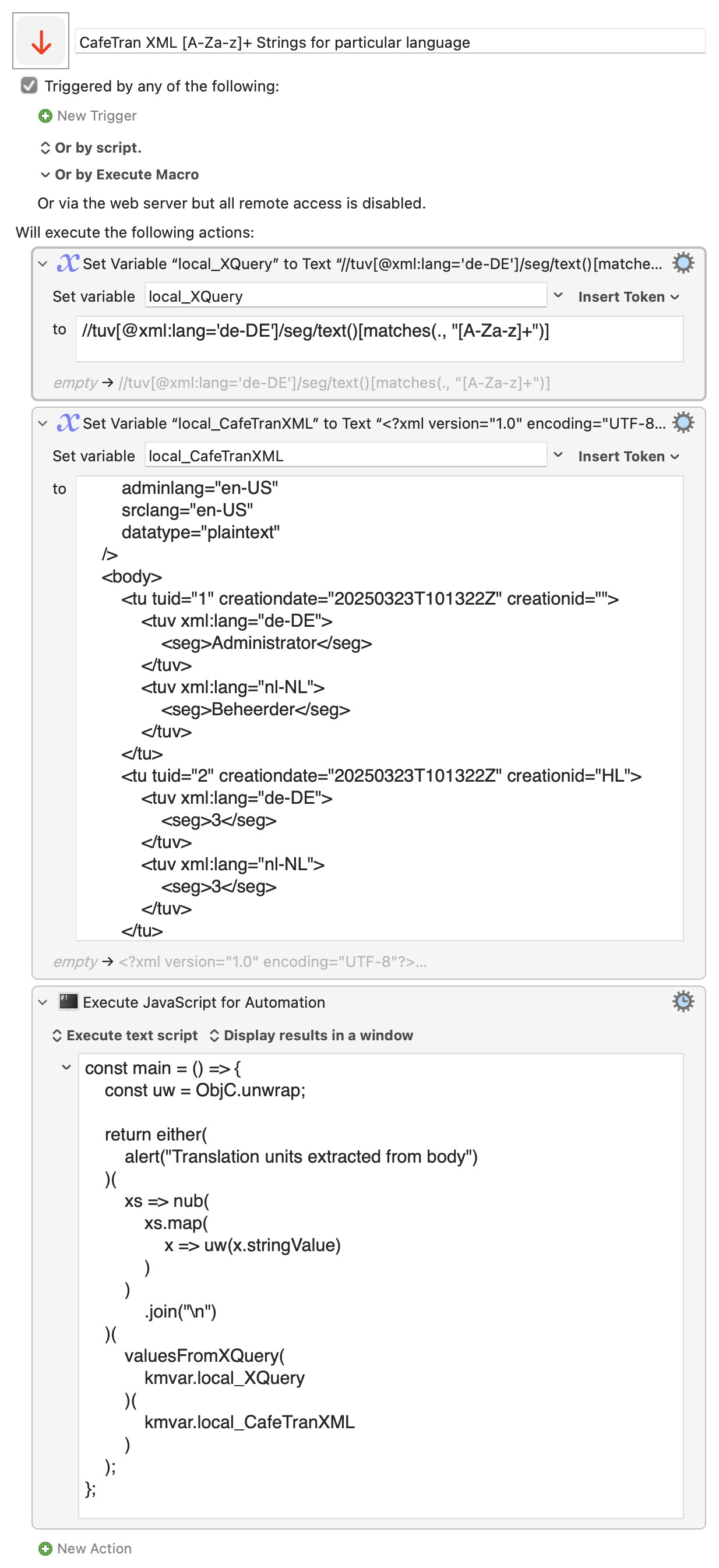
but if this is post-processing for the CafeTran XML,
then we can just add a regular expression (matches) condition to the XQuery line:
//tuv[@xml:lang='de-DE']/seg/text()[matches(., "[A-Za-z]+")]
CafeTran XML [A-Za-z]+ Strings for particular language.kmmacros (7.4 KB)
Yes it is. You're reading my mind. Thanks again.
I'm not sure if a line containing "just spaces" contains "text" by your definition. I would say yes, so here's my solution...
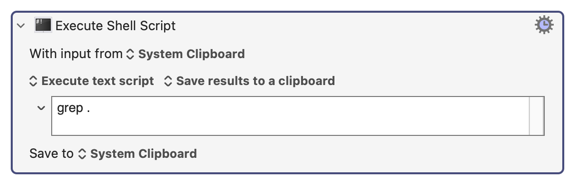
But if spaces are not text, I would need a complete list of ascii characters that are "not" text in order to modify this solution.
Judging from the replies, I may have misunderstood the point of the question, so maybe someone could help me understand…
Is the answer not simply to write the results back to the clipboard?
Yes, I know this has been solved for this specific case. But since this might be useful more generally...
Assuming the lines you want to keep are any lines that contain at least one alphanumeric character:
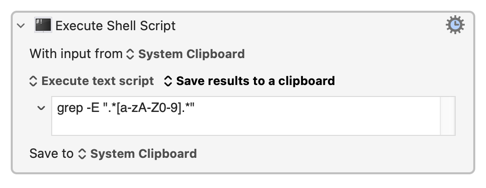
...which yes, is a version of @ComplexPoint's "accumulator".
If you want to implement your original "removal" idea -- it's always tempting to look for one "thing" to do what you want, but it's often easier to take multiple small bites at the problem. In this case:
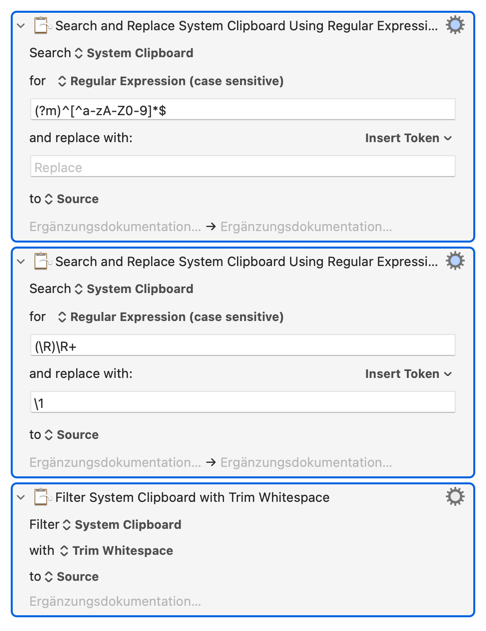
My understanding of the transform needed was from:
Ergänzungsdokumentation
---
•
1962
~~~
Hinweise für den Betreiber
Maschine
to
Ergänzungsdokumentation
Hinweise für den Betreiber
Maschine
and as the context proved to be that of values extracted from an XML file, an XQuery match() expression, either in an XPath condition, or in an FLWOR where clause, might exclude the 0-9 class.
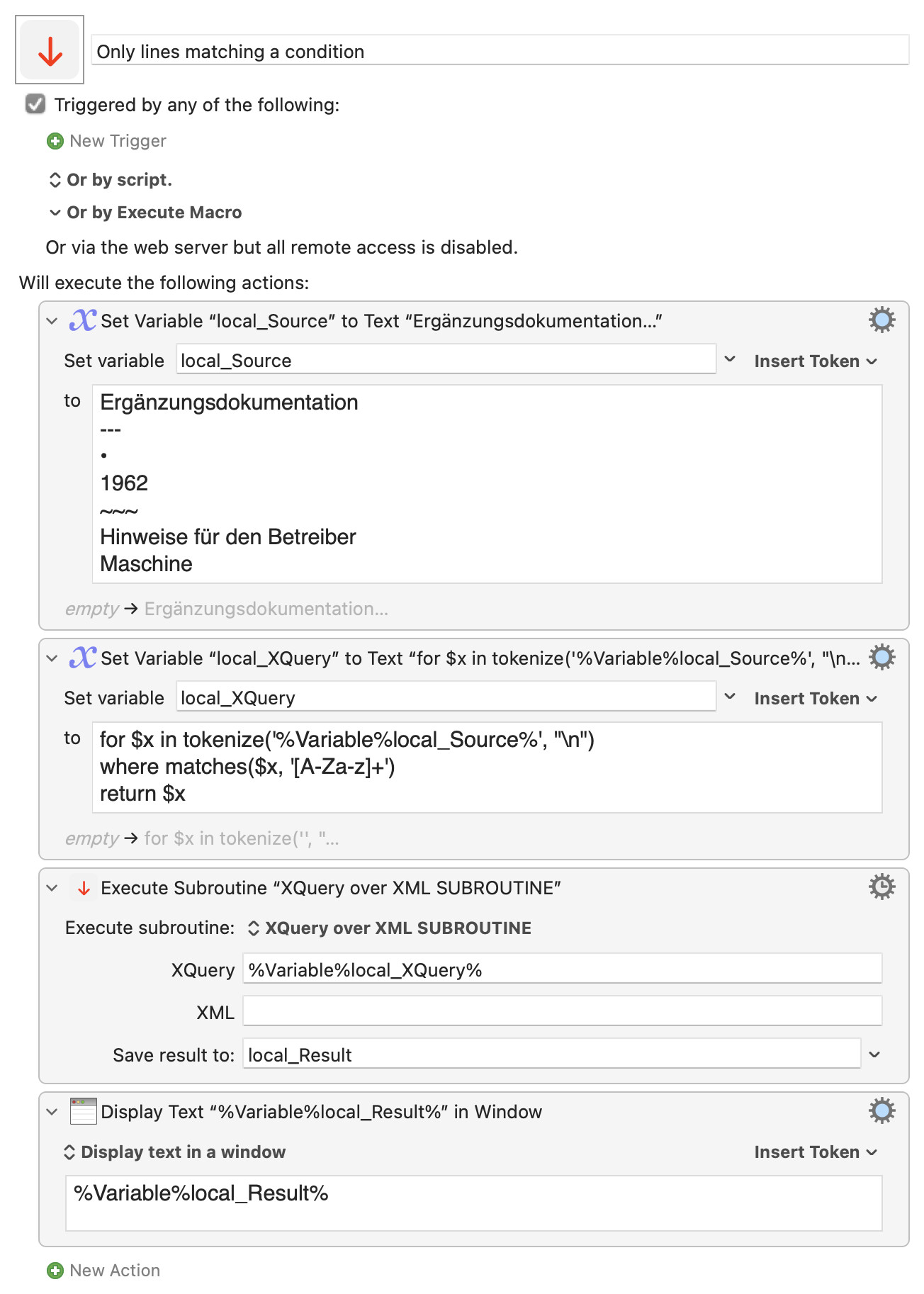
For example, assuming this subroutine (Ver 0.4, which allows use with no XML):
XQuery over XML SUBROUTINE.kmmacros.zip (2,6 Ko)
for $x in tokenize('%Variable%local_Source%', "\n")
where matches($x, '[A-Za-z]+')
return $x
as in:
Yes, in this particular case.
But my point was that this is a reasonably common general problem which can be solved by either "keeping what you want" or "deleting what you don't want". And you can do either using relatively simple patterns, especially once you get away from the "must do it in a single action" mindset.
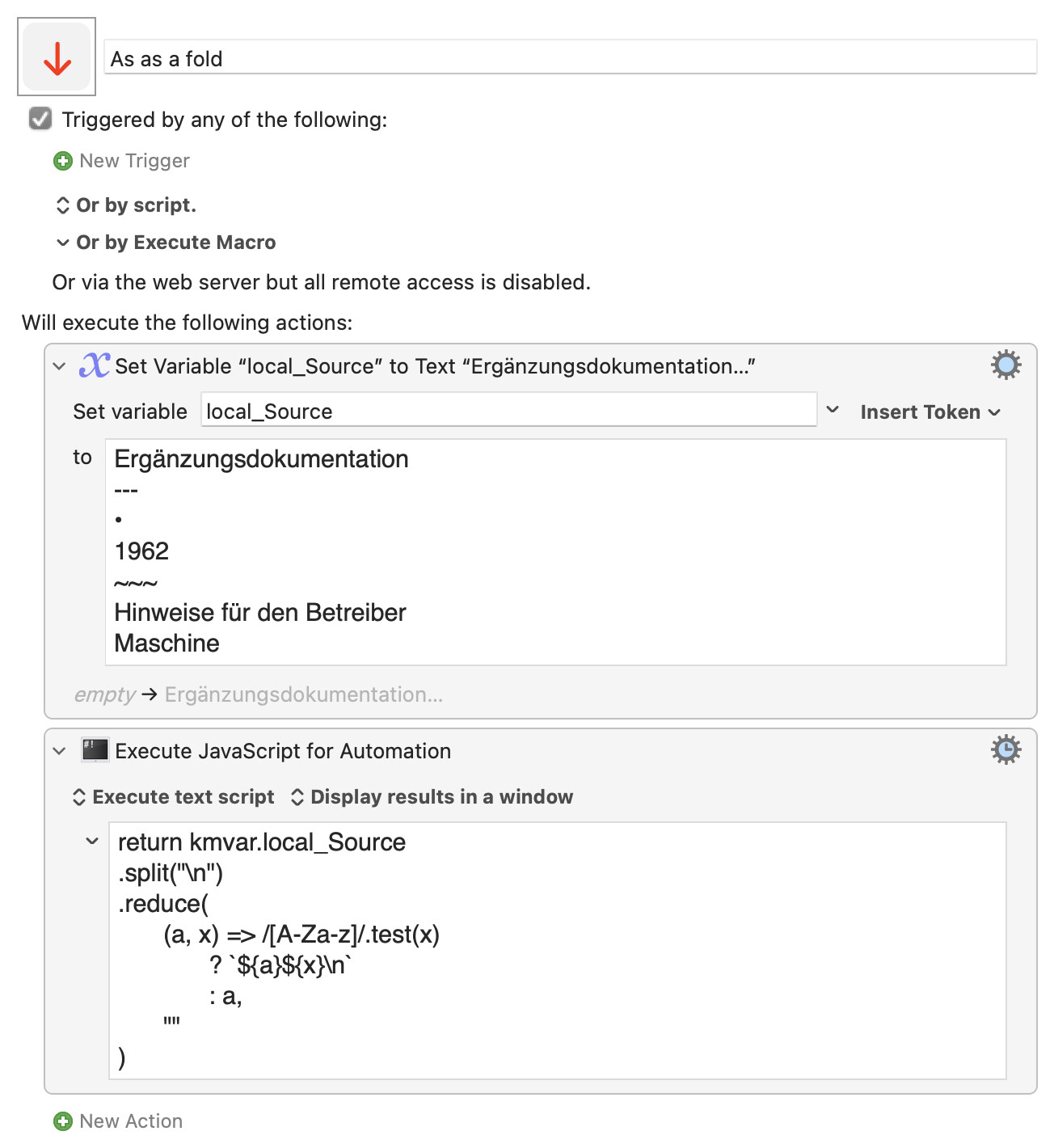
Always, in the last analysis, I guess, a decomposition and conditional reassembly – some derivative of an underlying fold / 'catamorphism':
In JS terms, perhaps:
return kmvar.local_Source
.split("\n")
.reduce(
(a, x) => /[A-Za-z]/.test(x)
? `${a}${x}\n`
: a,
""
)
The universality and expressiveness of fold
As as a fold.kmmacros (2.3 KB)
Incidentally, to cover alphabetics with diacritics, just in case you ever have a lexical entry in which all characters have accents
(the FR word à, for example ?)
you could extend the pattern from [A-Za-z] to [A-Za-z\u00C0-\u00FF]
as in:
// isAlpha :: String -> Bool
const isAlpha = c =>
(/[A-Za-z\u00C0-\u00FF]/u).test(c);
or, where supported (not everywhere):
\p{L}
// isAlpha :: String -> Bool
const isAlpha = c =>
(/\p{L}/u).test(c);
And in KM I think (I don't deal with accents etc often) you can use the Letter Unicode category. So for the S'nR deletion method, excluding numbers this time:
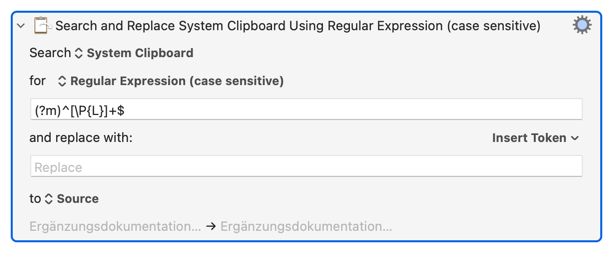
(?m)^[\P{L}]+$ -- "any line that is entirely non-Letter category characters". [\p{L}] is "match a Letter category character, using the uppercase \P is the negation.
Not quite as easy in the shell script "accumulation" version because (again -- I think this is the case!) macOS's POSIX.1 standard egrep doesn't support Unicode Categories. But you can go the other way and look for anything that isn't a number or "punctuation", using POSIX character classes:
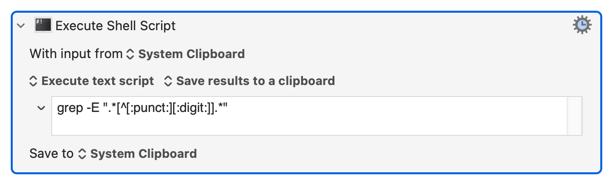
grep -E ".*[^[:punct:][:digit:]].*"
Digging into this makes me realise how much I don't know about it!
Stepping back to the original CafeTran XML context from which this arose, I was pleasantly surprised to find that the XQuery 1.0 built into macOS, despite its relative antiquity, does recognise \p{L}.
So over the full XML file, for all the de-DE segments (within the translation unit variant – <tuv>) texts, excluding the purely numeric lines:
//tuv[@xml:lang='de-DE']/seg/text()[matches(., '\p{L}')]
I still only see alternative solutions to the aspect that the original post said had already been solved. Oh well. I'll just check whether I have been confusing bold text and strikethrough over the years.
Yes -- but the original solution was based on "For Each". Nice and simple, and fine for a short block of text -- but it'll start to grind if there are a lot of lines. Global S'n'Rs will be much quicker for large text blocks, though possibly less understandable at a glance. And @ComplexPoint's latest is the best solution of all for this specific problem -- get only the data you want in the first place!
Yes, I certainly did not lack respect for the quality of the alternative solutions! My reply there was lighthearted (I laughed, anyway!) but I truly had wondered for a while whether I had missed a nuance related to the section in strongly emphasised text. However, it seems that the discussion had simply grown from there. ![]() Thanks.
Thanks.
Just responses, I think, to an interesting observation by the OP:
When shorter lists are derived from longer ones, do we think of this as:
My take is that the question arises from a tradition of thinking about data as mutable – something like clay – as if we reshape it, pulling bits off, or sticking new bits onto it, as if working it with our hands.
Another tradition is to drop mutability (and variables) prefering constants, maps, folds and filters – in these terms we are always defining a new value in relation to an an old one, rather than re-working the old one into a different shape.
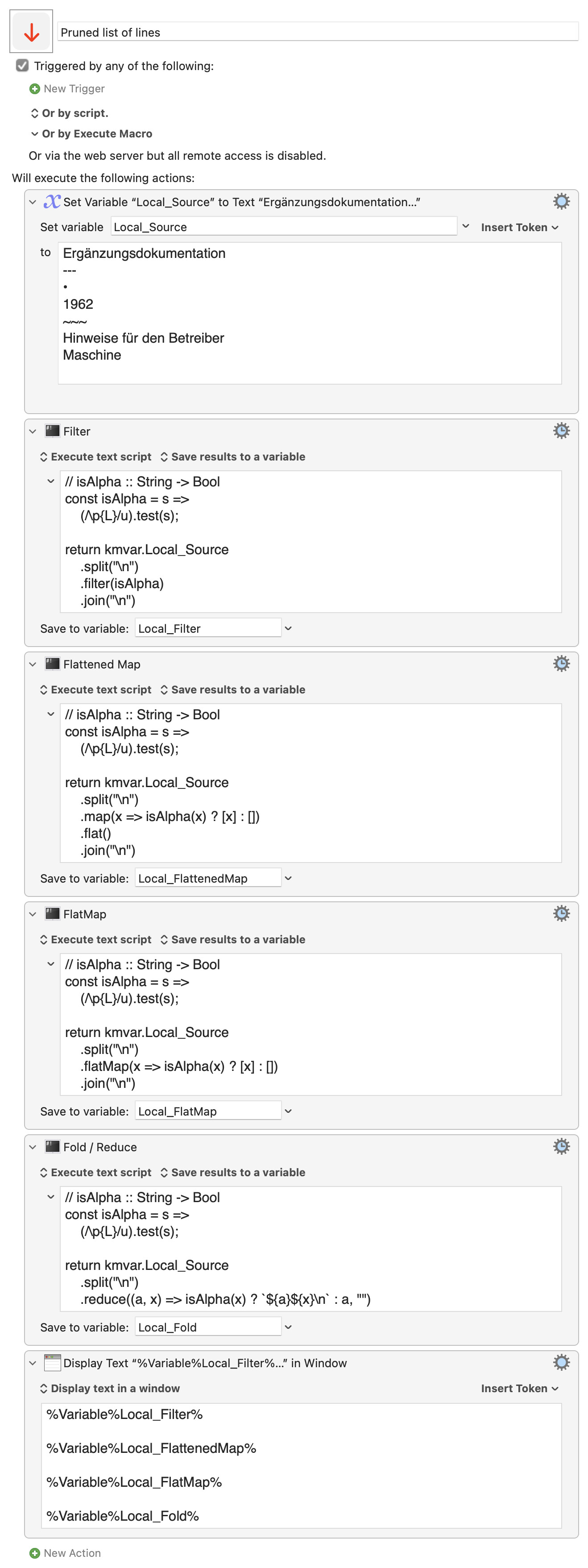
Given a predicate like isAlpha
// isAlpha :: String -> Bool
const isAlpha = s =>
(/\p{L}/u).test(s);
We could define the pruned list of lines as a
return kmvar.Local_Source
.split("\n")
.filter(isAlpha)
.join("\n")
return kmvar.Local_Source
.split("\n")
.map(x => isAlpha(x) ? [x] : [])
.flat()
.join("\n")
return kmvar.Local_Source
.split("\n")
.flatMap(x => isAlpha(x) ? [x] : [])
.join("\n")
return kmvar.Local_Source
.split("\n")
.reduce((a, x) => isAlpha(x) ? `${a}${x}\n` : a, "")
Pruned list of lines.kmmacros (6.9 KB)